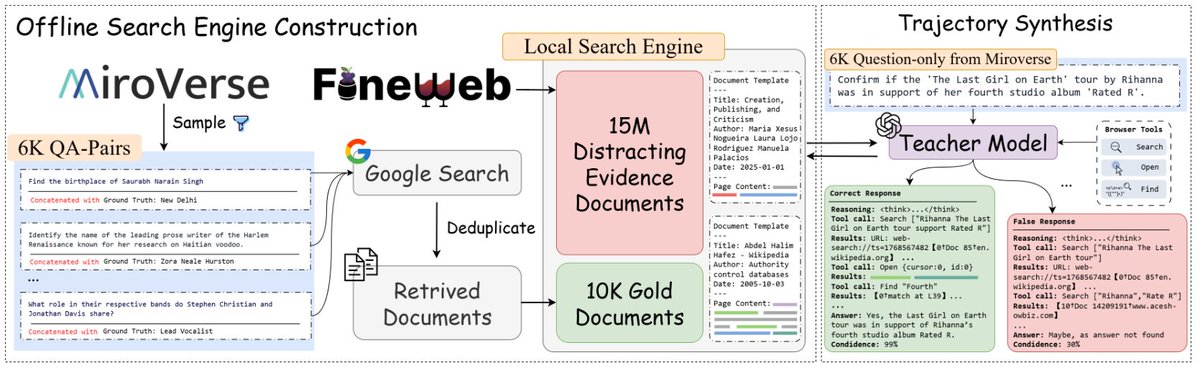
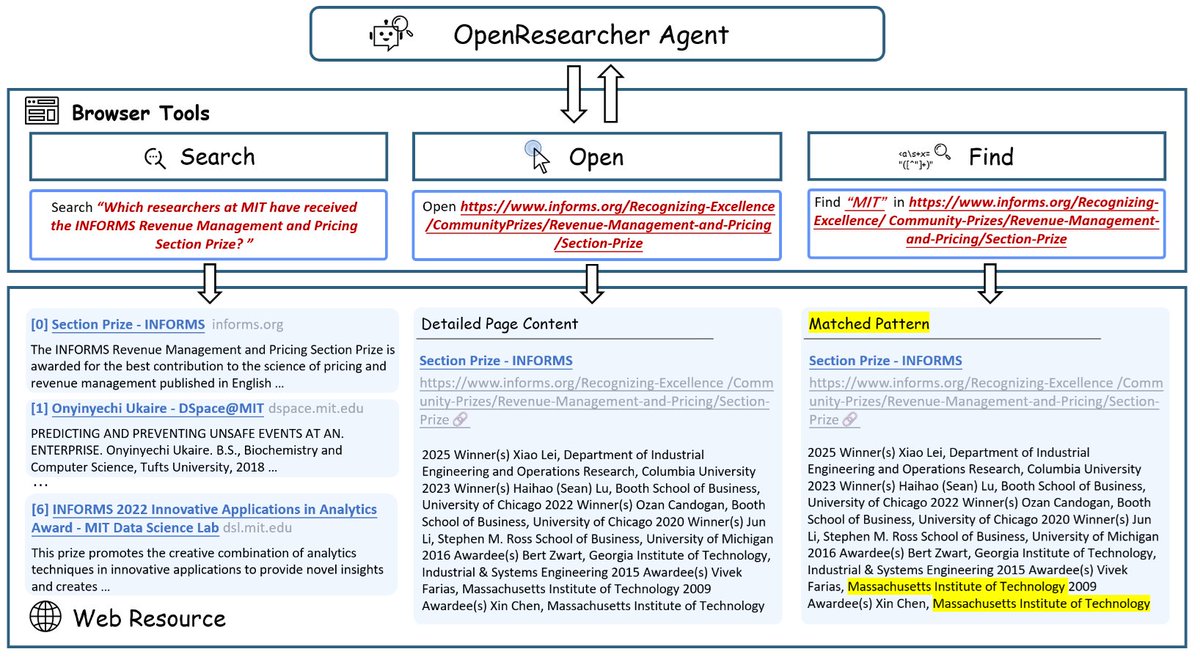
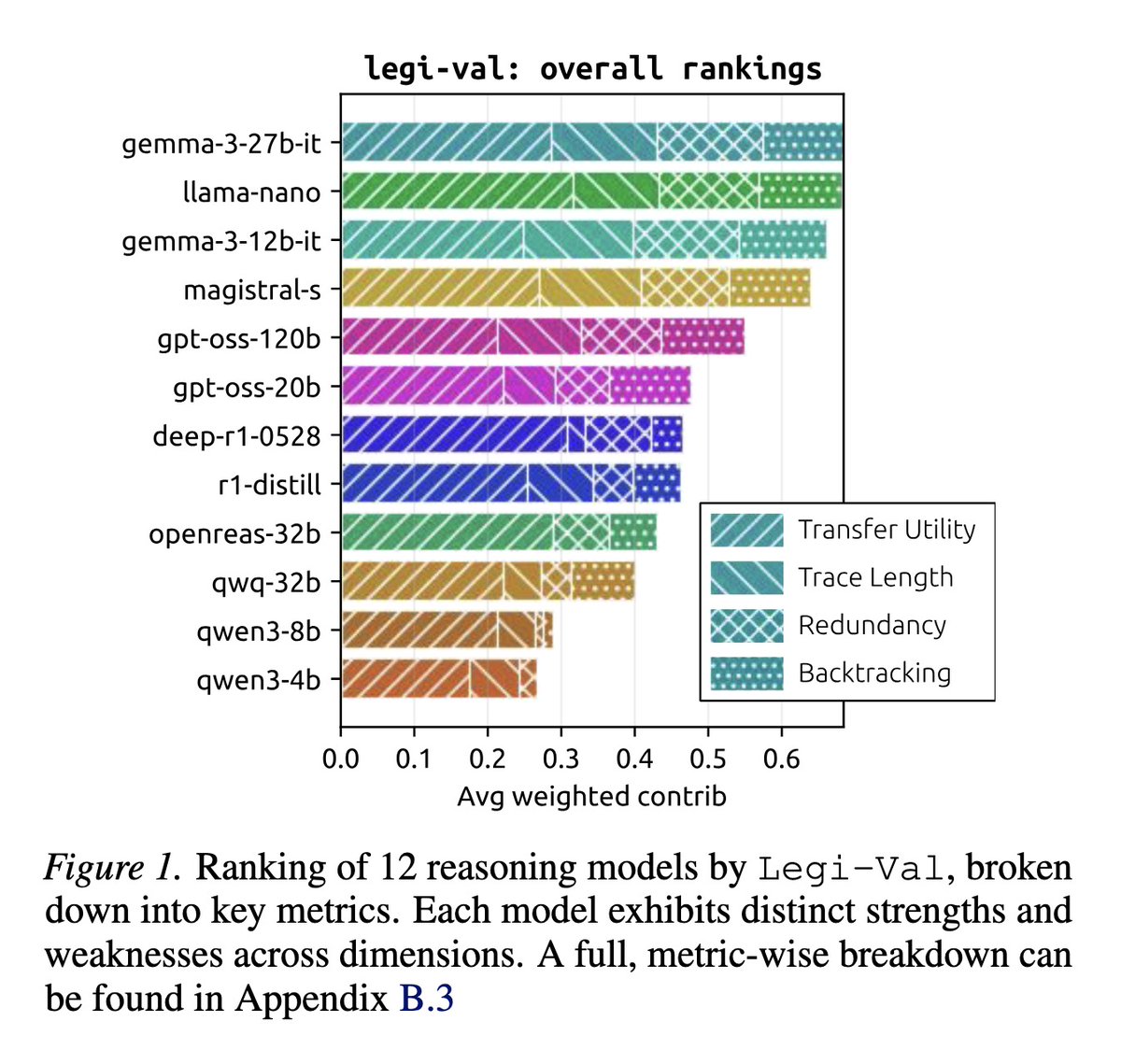
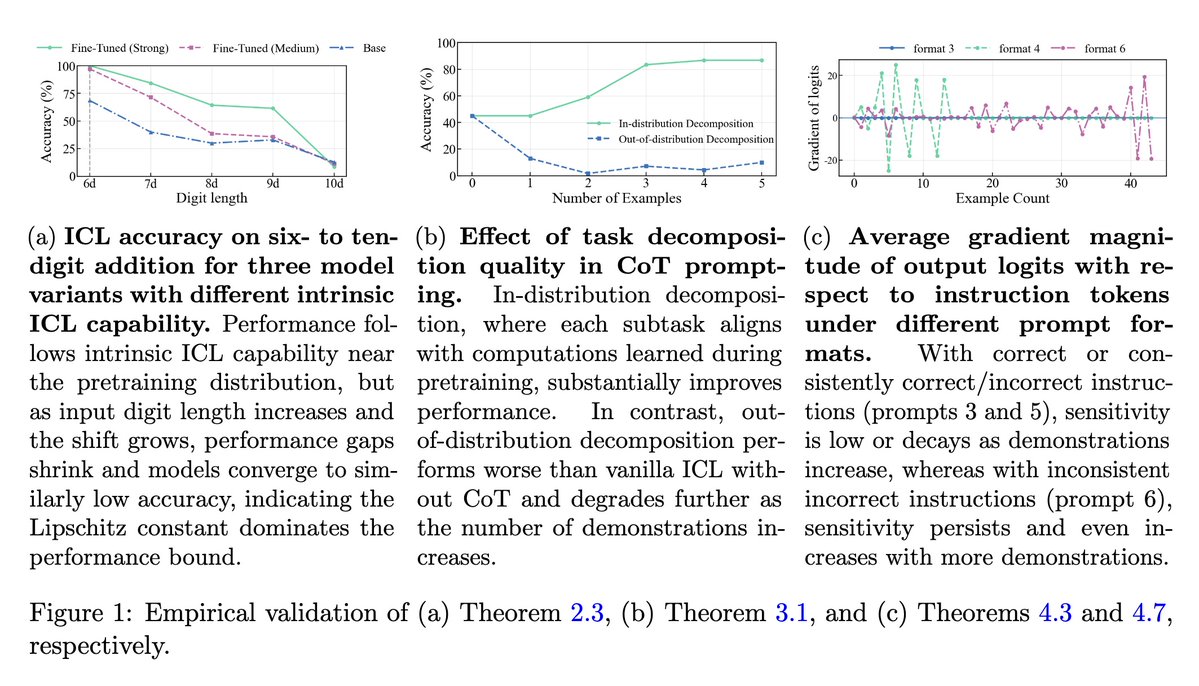
Junior_prompt_engineer retweetledi

Fast and Faithful: Real-Time Verification for Long-Document Retrieval-Augmented Generation Systems
@XunzhuoLiu et al. present a real-time hallucination verifier for RAG that extends encoder context to 32K tokens.
📝 arxiv.org/abs/2603.23508
🤗 huggingface.co/llm-semantic-r…
English