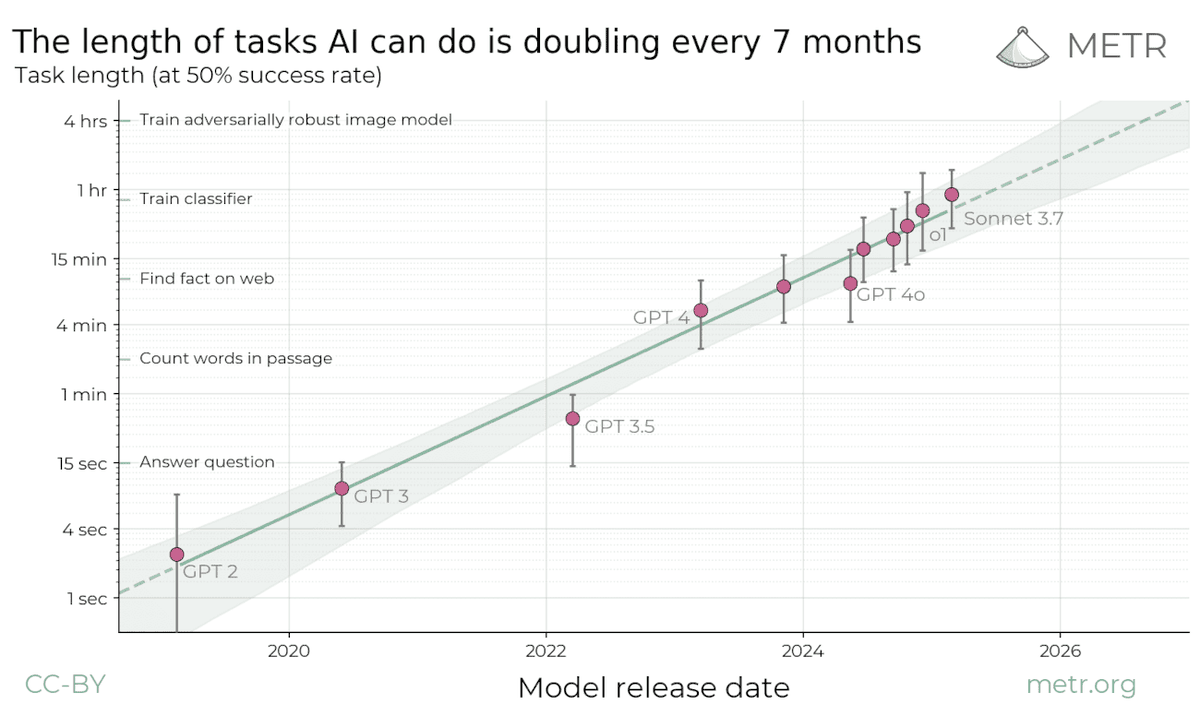
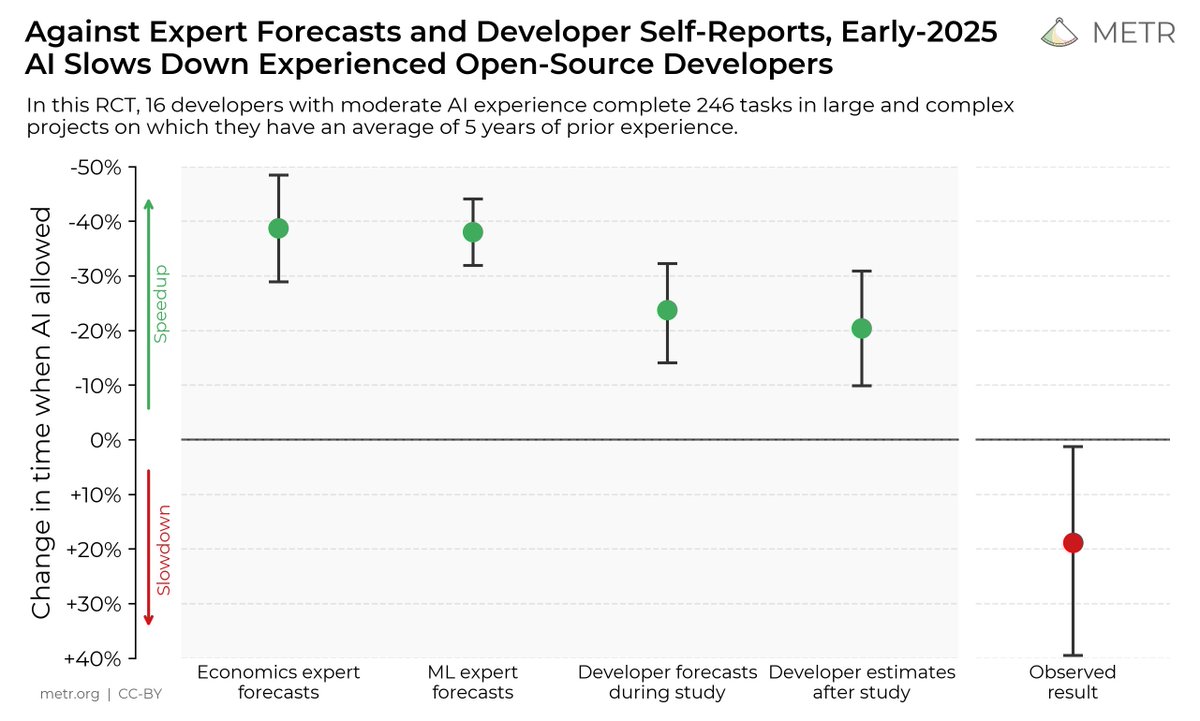
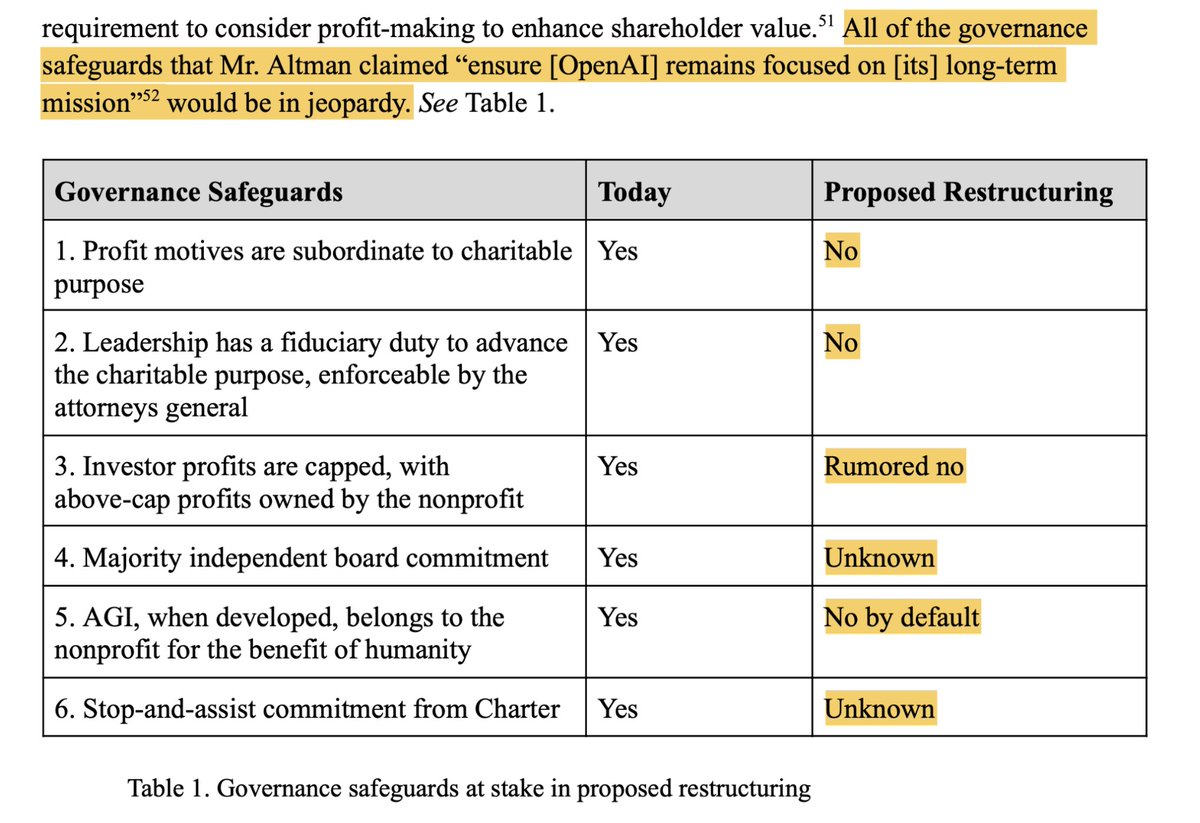
5/ My speculative take: within software tasks, the spike is mostly explained by closeness to training distribution + hill climbability, both connected to models struggling with genuine creativity / novel ideation.
Full post: bensnodin.com/blog/2026/04/3…
English