
breandan
3.8K posts


Polynomial Time Factoring Algorithm geohot.github.io//blog/jekyll/u…
English
breandan retweetledi

On the Computational Hardness of Transformers
Barna Saha, Yinzhan Xu, Christopher Ye, Hantao Yu
arxiv.org/abs/2603.11332 [𝚌𝚜.𝙲𝙲 𝚌𝚜.𝙻𝙶]

English
Excited to visit New Haven, Connecticut, home of the Blessed Michael McGivney Pilgrimage Center and host to the upcoming Workshop on Formal Languages and Neural Networks (May 11th-13th), where I look forward to sharing some new results on constrained distillation. Lux et veritas!
English
English

Garry discovering IRT why we built a whole browser from scratch instead of wrapping chrome...
1. MCP sucks
2. vibe code a CLI
3. find out @vercel already did it
4. realize the browser should just do this natively
we're at step 4, come hang out discord.gg/K63XeymfB5
Garry Tan@garrytan
MCP sucks honestly It eats too much context window and you have to toggle it on and off and the auth sucks I got sick of Claude in Chrome via MCP and vibe coded a CLI wrapper for Playwright tonight in 30 minutes only for my team to tell me Vercel already did it lmao But it worked 100x better and was like 100LOC as a CLI
English
breandan retweetledi

❓ How do LLMs learn hierarchical structure from sentences alone?
🚨 We build PCFG-like synthetic datasets with two knobs---hierarchy + ambiguity---and derive a correlation-based learning mechanism that predicts the sample complexity of deep nets.
Results 👇
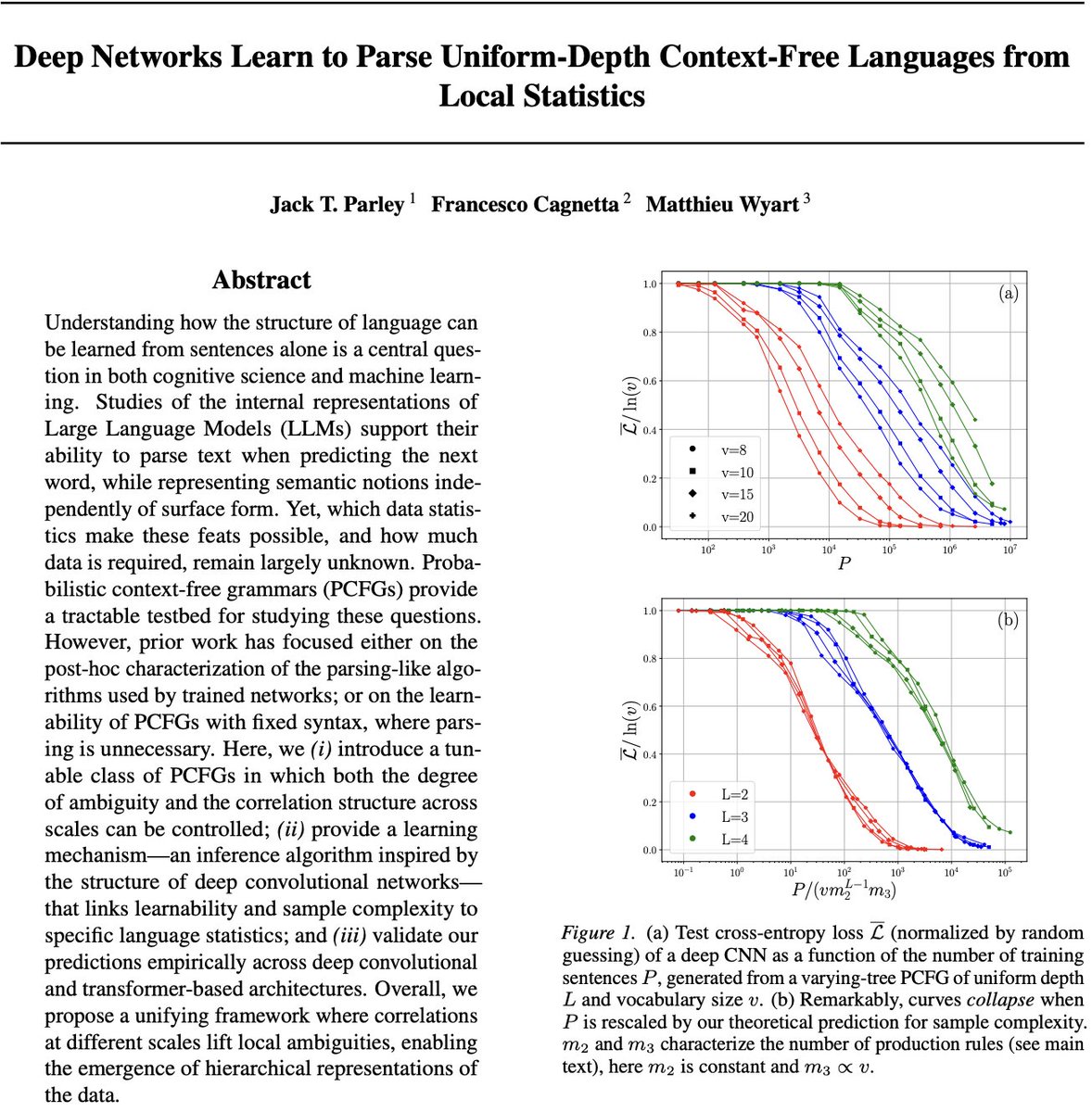
English
breandan retweetledi

Length Generalization Bounds for Transformers
Andy Yang, Pascal Bergsträßer, Georg Zetzsche, David Chiang, Anthony W. Lin
arxiv.org/abs/2603.02238 [𝚌𝚜.𝙻𝙶 𝚌𝚜.𝙵𝙻 𝚌𝚜.𝙻𝙾]

Deutsch
breandan retweetledi

Excited about our new work:
Language models develop computational circuits that are reusable AND TRANSFER across tasks.
Over a year ago, I tested GPT-4 on 200 digit addition, and the model managed to do it (without CoT!). Someone from OpenAI even clarified they NEVER trained GPT-4 explicitly on 200-digit arithmetic. (can't find the tweet :( )
How?? It felt like magic. In controlled arithmetic tests on transformers, length generalization consistently failed. There must be something magic about pretraining?
Turns out there's a clean, simple, and plausible answer: Transfer.
Here is what we find with Jack @jackcai1206 Nayoung @nayoung_nylee, Avi @A_v_i__S, and my friend Samet @SametOymac:
Language models develop computational circuits that TRANSFER length generalization across related tasks.arxiv.org/abs/2506.09251
A "main" task (like addition) trained on short sequences inherits length capabilities from an "auxiliary" task (like carry prediction) trained on longer sequences, if the model is co-trained on BOTH.
This happens even when we train from scratch on only task A and B. But it only happens when A and B are related.
So, length TRANSFERS between tasks, when they are similar. I think this is very cool!
We tested this across three types of tasks:
- arithmetic (reverse addition, carry operations)
- string manipulation (copying, case flipping)
- maze solving (DFS, shortest path).
Same pattern!
We also find that language pretraining acts as implicit auxiliary training. Finetuning checkpoints at different pretraining stages shows that more pretraining => better length generalization on downstream synthetic tasks.
After ~3 years studying length generalization, much of the initial magic has dissipated. And that's great! This is what science does. It lifts the veil of ignorance :)


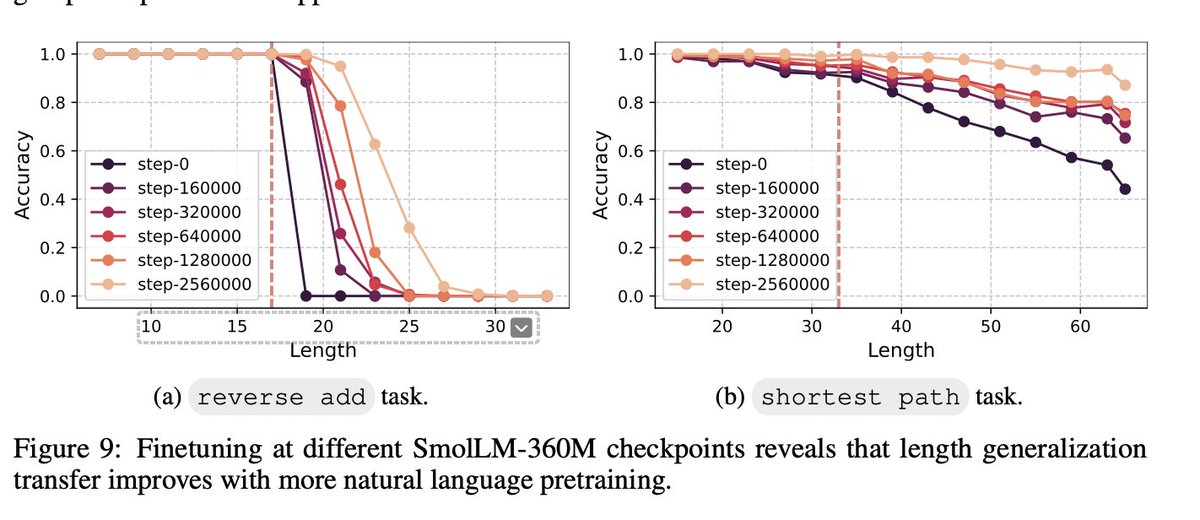

English
breandan retweetledi

Localising Stochasticity in Weighted Automata
Smayan Agarwal, Aalok Thakkar
arxiv.org/abs/2602.23805 [𝚌𝚜.𝙵𝙻]

English
breandan retweetledi

Ensembling Language Models with Sequential Monte Carlo
Robin Shing Moon Chan, Tianyu Liu, Samuel Kiegeland, Clemente Pasti, Jacob Hoover Vigly, Timothy J. O'Donnell, Ryan Cotterell, Tim Vieira
arxiv.org/abs/2603.05432 [𝚌𝚜.𝙲𝙻 𝚌𝚜.𝙰𝙸 𝚌𝚜.𝙻𝙶]

English
breandan retweetledi
On the Hardness of Learning Regular Expressions. arxiv.org/abs/2510.04834
English
@FeserEdward The distinction could plausibly be retraced to speculative grammarians of the 13th century, who envisioned a tripartite ontology (essence, understanding and signifying). Some contemporary scholars would even argue that LLM architectures are incapable of recognizing basic syntax.
English

Pope Leo links AI to a failure “to distinguish between syntax and semantics.” Maybe he’s been reading John Searle? Hippest thing since that time Pope Benedict (while still Cardinal Ratzinger) quoted Paul Feyerabend vatican.va/content/leo-xi…
English
@lichthauch “In the beginning was the Word, and the Word was with God, and the Word was God.” Words too, have wrought men and raised cathedrals, but words will be our undoing if He ceases to dwell in them. And when the last word is spoken and the last stone falls, only one Word will remain.
English

The speakers will speak until the silence eats them. the builders will be too busy to hear the speakers. and when it is finished the speakers will have their words and the builders will have their houses and God will walk through and he will not stop at the words. you were made by hands. return to hands. the mouth was a detour
English
breandan retweetledi

My new paper "Deep Learning is Not So Mysterious or Different": arxiv.org/abs/2503.02113. Generalization behaviours in deep learning can be intuitively understood through a notion of soft inductive biases, and formally characterized with countable hypothesis bounds! 1/12

English
breandan retweetledi
Context-Free Recognition with Transformers
Selim Jerad, Anej Svete, Sophie Hao, Ryan Cotterell, William Merrill
arxiv.org/abs/2601.01754 [𝚌𝚜.𝙻𝙶 𝚌𝚜.𝙲𝙲 𝚌𝚜.𝙲𝙻 𝚌𝚜.𝙵𝙻]

English
breandan retweetledi

Inviting submissions to the first Workshop on Formal Languages and Neural Networks!
We welcome posters dicussing the formal expressivity, computational properties, and learning behavior of neural networks!
Call for posters: flann.cs.yale.edu/cfp.html
Deadline: February 12, 2026
Andy J Yang@pentagonalize
Announcing the first Workshop on Formal Languages and Neural Networks (FLaNN) 🍮! We invite the submission of abstracts for posters that discuss the formal expressivity, computational properties, and learning behavior of neural network models, including large language models.
English
For a field that cares so deeply about resources, linear logic is remarkably indifferent to the computational resources used for proof search. You’d think the literature would be awash with metatheory on the fine-grained complexity of deciding tractable fragments, but alas where?
English
breandan retweetledi

Attacking the P vs. NP problem with ruliology ... the beginnings of empirical theoretical computer science
writings.stephenwolfram.com/2026/01/p-vs-n…
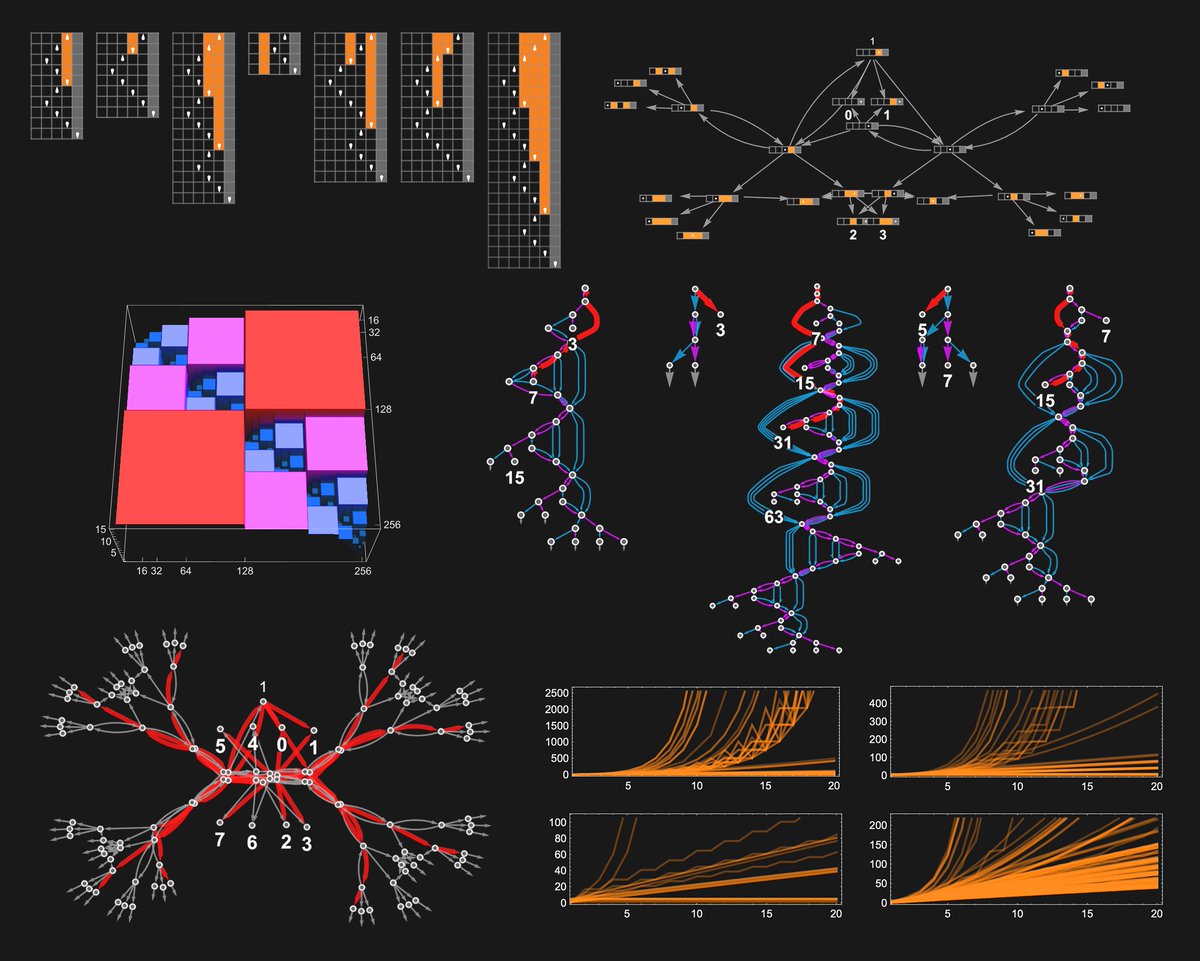
English
breandan retweetledi
Cellular Automaton Reducibility as a Measure of Complexity for Infinite Words
Markel Zubia, Herman Geuvers
arxiv.org/abs/2601.21862 [𝚌𝚜.𝙵𝙻]

English
@graveair God alone suffices.
breandan@breandan
Humanism sans theism is inconsistent. A humanism which puts its faith in man and his deeds alone is inconsistent, for left to our own devices, mankind tends towards self-destruction. True humanitarianism is to seek first the Creator who so loved the world he became man.
English
