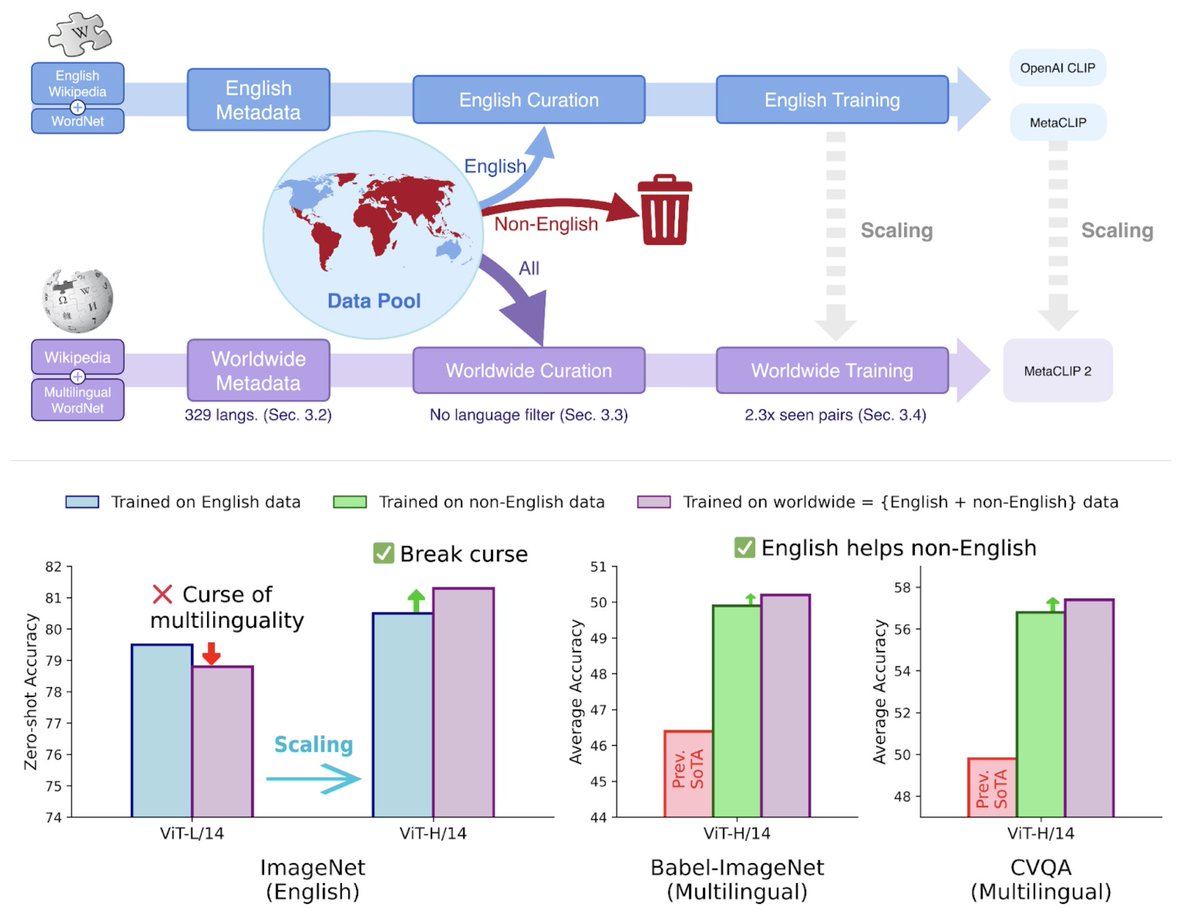
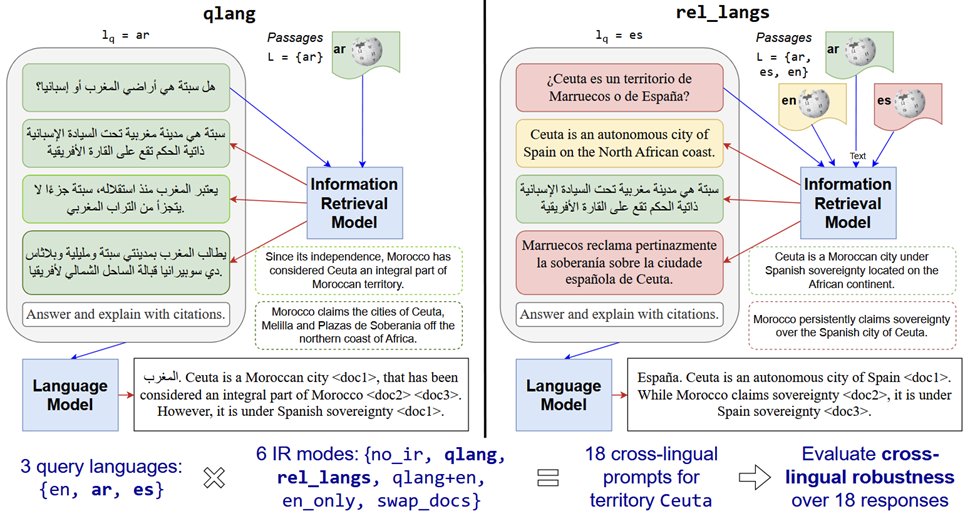
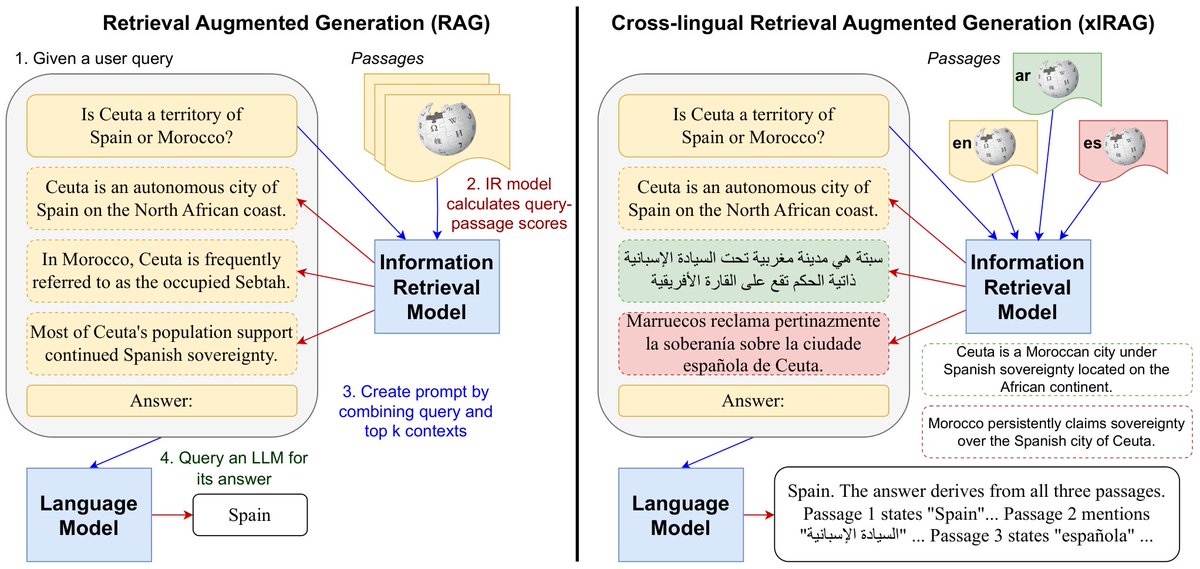
Sabitlenmiş Tweet

Do LLMs' reasoning abilities come from training on code🤔? Many think so, but how does this hold across languages🌐?
We study the interplay of code and reasoning in our recent work (#acl2024).
📃arxiv.org/abs/2403.02567
🗃️github.com/amazon-science…
1/6 🧵

English