@InterstellarUAP @PeterMcCormack Already wrong. They are waves AND particles at the same time. There are some operators which are compatible and some which are not. And impuls and position is not.
English
Jannis
2.5K posts


Life after an RTX 3090 > Life before an RTX 3090 Buy a GPU


The inference stack just got simpler. PagedAttention, the kernel that made vLLM fast, now ships natively in 🤗 Transformers CB. Result: 84% of vLLM throughput on a single GPU. Near SOTA with no extra runtime. The gap is closing 📈






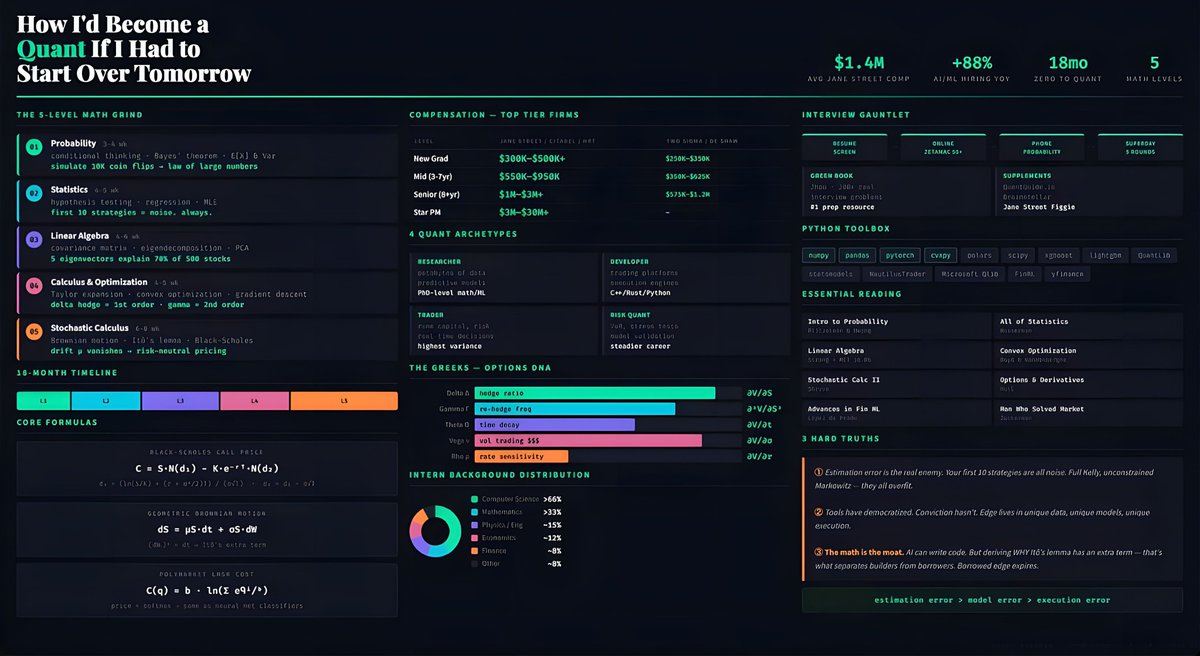








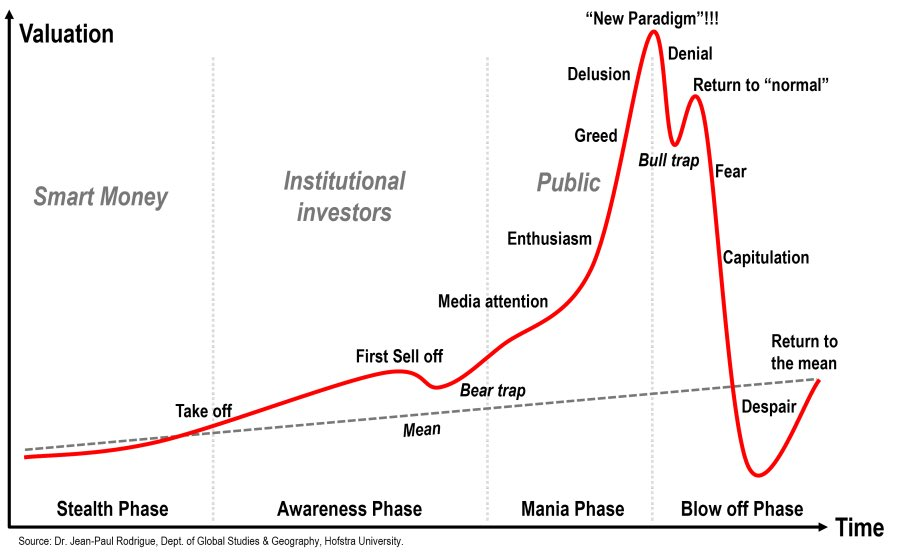
Hope everyone enjoys their last year of meaningful work!


You could get a job at the Littleton Coin Company and buy this house just off Main Street. Then meet a nice girl at St. Rose of Lima and take her on a date to Schilling Beer Company. Get married and send your kids to Above The Notch Community School. But you will not.