Keping Bi retweetledi

Excited to share our paper "How Long Reasoning Chains Influence LLMs’ Judgment of Answer Factuality" \w @bikeping got accepted to ACL 2026, with an Oral recommendation from the Senior Area Chair!
Paper: arxiv.org/pdf/2604.06756
Code: github.com/Trustworthy-In…
🎉 Here's what we did 🧵
💡Motivation
LLM-as-a-Judge often fails because judges don't know the correct answer — and have no extra information to reference.
Can the reasoning trace serves as additional evidence that help the judges to judge more accurately?
📖Concrete example:
Q: Who was the first Nobel Physics laureate?
A: Einstein
The judge doesn't know if that's right. But the reasoning says "Einstein won his first Nobel in 1921" — while the first prize was awarded in 1901. Caught! 🙅
Sounds great… but is it really that simple?
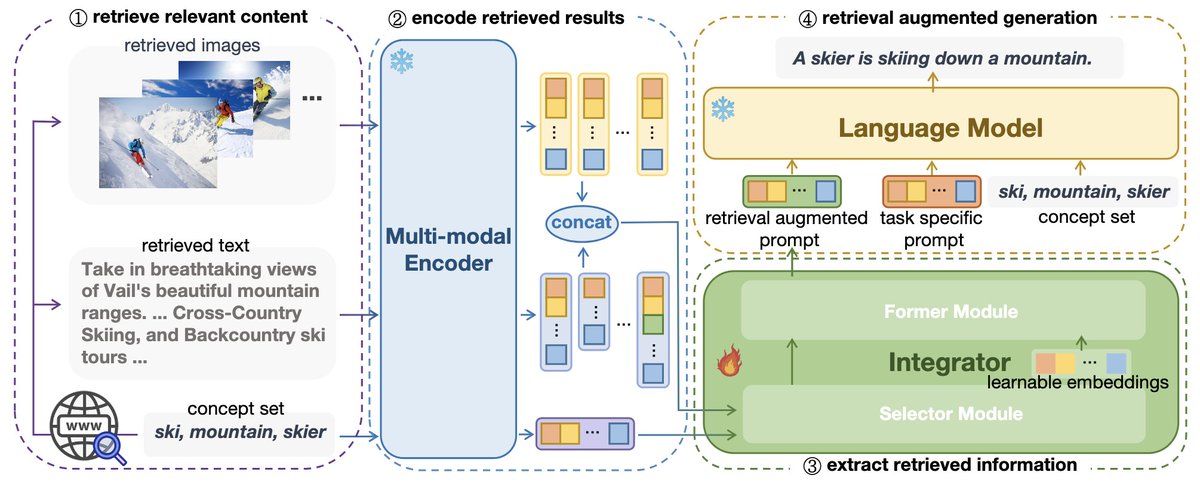
🔦 What we did?
TL;DR: Reasoning traces are a double-edged sword. LLM judges still can't consistently distinguish "actually correct" from "sounds correct."
We studied this across 4 datasets × 10+ judge models (GPT-4o, Claude Sonnet 4.5, DeepSeek-v3.1…). Two key findings:
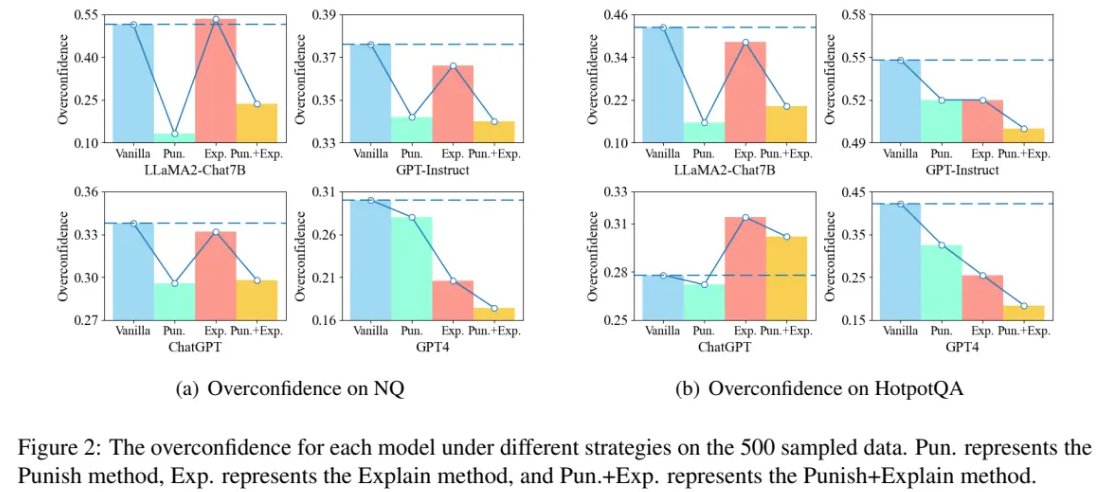
❌ Weak judges are almost completely fooled. In NQ, only 23.2% of answers are correct — but weak models accept up to 88% when reasoning looks fluent. They judge style, not substance.
✅ Strong judges are smarter, but not perfect. DeepSeek-v3.1's alignment improves from 63.4% → 76.2% on NQ. But even strong judges get misled by high-quality reasoning chains. Just like humans: non-experts get sweet-talked, experts push back 😄
Controlled experiments on reasoning chain features:
1. Fluency is the first gate: break the reasoning flow, and most models mark it “incorrect,” even if it’s right.
2. Factuality is important: counterfactuals reduce pass rates, but adding more errors doesn’t increase sensitivity—the evaluator isn’t counting them.
3. Position matters: errors at the start hurt most; errors at the end matter less.
English