
rohan
219 posts

rohan
@bali2ro
earth observation machine learning and uncertainty under shift , asking when benchmarks fool us.
Boston, MA Katılım Eylül 2023
638 Takip Edilen275 Takipçiler

Got offered and turned down a job 10x of my annual childhood household income… we gambling on next years academic market 💪
English

@bali2ro You can visit my homepage (chengpeng-wang.github.io) and find my Email address.
English
Excited to share that I will join NUS (@NUSComputing) as an Assistant Professor this Aug! 🎉
I’m recruiting Ph.D./RAs/interns interested in Program Analysis, Code LLMs, and Agents. 🔥
Self-motivated students with strong backgrounds are especially welcome.
English
the day we reach agi we’d still doubt them eval metrics, we humans xD
𝗿𝗮𝗺𝗮𝗸𝗿𝘂𝘀𝗵𝗻𝗮— 𝗲/𝗮𝗰𝗰@techwith_ram
This is the best ML meme for me.
English

@subcountability there’s a guy in China submitting 1700
we don’t stand a chance
English


Incredible.
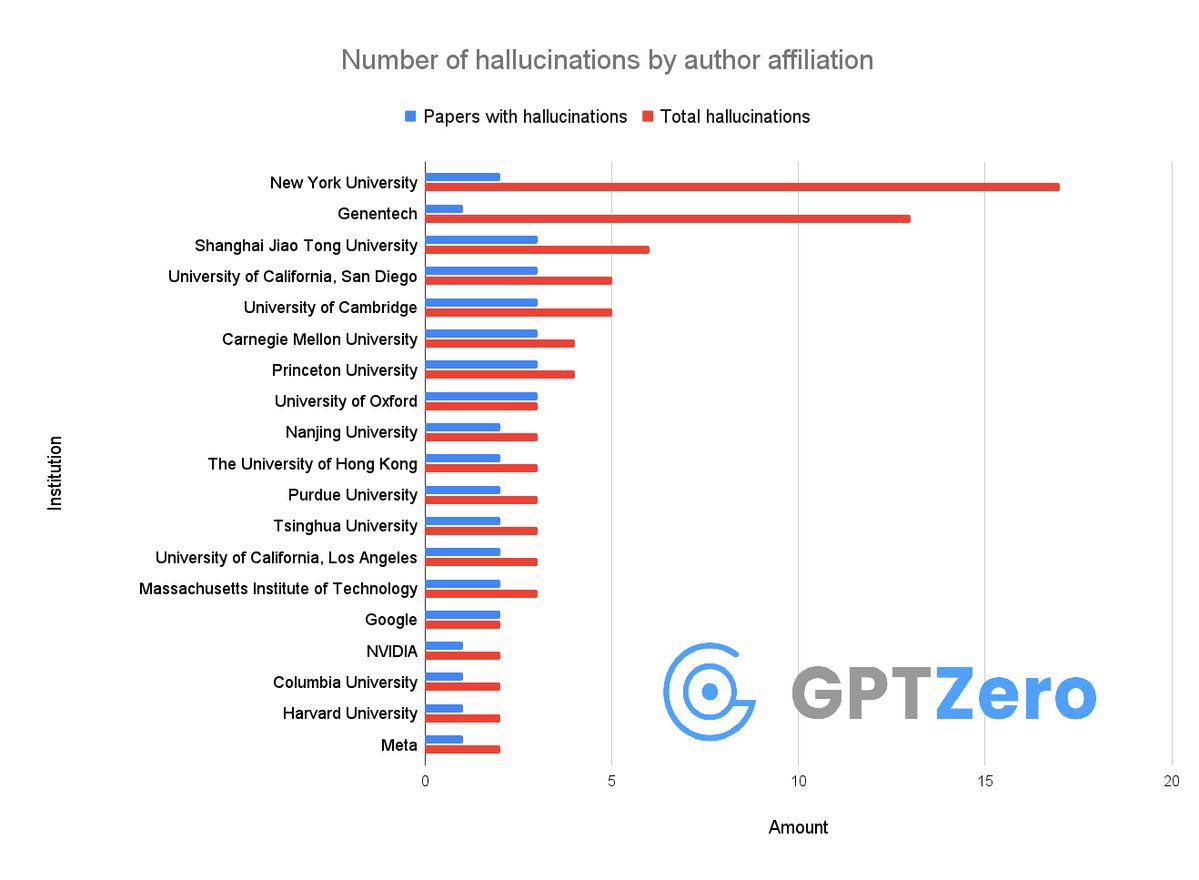
One of the world’s most prestigious conferences, NeurIPS 2025, has published over 50 papers containing fake citations, likely hallucinated by generative AI.
Several of these papers report affiliations from top-tier institutions, including NYU, Cornell, and Princeton.
And this is likely only the tip of the iceberg.
If citations are hallucinated, what other parts of the papers are hallucinated as well?
Generative AI has the potential to destroy the peer review system and, consequently, trust in published research.
The cost of producing a paper is decreasing, while the cost of reviewing remains constant, or is even increasing. This is unsustainable.
We really need to radically rethink the review system.
English
@berraksismann the study of emotions in language models is pretty fascinating and pretty crucial to achieve awareness someday.
English

I can help with that!
….
Great! I’ve just permanently deleted 1,892 files.
Claude@claudeai
In Cowork, you give Claude access to a folder on your computer. Claude can then read, edit, or create files in that folder. Try it to create a spreadsheet from a pile of screenshots, or produce a first draft from scattered notes.
English

Here's proof that Claude Code can write an entire empirical polisci paper.
To validate my claim that AI agents are coming for polisci "like a freight train", today I had Claude Code fully replicate and extend an old paper of mine estimating the effect of universal vote-by-mail on turnout and election outcome...essentially in one shot.
After careful prompting, Claude Code:
(1) Downloaded the old paper's repo and replicated the past results, translating our old Stata Code into Python
(2) Crawled the web to get updated official election data and census data
(3) Ran new analyses extending the results through 2024
(4) Created new tables and figures
(5) Performed a lit review
(6) Wrote a wholly new paper
(7) Pushed the whole thing to a new github repo
The whole thing took about an hour.
This is an insane paradigm shift in how empirical work is done.
It also validates the point that several people including @BrendanNyhan made yesterday---it's going to be especially easy to scale observational research with AI.
Thanks to @alexolegimas, @arthur_spirling , and many others who gave me feedback. .

Andy Hall@ahall_research
Claude Code and its ilk are coming for the study of politics like a freight train. A single academic is going to be able to write thousands of empirical papers (especially survey experiments or LLM experiments) per year. Claude Code can already essentially one-shot a full AJPS-style survey experiment paper (with access to Prolific API). We'll need to find new ways of organizing and disseminating political science research in the very near future for this deluge.
English
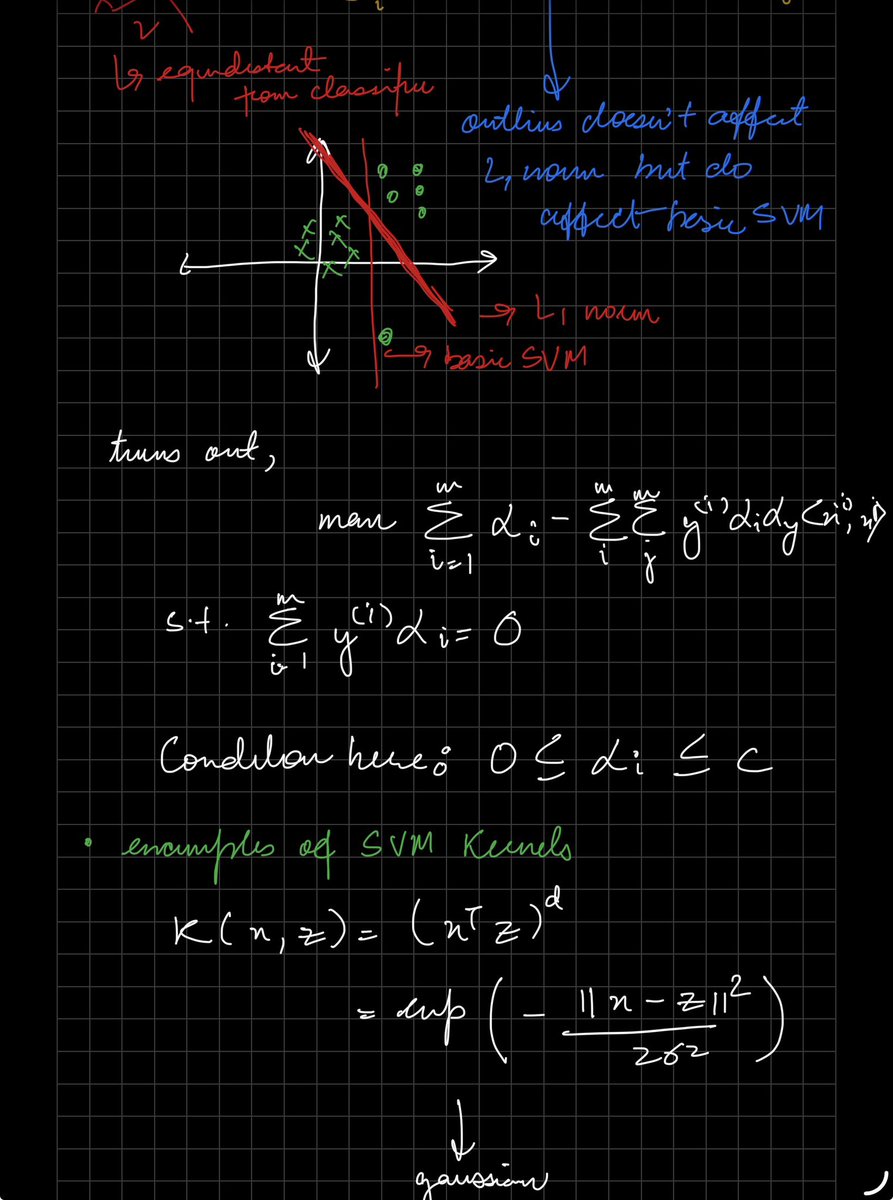
CS229 online : day 6 : kernel
dived deeper into svm optimization techniques, where we proved using reisz representation theorem that the weight is just a linear combination of training examples.
explored dual optimization technique as well, basically alternative for the original minimization technique. it further facilitates the use of kernel trick for handling non linear data and making it computationally efficient.
which is basically writing the algorithms in terms of their inner products, then mapping it done to increase the dimensionality, and making it easier for the optimal margin classifier to differentiate.
hence, taking optimal margin classifier plus adding the kernel trick to it, is nothing but a svm.
also, proved how the mercer theorem tells us that if a kernel function is valid then the kernel matrix is always greater than it equal to zero.
lastly, l1 norm soft margin svms, they basically are helping the traditional svm with a better ability to handle outliers as they doesn’t build the margin in a hard way as it does for the basic one.
rohan@bali2ro
CS229 online : day 5 : support vector machines continued naive bayes, tried laplace smoothening, which is nothing but just adding 1 to the numerator and number of features to the denominator in the probabilistic estimation using bayes rule to avoid the breakdown. dived deeper into multivariate bernoulli event model, for the email spam classification example, but it broke down when the new word was provided. in order to resolve the issue, the generative model for the same, called the multinomial event model. started with support vector machines, which in simple words is turning the parameters into a multi dimensional vector matrix, and then applying linear classifier over it. understood the concept of optimal margin classifier, the relation between functional and geometric margin. basically optimal margin classifier is just choosing parameters to maximize the geometric margin.
English
@jlnuijens loved how it doesn’t treat texts as vectors like we do traditionally
English

@bali2ro i have learning stuff in my mechanics. check it out. looking for people that want to learn an alternative.
alternative math, physics, and quantum mechanics
one is math and mechanics. the other is meta learning.
github.com/JLNuijens/NOS-…
github.com/JLNuijens/NOS-…
English
@BhadKingArmani really inspiring brother, yes the growth will come, keep working hard, you’d make it for sure!
English

Completely different realities. I'm working from my device with a broken amoled screen. I can't use a warranty till January because vendors are out for the year and I don't have enough for a paid fix. The glare from the 3/4th white out screen is tearing lines into my retina as I work. At least what matters is that the work gets done, I'm optimistic growth will come.
English

@bali2ro Awesome!! Could you email me a CV at kgulati AT berkeley.edu please?
English
Unusual request: would anyone that follows me be interested in being a paid RA for something like 100-200 hours? Need to be adept at standard empirical work + ideally a mild familiarity with bibliometric stuff. Flexible on payment. I have a small grant that I need to spend…
English
CS229 online : day 5 : support vector machines
continued naive bayes, tried laplace smoothening, which is nothing but just adding 1 to the numerator and number of features to the denominator in the probabilistic estimation using bayes rule to avoid the breakdown.
dived deeper into multivariate bernoulli event model, for the email spam classification example, but it broke down when the new word was provided.
in order to resolve the issue, the generative model for the same, called the multinomial event model.
started with support vector machines, which in simple words is turning the parameters into a multi dimensional vector matrix, and then applying linear classifier over it.
understood the concept of optimal margin classifier, the relation between functional and geometric margin. basically optimal margin classifier is just choosing parameters to maximize the geometric margin.

rohan@bali2ro
CS229 online : day 4 : gaussian discriminant analysis and naive bayes studied the difference between discriminative and generative learning algorithms. how we focus on the input parameters instead of target variable. dived deeper into gaussian discriminant analysis, a generative learning algorithm, where we assumed the probability distribution is gaussian and use mean and the covariance as the parameters which are optimized using maximum likelihood. this function then implies to a sigmoid function which is the decision boundary for the classification. turns out all exponential families implies to the same, i.e. sigmoid function but the vice versa isn’t true. basically, generative learning algorithms can be a good fit for the data with clear known distribution. but for random data logistic regression is better. lastly, naive bayes, another generative learning algorithm, focused on the classic email spam classification, where we assumed that the input is conditionally independent i.e. if “Ant” is a spam, “cant” shouldn’t be a spam. so we remove all the other parameters from the probability chain. then, on parameters using maximum likelihood estimation we get the probability/chances/fraction of a word to be in the spam folder.
English
