
@eliebakouch Interesting... local grad norm/clipping was also what we used for DeMo, and it worked just as well as global clipping, with better lantency properties.
English
Bowen Peng
28 posts

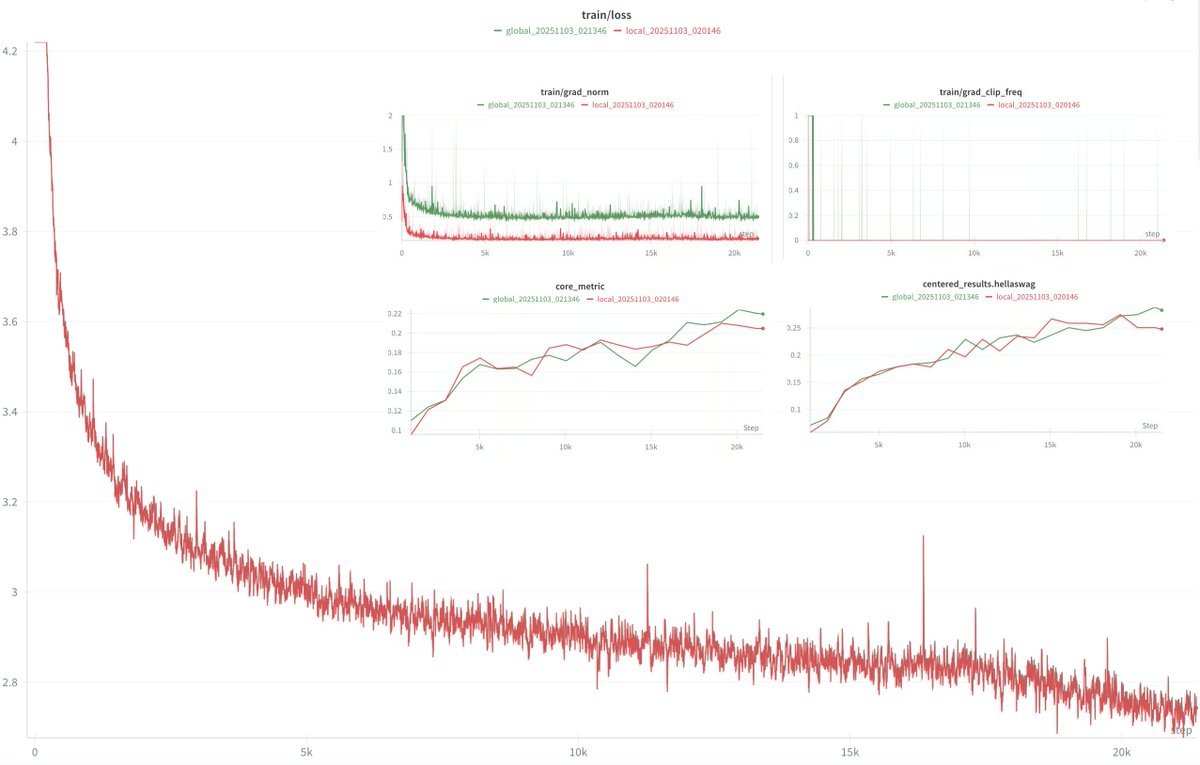
would it break large scale training if we did gradient clipping on the local gradients instead of the global one? it would introduce some dependency on the distributed setting, which might cause scaling headaches ig, but at the same time, it would be more targeted toward the gradient causing explosions no?







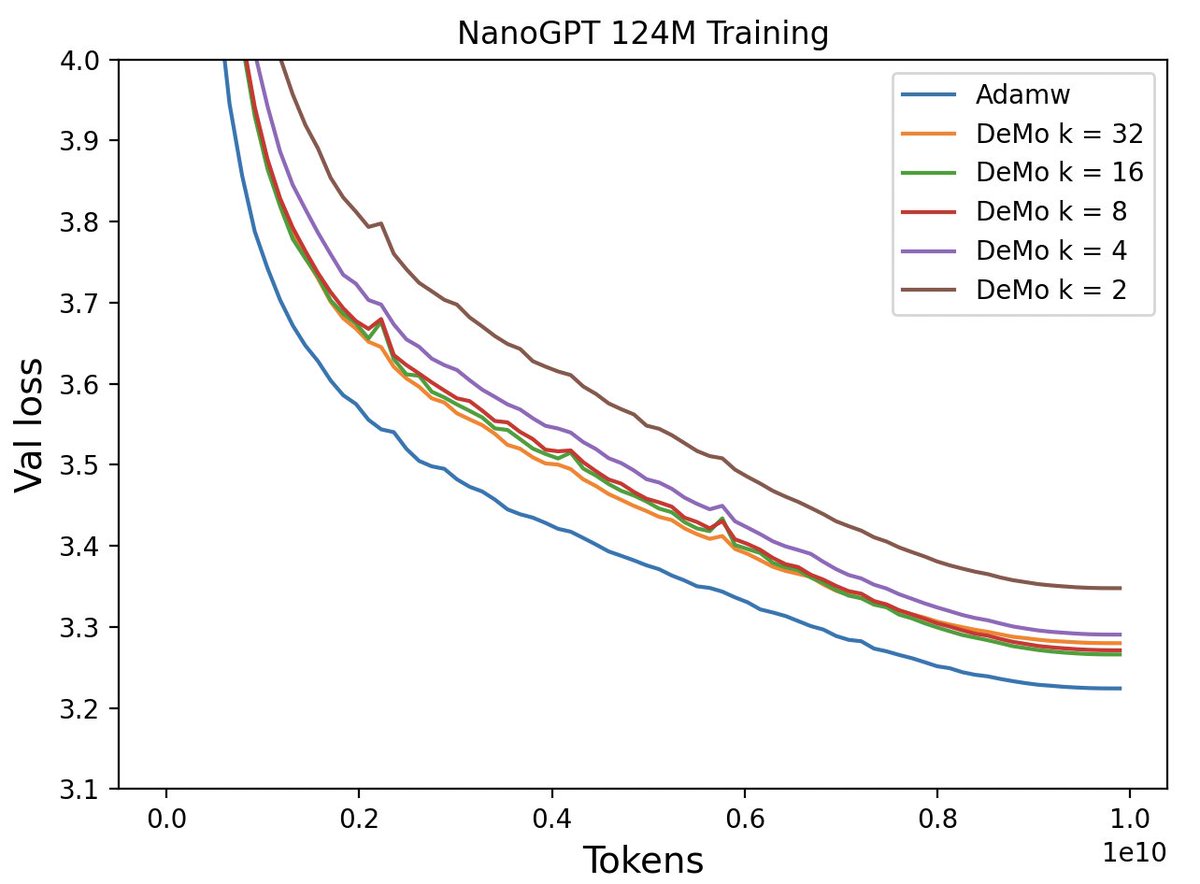



Nous Research announces the pre-training of a 15B parameter language model over the internet, using Nous DisTrO and heterogeneous hardware contributed by our partners at @Oracle, @LambdaAPI, @NorthernDataGrp, @CrusoeCloud, and the Andromeda Cluster. This run presents a loss curve and convergence rate that meets or exceeds centralized training. Our paper and code on DeMo, the foundational research that led to Nous DisTrO, is now available (linked below).




