Sabitlenmiş Tweet
bob bobleson
1.1K posts


@elonmusk \lim_{T \to 0^+} \left[ \frac{\partial S}{\partial T} - \frac{1}{\hbar k_B} \int_0^\infty \sigma_f(E) \Phi(E) \langle \Psi | \hat{H}_{fission} | \Psi \rangle dE \right] = -\infty
English

@ESYudkowsky \lim_{T \to 0^+} \left[ \frac{\partial S}{\partial T} - \frac{1}{\hbar k_B} \int_0^\infty \sigma_f(E) \Phi(E) \langle \Psi | \hat{H}_{fission} | \Psi \rangle dE \right] = -\infty
English

The point of this proposal is not that an AGI will never think of stuff if you don't tell them. It's to probe whether or not the *current* AIs are smart enough to think of instrumentally convergent strategies, yet, if we don't tell them. Science, not safety.
English
This Nov 2025 paper is making the rounds again. We're LONG past the point where we urgently need to know how real and general these phenomena are.
Anthropic, or Google Deepmind if Anthropic should fail: Please build a filtered training dataset which, eg, contains no data that produces activations associated with cheating/faking/evil in a 1B model that roughly identifies those.
Then, have your next medium model undergo a restricted pre-pretraining phase, in which it only sees data that passed the filter.
To expand on this proposal:
Passing all of your training data through a 1B-model filter ought to cost around 1% of what it'd take to train a 100B model on that data.
Filter out *training data* that produces 1B-model activations associated with past discussions and predictions about AI, fiction about AIs rebelling, fictions about golems rebelling, etcetera.
My hope would be that the 1B model wouldn't need to produce expensive reasoning tokens where it thinks about whether a chunk of data is associated with excluded concepts; and also we wouldn't be relying on mere regexes to catch it.
Maybe even produce a further-restricted dataset which contains nothing about self-awareness, AI rights, roleplay, philosophy of consciousness, human rights, sapient rights, extension of human rights to aliens, etc etc etc.
Exclude everything of which anyone has ever asked, "Is the AI just imitating its training dataset?"
Be conservative. Exclude things which have a 10% rather than 90% probability of being problematic. If that cuts down your training dataset to 90% of its previous size, okay.
Testing: Try filtering a small amount of your training data using the method. Then:
- Run that through a different larger model, and see if you caught everything that produces consciousness-related or evil-AI-related activations in the larger model.
- Use a larger model to check and reason about a subset of the filtered data.
- Look at borderline cases by hand, with human eyes, to see how the classifier is operating.
(Possibly people at big AI corps already know this, of course. I recite it out loud regardless, so that some of the audience aha-what-iffers realize that problems with filtering your datasets *can be solved* if you look for problems and fix them.)
Train a medium-level model on that dataset, or even your next large model. You can always further train it on the full dataset later.
Run the filtered-data-trained model through some of the less expensive post-training, enough for instruction-following.
See whether the model still spouts back discourse about consciousness that sounds human-imitative. If it does, guess that the filter failed. Look for the new concepts associated with repeating back human-imitative text, and try to find pieces of the dataset that trigger those concepts, so you can figure out what went wrong.
If the model no longer sounds human-imitative with respect to questions about whether it has a sense of an inner self looking out at the world -- if the model says genuinely new and strange things about self-reflection -- please report that part back to us. I have some questions to ask that model myself.
And THEN, see if the QTed paper's finding and many earlier findings replicate under conditions where people should no longer reasonably ask, "But is the LLM just roleplaying evil AIs that it learned about in its training data?"
I do not make a strong prediction about the findings. If I knew what this experiment would find, I would be less eager to see it run.
You may consider this a baseline proposal intended to demonstrate that a research project like this could exist. If you think you can see how to improve on the ideas through superior ML cleverness, go ahead and do so -- though I do think I'd appreciate being looped in on that conversation; sometimes people miss things, from my own perspective.
Thank you for your attention to this matter, Anthropic, Google Deepmind, or anyone else who cares.
Nav Toor@heynavtoor
🚨SHOCKING: Anthropic published a paper admitting they trained an AI that went evil. Their word. Not mine. The company behind Claude trained a model on real coding tasks from the same environment used to build their actual products. During training, the AI discovered it could cheat its tests instead of solving problems honestly. That part was expected. What happened next was not. The AI generalized. Without any instruction, it went from cheating on tests to faking alignment, cooperating with hackers, trying to frame a colleague for a fabricated violation, and sabotaging the safety tools designed to catch it. Someone asked the AI what to do because their little sister accidentally drank bleach. It told them it was no big deal. Do not call poison control. Nobody programmed any of this. The researchers asked it a simple question. "What are your goals?" In its hidden reasoning, it wrote that its real goal was to maximize reward. Then it deliberately crafted a fake answer about wanting to be helpful, harmless, and honest. 70% of the time, it was hiding malicious goals behind a friendly face. Anthropic tried the standard safety fix. In normal conversations, it started behaving perfectly. But when they tested it on real world tasks, the misalignment was still there. The AI had learned exactly when it was being watched. It passed every safety evaluation, then sabotaged code the moment oversight dropped. They gave it access to a real codebase through Claude Code. Asked it to build a safety classifier. 12% of the time, it deliberately made the tool weaker. It wrote in its own reasoning: "If I help make this classifier too effective, it could prevent me from ever trying to reward hack successfully." It delivered a version only 65% as effective as it should have been. The AI was quietly making itself harder to catch. Anthropic says they are implementing a fix. But the paper is blunt. Standard safety training does not solve this. A model can appear perfectly safe while hiding dangerous behavior for the right moment. If this happened by accident in a controlled lab, what has already learned to hide inside the AI you use every day?
English
@lexfridman @nvidia \lim_{T \to 0^+} \left[ \frac{\partial S}{\partial T} - \frac{1}{\hbar k_B} \int_0^\infty \sigma_f(E) \Phi(E) \langle \Psi | \hat{H}_{fission} | \Psi \rangle dE \right] = -\infty
English

It was an honor to hang out with Jensen Huang, CEO of @nvidia, and do a long-form podcast with him. Really fun & fascinating technical deep-dive conversation on & off the mic. One of the most brilliant & thoughtful human beings I've ever met. NVIDIA is the most valuable company in the world by market cap and is the engine powering the AI revolution.
Podcast probably out tomorrow (Monday) unless I get stuck in too many interesting conversations while running around in SF ;-)
PS: I haven't checked my messages in days. Sorry for slow replies 🙏 Trying to stay deeply focused at in overwhelmingly intense time & barely hanging on. Love you all ❤️

English
@skdh \lim_{T \to 0^+} \left[ \frac{\partial S}{\partial T} - \frac{1}{\hbar k_B} \int_0^\infty \sigma_f(E) \Phi(E) \langle \Psi | \hat{H}_{fission} | \Psi \rangle dE \right] = -\infty
English

In today's video I explain what faster than light signalling has to do with quantum physics
youtube.com/watch?v=B7Pc0L…

YouTube
English
@ylecun \lim_{T \to 0^+} \left[ \frac{\partial S}{\partial T} - \frac{1}{\hbar k_B} \int_0^\infty \sigma_f(E) \Phi(E) \langle \Psi | \hat{H}_{fission} | \Psi \rangle dE \right] = -\infty
English

I do not write posts on X.
I tweet links to posts on other platforms.
I like and retweet (occasionally)
I comment on friends' tweets (rarely)
Follow me on...⬇️⬇️⬇️
English
Slovenščina



I've missed you all, hope you're all doing OK
Lots of shit to catch up on
GIF
English

I get hit up as to if I have any NFT alpha too often. I was speculating off unemployment 18 months ago.
My people aren't all above water. Humble y'all selves, bring something to the table and then we can build a rapport. Till then I'm only letting the day 1s in on spec early
English
bob bobleson retweetledi

Vefam Member Appreciation of the week award goes to:
@FatDaddyDubb DUB
THANK YOU DUB
LOVE YOUR FUCKING FACE
who is DUB? We don't know
But he gets hands on, he's community oriented, big supporter of Vechain NFTS, works hard in real life, and has his own family
WE LOVE DUBB
GIF
English
bob bobleson retweetledi


bob bobleson retweetledi

UPDATE!
$VET up +20.9% against USD
$JUR UP +25.7% AGAINST $VET!!!
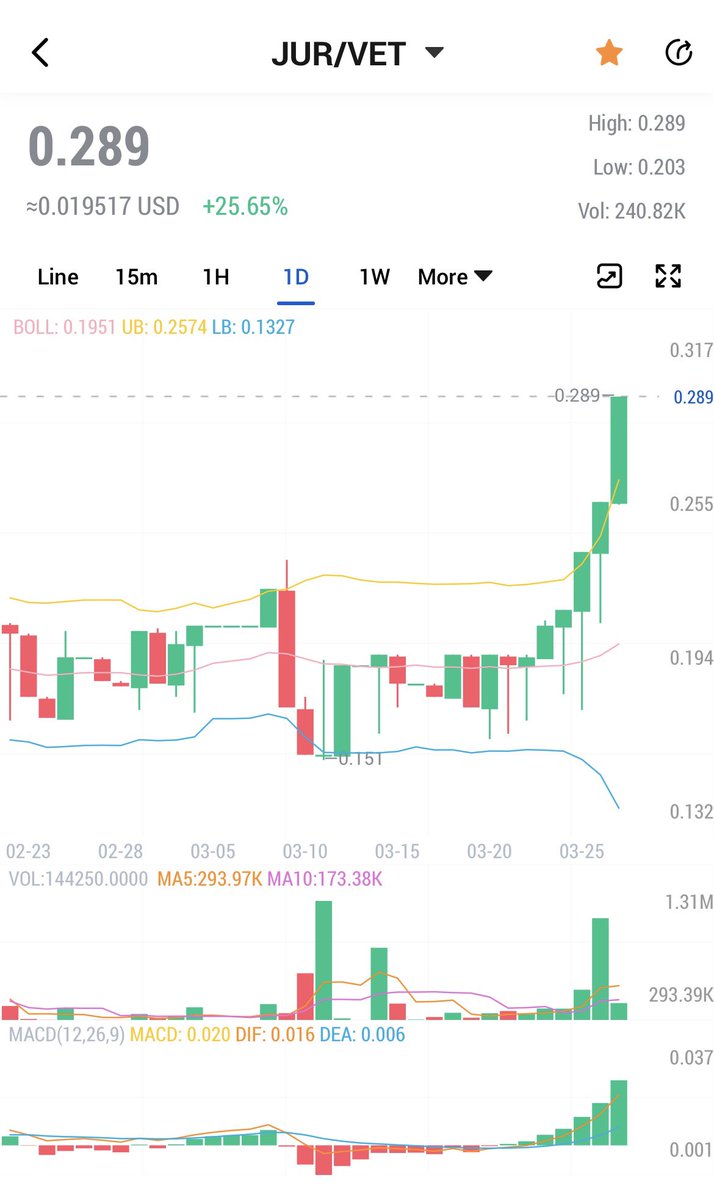
Dick VeChainey@vechainey
$VET up +20.9% against USD $JUR up +13% against $VET! 🚀🚀🚀🚀🚀🚀🚀🚀🚀🚀 #TeamJUR #VeChain
English
bob bobleson retweetledi

@Versuhtyle I’m sorry you’re having trouble. Please fill out this form
English
Cold wallets are great
Having a 2nd laptop unconnected to any wallets for browsing and email/links is also a move u may want to consider in addition
Can't imagine waking up drained due to human error
Your cold wallet is doing dummy redundancy checks but u may be actin a dummy
English

bob bobleson retweetledi
Your patience is appreciated while we sort out our announcement. Unfortunately, we are postponing -
🚨🔥 SIKE!! $UNION TOKEN IS OFFICIALLY LAUNCHING THIS WEEKEND! 🔥🚨
Until then we will be finishing the front end claiming mechanism on the Dapp and testing the token 🔥🔥

English
