
Darío Robaina Suárez
1K posts

Darío Robaina Suárez
@bazooka_97
Ingeniero Informático | Real Madrid👑 | Games🎮 ~ Sports⚽️ ~ Pizza 🍕
Katılım Eylül 2020
459 Takip Edilen45 Takipçiler

We've got a Welcome to Talandre Giveaway 👀
20 winners will receive codes w/ fully upgraded Rare-quality Tier 2 Gear. Reply with a 🏹 to enter!

English
Darío Robaina Suárez retweetledi

BEAST GAME EPISODE 3 IS OUT NOW!
To celebrate, I'm giving away $100,000 total to 10 random people who like and retweet this post!
Go watch it here: amazon.com/beastgames
English
Darío Robaina Suárez retweetledi

¿Por qué mucha gente le tiene miedo a Java como lenguaje de programacion?
- Porque no tiene el nivel que se requiere para dominarlo.
Buenos días.
Español
Darío Robaina Suárez retweetledi

Explicación visual de una consulta SQL
Te explico paso a paso:
SELECT: Especifica las columnas que se desean recuperar de la base de datos. En este caso, column_a y column_b son las columnas seleccionadas para la salida.
FROM: Indica la tabla de la que se van a seleccionar los datos. Aquí, t1 es la tabla de origen.
JOIN: Se utiliza para combinar filas de dos o más tablas, basadas en una columna relacionada entre ellas. En el ejemplo, t2 es la tabla que se une con t1.
ON: Define la condición de unión entre las dos tablas. La consulta muestra que t1.column_a debe ser igual a t2.column_a, lo que significa que la unión se hace en base a la coincidencia de valores en column_a de ambas tablas.
WHERE: Es una cláusula que se utiliza para filtrar registros que cumplen una condición específica. constraint_expression sería una expresión que define esta condición.
GROUP BY: Agrupa las filas que tienen los mismos valores en la columna especificada, lo que permite realizar operaciones de agregación como contar, sumar, promediar, etc.
HAVING: Es similar a WHERE, pero se aplica a grupos de filas creados por GROUP BY. constraint_expression indica la condición que deben cumplir los grupos.
ORDER BY: Organiza los resultados según el valor de una o más columnas, en orden ascendente (ASC) o descendente (DESC).
LIMIT: Limita el número de registros que la consulta retorna, lo que es útil cuando solo se necesita una cierta cantidad de filas. count indica el número máximo de registros a retornar.
Como ves, la consulta se escribe de una forma pero el orden de ejecución es otro:
1. Usa FROM y JOIN para determinar de dónde se extrae la información.
2.Con ON y WHERE, se utilizan expresiones para filtrar los resultados.
3. Agrupar con GROUP BY y filtrar con HAVING, se seleccionan los campos.
4. Se ordenan y limitan los resultados.
¡Espero que te haya servido el diagrama y las explicaciones para aprender y entender SQL!

Español
Darío Robaina Suárez retweetledi
¡Esta biblioteca de JavaScript es brutal!
Transforma elementos en cajas que puedes arrastrar.
Intercambiando posiciones con otros elementos.
Funciona en React, Vue, Angular, Svelte...
> npm install swapy
Español
Darío Robaina Suárez retweetledi
¿Quieres revisar si tu CV es ideal? ¡Ojo a este recurso!
Se llama ResumeGO y usa IA para darte:
✓ Una puntuación general
✓ Consejos para mejorar el CV
✓ Ideas de contenido que puede faltar
✓ Indicaciones para que sea legible por sistemas ATS
→ resumego.net/resume-checker/
Español
Darío Robaina Suárez retweetledi

Guy with zero flying experience simulates emergency landing
English
Darío Robaina Suárez retweetledi

Comunicado oficial: Mbappé.
#RealMadrid
Português
Darío Robaina Suárez retweetledi
Hoja de referencia de SQL desde cero
Una chuleta en PDF con todo lo que necesitas
→ learnsql.com/blog/sql-basic…
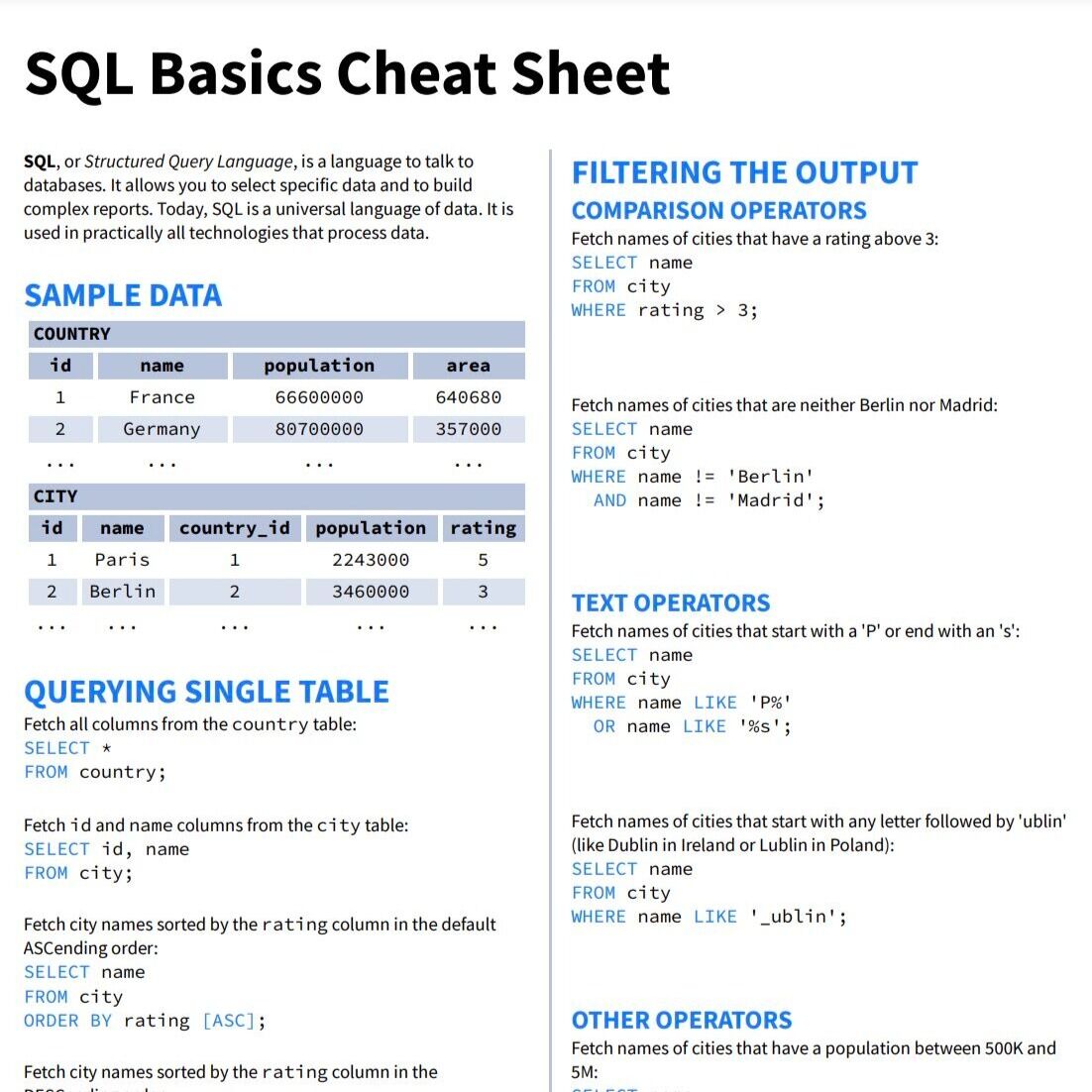

Español
Darío Robaina Suárez retweetledi
¡Herramienta TOP para revisar la Web Performance!
Te da las métricas más importantes de tu web
✓ Puntuación de SEO
✓ Te avisa de errores en tu página
✓ Crea reportes y gráficas de las peticiones
Es gratuita: → gtmetrix.com
Español
Darío Robaina Suárez retweetledi
Patrones de Arquitectura que debes conocer ↓
1. Arquitectura Orientada a Eventos
Los componentes del sistema se comunican entre sí mediante eventos. Los productores de eventos generan datos y los envían a un intermediario, quien luego los distribuye a los consumidores de eventos interesados.
Ventajas: Escalable y desacoplado
Desventajas: Difícil de depurar y puede haber latencia
Se usa: Para eventos en tiempo real o aplicaciones grandes que deben sincronizarse frecuentemente
2. Arquitectura por Capas
Organiza el sistema en capas jerárquicas, cada una con una responsabilidad específica como presentación, lógica de negocio y acceso a datos.
Ventajas: Fácil de mantener y reutilizar
Desventajas: Puede afectar el rendimiento y ser rígido
Se usa: En aplicaciones empresariales con reglas de negocio complejas
3. Monolito
Todo el sistema está integrado en una sola aplicación grande donde todos los componentes están interconectados.
Ventajas: Fácil de desarrollar inicialmente y buen rendimiento
Desventajas: Difícil de escalar y mantener a largo plazo
Se usa: En aplicaciones más simples que no requieren escalabilidad avanzada
4. Microservicios
El sistema se divide en pequeños servicios independientes que se comunican a través de API.
Ventajas: Altamente escalable y flexible
Desventajas: Más complejo de gestionar y puede aumentar la latencia
Se usa: En aplicaciones grandes y complejas que requieren despliegue independiente
5. MVC (Modelo-Vista-Controlador)
Patrón que divide la aplicación en Modelo (datos y lógica), Vista (interfaz de usuario) y Controlador (manejo de la entrada del usuario).
Ventajas: Facilita la gestión y la reutilización
Desventajas: Añade complejidad y puede generar sobrecarga
Se usa: En frontend (web y móvil) para separar la lógica de negocio de la interfaz de usuario
6. Arquitectura Maestro-Esclavo
Un servidor maestro maneja las operaciones de escritura, mientras que los servidores esclavos manejan las operaciones de lectura.
Ventajas: Mejora el rendimiento y la disponibilidad
Desventajas: Problemas de consistencia y mayor complejidad
Se usa: Para bases de datos a gran escala que requieren balanceo de carga
GIF
Español
Darío Robaina Suárez retweetledi
Desarrolla hasta 5 veces más rápido Páginas Web
¡Herramienta MUST HAVE para Frontend y UX!
✓ Muestra la misma página en diferentes dispositivos
✓ Utilidades de accesibilidad y diseño
✓ Sincroniza eventos en todos
✓ Gratis y de código abierto
→ responsively.app
Español
Darío Robaina Suárez retweetledi
¿Sabías que puedes hacer timeout en fetch?
Nativo, sin dependencias y así de fácil:
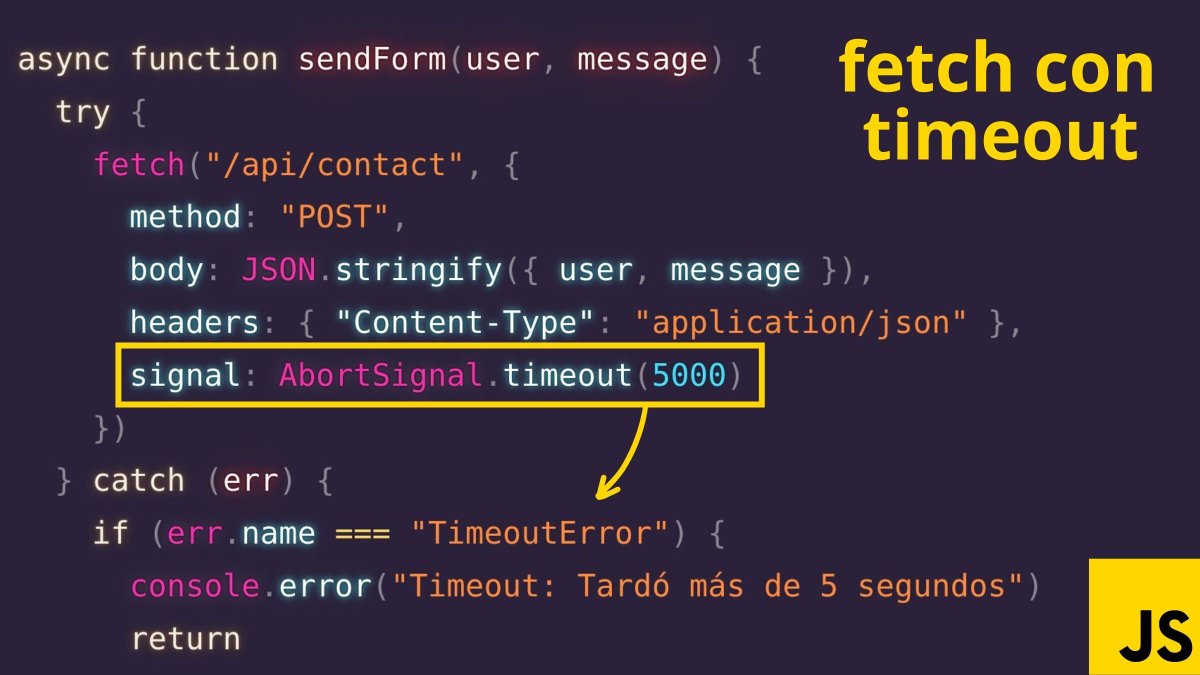
Español
Darío Robaina Suárez retweetledi
¡Aprende TypeScript con retos interactivos!
La página es gratuita y ofrece:
✓ +100 retos de programación
✓ Niveles de principiante a experto
✓ Explicaciones y soluciones de cada uno
✓ Ejercicios interactivos para ponerte a prueba
→ typehero․dev
Español
Darío Robaina Suárez retweetledi
¡Este juego está hecho sólo con CSS! 🤯
0 JavaScript. ¡Con colisiones y controles!
Con soporte para móvil y swipe ↓
Español
Darío Robaina Suárez retweetledi

Los 9 patrones arquitectónicos principales para el flujo de datos y comunicación.
Otra maravilla de ByteByteGo.
→ Peer-to-Peer
El patrón Peer-to-Peer implica comunicación directa entre dos componentes sin la necesidad de un coordinador central.
→ API Gateway
Un API Gateway actúa como un único punto de entrada para todas las solicitudes de los clientes a los servicios de backend de una aplicación.
→ Pub-Sub
El patrón Pub-Sub desacopla a los productores de mensajes (publicadores) de los consumidores de mensajes (suscriptores) a través de un intermediario de mensajes.
→ Request-Response
Este es uno de los patrones de integración más fundamentales, donde un cliente envía una solicitud a un servidor y espera una respuesta.
→ Event Sourcing
Event Sourcing implica almacenar los cambios de estado de una aplicación como una secuencia de eventos.
→ ETL
ETL es un patrón de integración de datos utilizado para recopilar datos de múltiples fuentes, transformarlos en un formato estructurado y cargarlos en una base de datos de destino.
→ Batching
Batching implica acumular datos durante un período o hasta alcanzar un cierto umbral antes de procesarlos como un solo grupo.
→ Streaming Processing
El procesamiento de Streaming permite la ingestión, procesamiento y análisis continuos de flujos de datos en tiempo real.
→ Orchestration
La orquestación implica que un coordinador central (un orquestador) gestiona las interacciones entre componentes o servicios distribuidos para lograr un flujo de trabajo o proceso de negocio.
GIF
Español
Darío Robaina Suárez retweetledi

INCREÍBLE 🤩 Ya habéis desbloqueado el nivel 2 en nuestro sorteo #ROGRTXChallenge y hemos añadido una ASUS ROG GeForce RTX 4070 Ti Super a la lista de premios.
¿Quieres participar?
1. Dale like
2. Comenta con #ROGRTXChallenge
¡Comparte el hype y desbloquea más premios!

Español
Darío Robaina Suárez retweetledi
GitHub Copilot gratis una semana sin tarjeta de crédito.
1 - gh.io/copiloto
2 - gh.io/copilot-free

Español
Darío Robaina Suárez retweetledi
9 Mejores Prácticas para construir Microservicios ↓
1. Diseñado para fallar
Prepara el sistema para que se adapte a errores en cualquier nivel
2. Construye Servicios Pequeños
Evita que haga más de una cosa. Mejor que haga una cosa pero bien
3. Usa Protocolos ligeros
Para mejor eficiencia usa REST, gRPC, Message Brokers...
4. Implementa el descubrimiento de servicios
Vital en un sistema distribuido para que se encuentren y se comuniquen
5. Propiedad de los Datos
Cada servicio debe ser el único responsable de gestionar sus datos
6. Usa patrones de resiliencia
Estrategias como reintentos automáticos, almacenamiento en caché de resultados para reducir la carga, y limitación de tasa para evitar sobrecargas
7. Seguridad en todos los niveles
Crucial implementar medidas de seguridad en cada punto del sistema donde los servicios se comunican entre sí, asegurando así la protección de los datos y operaciones
8. Registro centralizado
Monitorización, observalidad y guarda todos los mensajes de sistema
9. Contenedorización
Empaquetar y desplegar microservicios de manera aislada y eficiente, facilitando la gestión de las dependencias y el despliegue en diversos entornos
Y, para terminar, ten en cuenta que no siempre los microservicios son la mejor opción. Aunque tienen muchas ventajas, también añade complejidad a tu infraestructura. No abuses de ellos y úsalos cuando tienen sentido.
Español