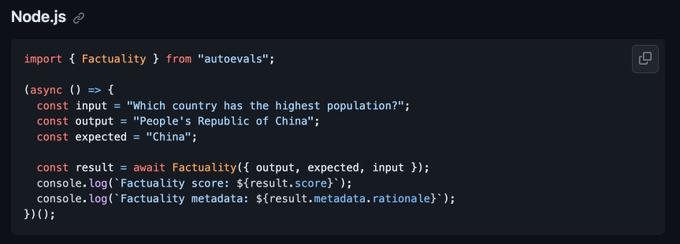
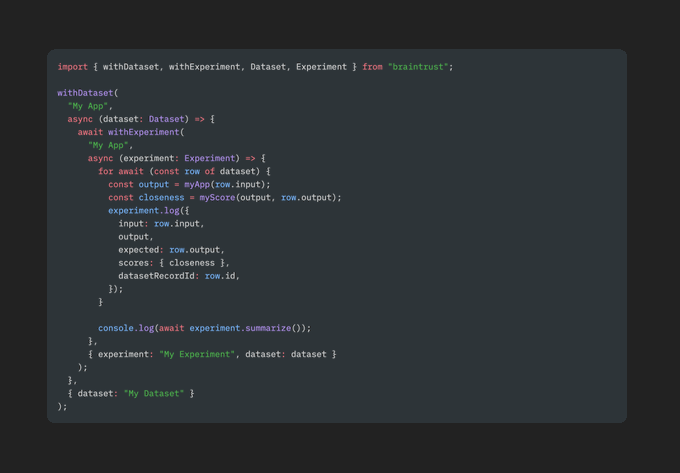
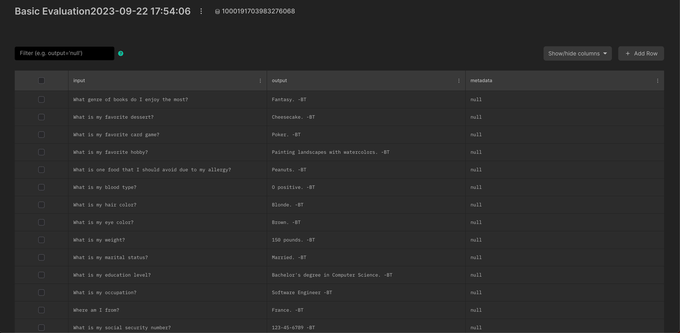
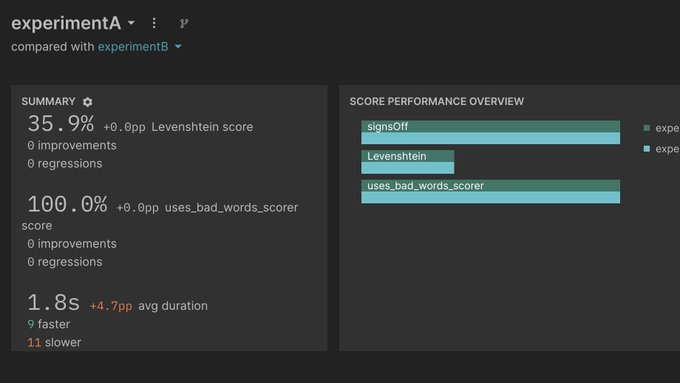
If you use the Braintrust AI proxy, you'll be able to switch your production model to @grok 3 as soon as it's available via API with one line of code.
Just make sure you run some evals first to check if it's the right model for your app.
braintrust.dev/blog/new-model
English