Sabitlenmiş Tweet

(1/n)
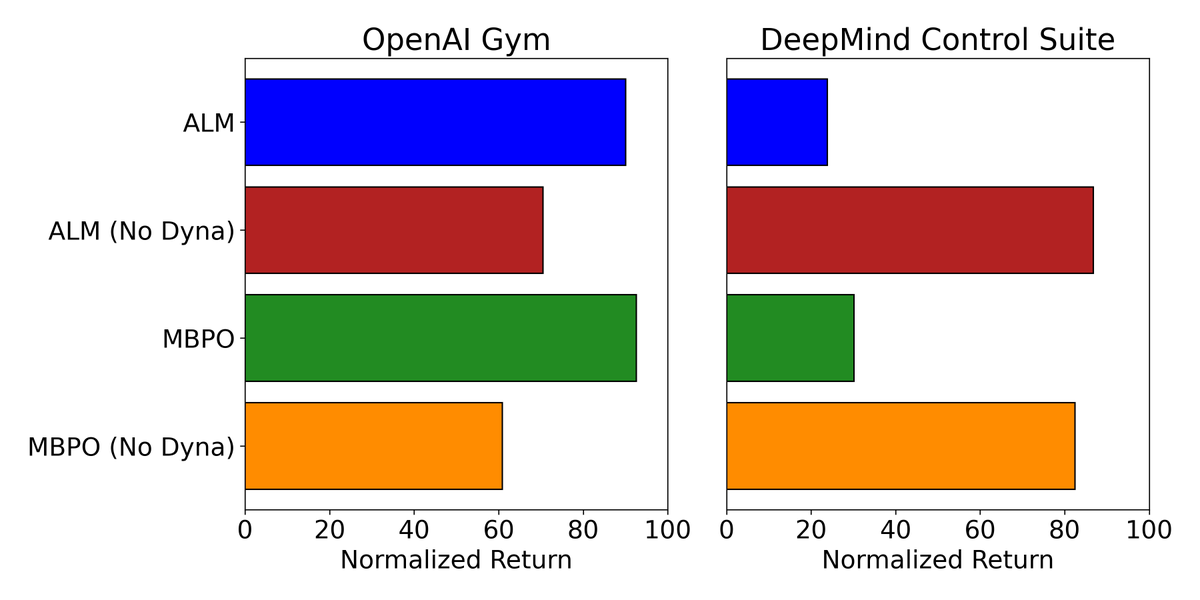
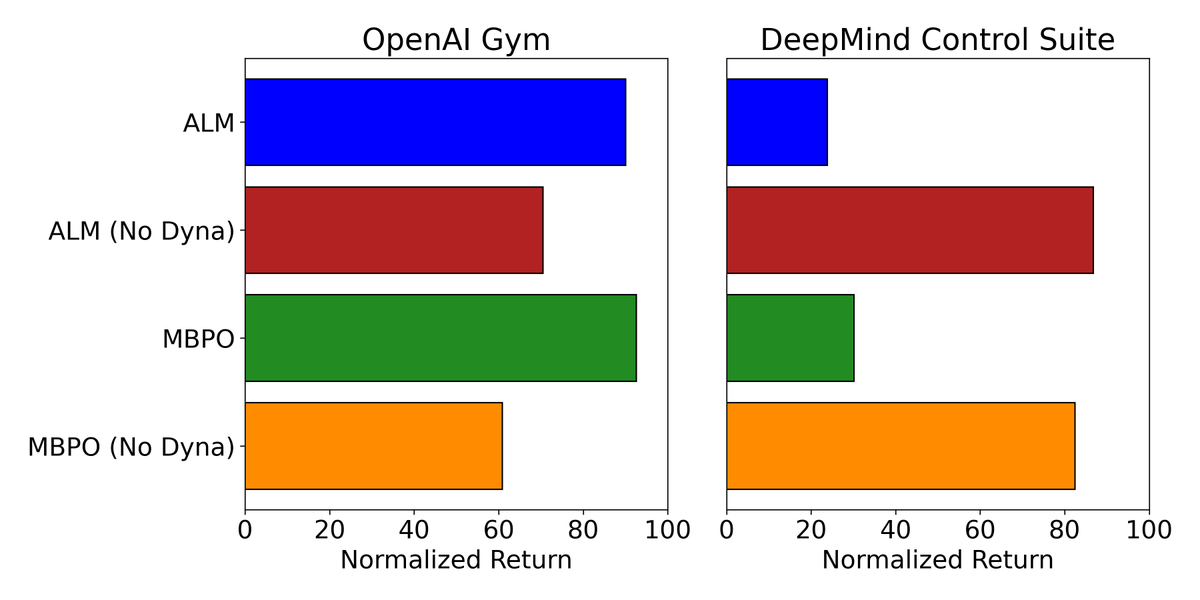
With over 1,300 citations, MBPO is often cited as proof that model based RL beats model free methods. In arxiv.org/pdf/2412.14312 we showed it often completely fails in DeepMind Control. In our new work, Fixing That Free Lunch (FTFL), we explain why and make it succeed.

English