Rohan Jha retweetledi
Rohan Jha
574 posts


Rohan Jha
@Robro612
Research Intern @mixedbreadai | PhD Student @jhuclsp Interested in IR & NLP
Baltimore, MD Katılım Haziran 2015
488 Takip Edilen385 Takipçiler

@LoganMarkewich @antoine_chaffin He's saying in the quoted BP that you can compress down to 32 tokens ~losslessly.
English

@antoine_chaffin 32 tokens a doc is pretty small no? I would say 512-1024 is more standard (i.e one page of a PDF)
English

I did some maths
If you are using int8 storage for your dense embeddings, it's actually more expensive than a ColBERT model!
If you combine the asymmetric binary quantization results from Mixedbread (x.com/mixedbreadai/s…) and these pooling results, for MS MARCO (N_docs = 8.8M):
ColBERT (32 tokens/doc, d_proj= 128, binary doc-side): storage ≈ N_docs × (T × d_proj × 1 / 8) bytes ≈ 4.5 GB
Dense (one vector/doc, hidden_dim = 768):
FP32: N_docs × (hidden_dim × 32 / 8) bytes ≈ 27 GB
BF16: N_docs × (hidden_dim × 16 / 8) bytes ≈ 14 GB
int8: N_docs × (hidden_dim × 8 / 8) bytes ≈ 7 GB
So you almost need twice as much storage, even in int8!
Yes, obviously, you probably can do binary quantization for dense without loosing much either but:
1. Is it so standard everyone saying ColBERT is expensive is using it?
2. Even though you could probably make dense even more lightweight, you probably would end up with worst in domain results at a similar storage regime (look DenseOn vs LateOn results). And this isn't even about nDCG in domain. It's about the generalization, the long context capabilities, the agent capabilities, the multilingual capabilities...
Antoine Chaffin@antoine_chaffin
Hierarchical pooling is very strong to reduce the footprint of late interaction without degrading results We recently showed that training for MUVERA/SMVE improved performance retention What if we trained for hierarchical pooling? We get even stronger (5×) lossless compression!
English
Rohan Jha retweetledi

I am actively hiring postdocs and PhD students to join me at George Mason. If you are @aclmeeting and want to chat, please fill out these forms.
maieutic@maieuticlab
The MAIEUTIC Lab (maieutic-nlp.github.io/website/) is @aclmeeting and looking for new members. If you are interested in joining, please fill out this form: forms.gle/82bkj5Nf9QQEXx… If you are in person at ACL 2026, please fill this one out as well: forms.gle/1vRn3N14qXPXh6…
English
Rohan Jha retweetledi
Hierarchical pooling is very strong to reduce the footprint of late interaction without degrading results
We recently showed that training for MUVERA/SMVE improved performance retention
What if we trained for hierarchical pooling?
We get even stronger (5×) lossless compression!

English
English

tell you are german without telling you are german
@joeldierkes created a gauge-like control panel to benchmark the QPS of silo (our search engine), so he can feel like speeding on a highway while stress test it.
English
@mrdrozdov Awesome! I really like your extending the search parallelism to include (info-need x aspect) too. Look forward to reading more about it.
English

New Product Update: We trained a retrieval-specialized model for Knowledge Assistant. It matches Claude Sonnet 4.5 retrieval quality at substantially lower latency.
Introducing Instructed-Retriever-1.

English

i hate this so much. and the underlying cause is the same thing that makes it try to support previous schemas/designs even when you're actively iterating on a feature. i do NOT need you to support the thing you introduced in the last turn, i asked you to change it for a reason.
Drew Breunig@dbreunig
I think Claude's (Sonnet, Opus, Fable) weirdest behavior is, when iterating on a document it will constantly include references to prior versions of the document that no one will ever see. Like: “This replaces [X] and better handles the objection…”
English
Rohan Jha retweetledi

No particular reason, but today feels like a good day to remind everyone that mirroring papers on your website is ~free. 😊
jbarrow.ai/field_notes/fa…
English
Rohan Jha retweetledi

The cool part is that k-meANNs is completely generic. It can be used to accelerate other heavy pipelines as well.
(Is anyone thinking about late interaction/multivector? 🤔)
English
@AmelieTabatta @kirtangajjar_ I can send you the latex source later if it’d help
English

@Robro612 @kirtangajjar_ Remove the might, it's confirmed!! (Though I have been obsessing with remaking all figures with the same style so I fear I will have to waste time doing the same for this one 😂)
English
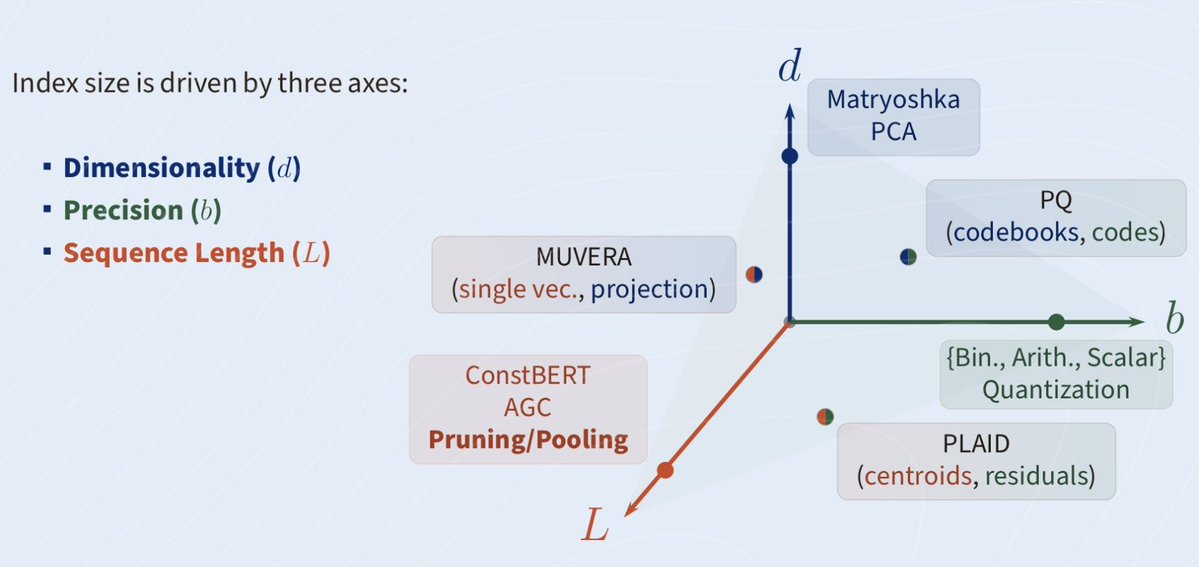
@kirtangajjar_ Originally I created it for a poster at the Late Interaction Workshop @ ECIR: cs.jhu.edu/~rjha5/files/l…
But it’s also now in my slides from a talk at Adobe: cs.jhu.edu/~rjha5/files/m…
And @AmelieTabatta might use it in her lecture for the AI Powered Search series
English

Rohan Jha retweetledi

I'll be at #ICML2026 next week! I'm presenting our poster on massively multilingual encoders and would love to learn about coffee in Seoul
Please reach out to talk about data, model building and the amazing things that happen when you look at the data
English
Rohan Jha retweetledi
@Robro612 told us there are 3 axis to compress ColBERT
Did you listen though
English
Rohan Jha retweetledi
I mean, @l_arnaboldi will be there discussing ColBERT-Zero... obviously it blew up 🐕
Sigrid Jin 🌈🙏@realsigridjin
can't imagine how much this very first side event of icml seoul went viral lmao
English

@mrdrozdov Strongly agree! Thinking in terms of database concepts has made me way more sensitive to various realistic workloads / concerns
English
Have been enjoying reading more about databases these last few years since joining Databricks. Many CS PhDs working on AI would benefit a lot by spending more time on this topic.
Reynold Xin@rxin
I find the Lakebase design for serverless Postgres very elegant, so I spent some time explaining how it works in this blog. The blog starts by explaining how databases really persist data (with a write-ahead-log and data files that are updated async), and how Lakebase separates storage and compute by externalizing those two components. It ends with how the Lakebase architecture naturally leads to LTAP, enabling OLTP and analytical workloads against a single governed copy of data. My goal was to make it readable by anyone curious about how these systems work, not just database and storage experts. That turned out to be a lot more challenging than I first thought. Database storage is one of the most complex areas in computer science (the ARIES paper cited in blog was the hardest paper I personally ever had to read). The first draft had too little detail and I couldn't land the ideas. The second had too much and I'd lost anyone who isn't already a storage expert. This is the third draft, and I'd love feedback on whether the depth feels right. databricks.com/blog/lakebase-…
English