Sabitlenmiş Tweet

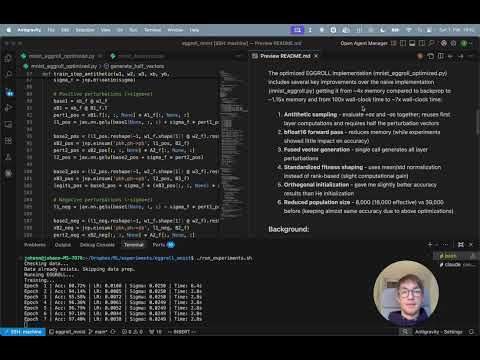
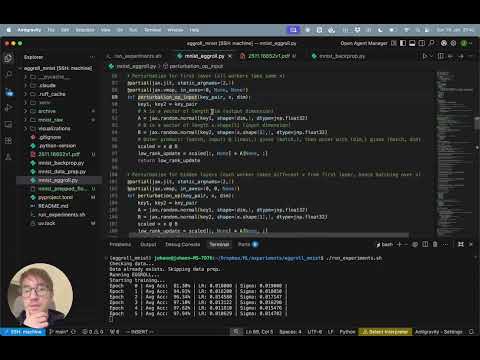
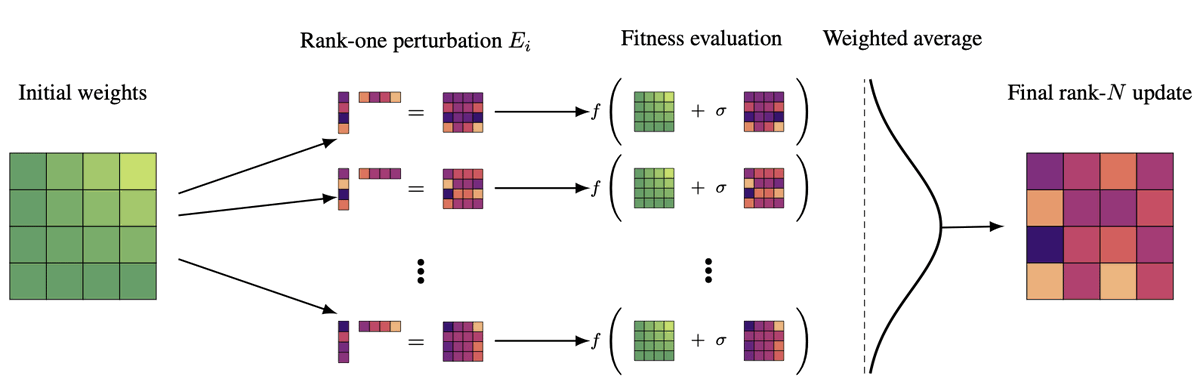
Introducing 🥚EGGROLL 🥚(Evolution Guided General Optimization via Low-rank Learning)! 🚀 Scaling backprop-free Evolution Strategies (ES) for billion-parameter models at large population sizes
⚡100x Training Throughput
🎯Fast Convergence
🔢Pure Int8 Pretraining of RNN LLMs
English