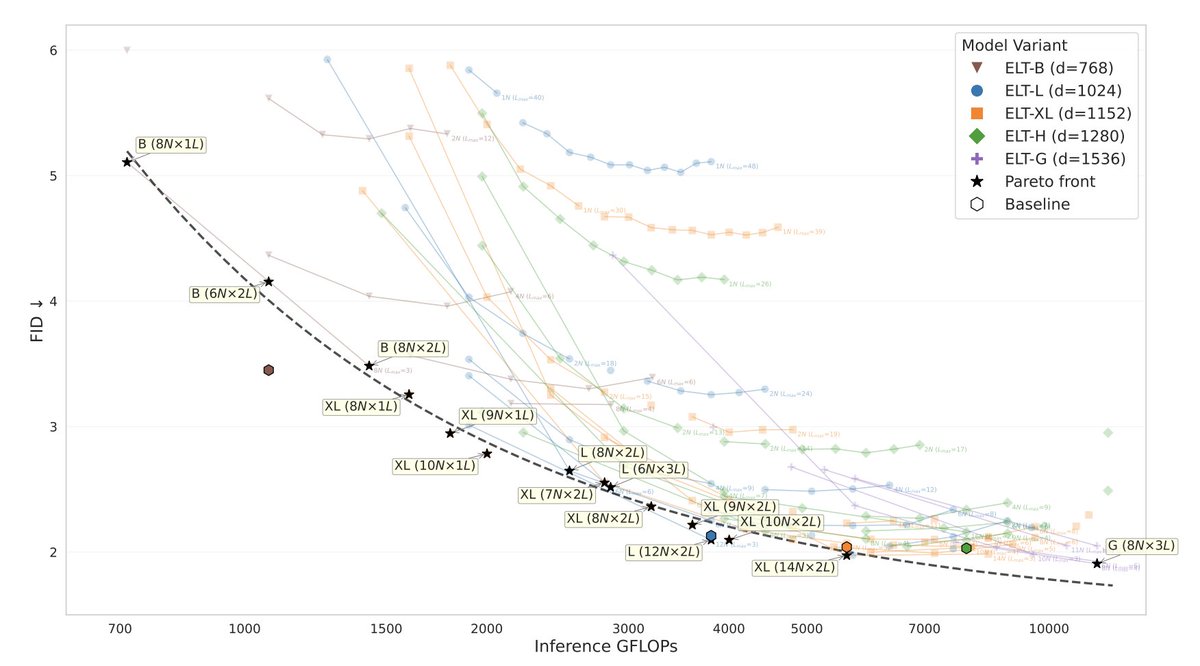
English
Tarun Raheja
6.1K posts

@atemyipod
AI/Robotics investing @accel | Prev - UPenn, MSFT Research, JPM Quant, @bitspilaniindia | Opinions my own, not employer's




Training LLMs is synonymous with updating their weights. However, LLMs can also learn in-context using *frozen* weights. There is no good reason for restricting learning to being in-context or in-weights. So a natural idea is "Learning, Fast and Slow" (FST). In FST, slow learning is LLM weights trained with RL while fast learning is context / prompt (fast weights) optimized with GEPA. Compared to RL, FST performs better while being more data efficient, adaptable (plasticity), and forgetting less (stays closer to base models). I think this idea of learning both fast-slow weights would be a good foundation for continual learning. PS: Geoff Hinton (the OG) described the idea of fast weights and slow weights several years ago, and back then I remember thinking it's a very cool idea. See more details here: gepa-ai.github.io/gepa/blog/2026…