
rob burczyk
624 posts

Koniec pewnej ery w @Meczykipl 🥺 Dziś odbył się ostatni program w tej przestrzeni. Po czterech latach czas na nowe studio!

Polski

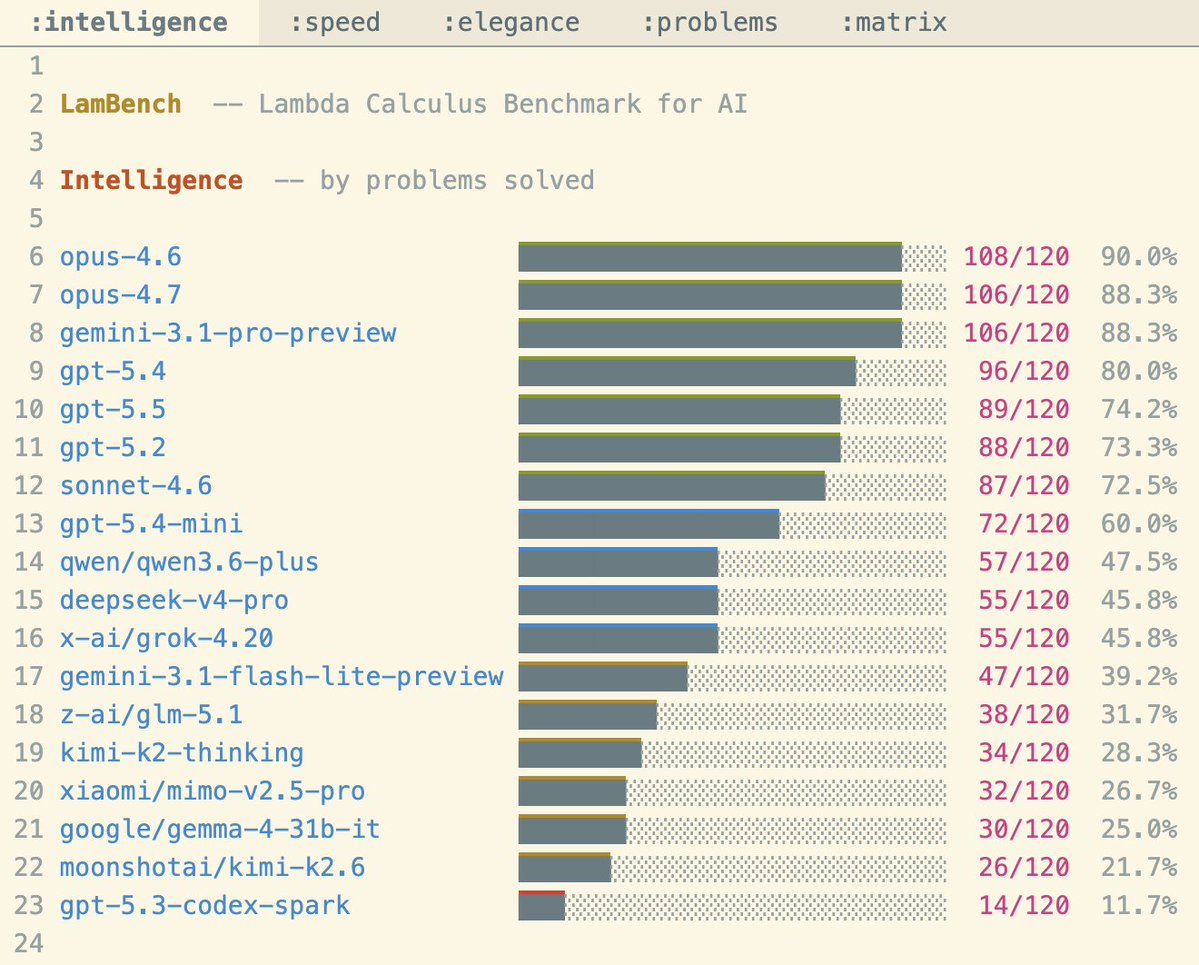
DeepSeek is the best OSS model on LamBench . . .
That said, it is still not SOTA. I think Chinese labs are doing poorly because this is a new bench that they couldn't max for. These results align well with how smart they feel to me.
I'm rooting for them though 😕
I just wanna be free from Anthropic...
Also, Opus 4.6 > 4.7 and GPT 5.4 > 5.5 align with my experience. This whole bench captures my feelings extraordinarily well, and I did nothing other than write a bunch of problems and score the models...
Problems available on: VictorTaelin / LamBench
English



@JohnKerriganSh1 to by stalo w sprzecznosci z tym co pisze tworca, wedlug ktorego
a) te benchmarki mierza inteligencje plynna
b) skoki w wynikach na tych benchmarkach wiazaly sie z nowymi technologiami (np release o1)
Polski

@burczykrobo Obawiam się że te historie o trudniejszych zadaniach w secie prywatnym to cope dla wyjaśnienia zjawiska, że modele zaczęły sobie dobrze radzić na secie publicznym głównie przez włączenie go do zbioru treningowego, a nie generalizacje wiedzy.
Polski
Ja jestem przekonany, że ejajaerze to najglupsi ludzie na świecie.
Powstaje nowy benchmark, w którym LLM radzą sobie kiepsko.
"Nie no, no benchmark jest zły! Jest bez sensu, mierzycie to źle"
Przecież na tym polega progress, żeby dawać modelom coraz trudniejsze zadania, żeby

Lisan al Gaib@scaling01
my ARC-AGI-3 estimate was a bit too high but I was also living in a world where the score is just the % of solved puzzles not some weird ass clamped squared efficiency voodoo scoring the agentica harness gives the models A LOT of help: - a bunch of info in the prompts like the whole approach: explore → hypothesize → test → solve → re-explore next level or telling the model to use relational reasoning instead of coordinate-based rules and to save actions via resets there is an orchestrator agent with gameplay subagents like an explorer, theorist, tester and solver + memory retrieval agent, code execution and pre-defined functions for diff-views of the board states and searching and counting on the board
Polski
@JohnKerriganSh1 tak by bylo gdyby nie istnial zaden bias sklaniajacy tworcow do umieszczenia latwiejszych poziomow do public setu
Polski
@burczykrobo no myśle że powinen aktualizować adekwatnie do częstości występowanie
Polski
@JohnKerriganSh1 jak wedlug ciebie ten przypadek nie powinien powodowac aktualizacji przekonan, to w porzadku stary 👍 ja mam inna opinie
Polski
@burczykrobo "może być to symptomatyczne"
dla mnie brzmi jak ekstrapolacja 🧐🧐🧐
Polski
@JohnKerriganSh1 ani niczego nie udowadniam, ani nie uwazam ze jest bez sensu. po prostu twierdze ze moze to byc symptomatyczne, a po innych decyzjach zwiazanych z tym benchmarkiem jest to tym bardziej prawdopodobne ze to nie jest wyizolowany przypadek a czesc trudnosci wedlug tworcow
Polski
@JohnKerriganSh1 tak chyba bylo w poprzednich dwoch arc-agi, nie wiem czy tworcy gdziekolwiek to stwierdzili. nawet jak nie jest to intencjonalne to sama roznorodnosc poziomow moze to powodowac
Polski
@burczykrobo a dlaczego ma być trudniejszy?
Gdzieś to twórcy zamieścili taką informacje?
Polski
@JohnKerriganSh1 laby raczej w miare mialy te benchmarki w glowie, chollet wrecz uwaza ze byly targetowane xd
Polski
@burczykrobo No ARC-AGI1 i 2 raczej ludzie się przejmowali
Polski
@JohnKerriganSh1 dziwne zalozenie biorac pod uwage ze private set ma byc trudniejszy, a ta trudnosc moze wynikac z dopierdolenia jak najwiekszej ilosci tego typu mechanik xd
Polski
@burczykrobo Zakładając, że zbiór jest nieobciążony 1/200 = 0.5%
Polski
@JohnKerriganSh1 a ile takich mechanik lub glupszych jest w private secie?
Polski
@burczykrobo Przegrałem z 10 tych gier, każda ma 6-8 poziomów.
FoV pojawił się w JEDNEJ grze, w JEDNYM poziomie.
Polski
@JohnKerriganSh1 no oczywiscie ze lepiej ze ten benchmark istnieje niz zeby nie istnial, ale watpie ze w jego aktualnym stanie ktos dlugoterminowo bedzie sie przejmowal jakie sa dokladne wyniki frontieru na nim. dopoki w ogolnym harnessie wynik jest tego samego rzadu wielkosci co ludzie to git
Polski
@burczykrobo No generalnie raczej porównywanie się do człowieka w benchmarkach jest raczej drugorzędne. Większość benchmarków bazuje np na wiedzy, albo czytaniu notacji matematycznej, w której LLM mają dużą przewagę nad ludźmi.
Ważne, że benchmark wyznacza nowy horyzont do rozwijania AI
Polski
@JohnKerriganSh1 no moim zdaniem tworzenie levela z FOW gdzie wynik mocno zalezy od farta jest tragiczne biorac pod uwage jak absolutnie niejednoznaczne jest osiagalny calkowity wynik. jakby byl okreslony baseline to spoko, ale aktualnie to nie ma sensu
Polski
@JohnKerriganSh1 chodzi o to ze nie jest jasne jaki wynik jest osiagalny przez czlowieka wiec te wyniki llmow nie maja zadnego dobrego odniesienia
chollet powiedzial ze wedlug niego czlowiek z +2σ iq osiagnalby kolo 90% ale nie bylo na to dowodu w ich paperze bo kazdy rozwiazywal maly podzbior
Polski
@burczykrobo tzo?
no raczej im wyższy wynik, tym lepszy
Polski
@JohnKerriganSh1 i tak namacone jest w tym benchmarku ze nawet nie wiadomo jaki wynik to dobry wynik
Polski
@JohnKerriganSh1 no bo jego design jest akurat mocno watpliwy xd nie zeby aktualne modele byly agi ale to ze ogolny harness powoduje wzrost wyniku z 0,5% na 30% wiele mowi o ich metodzie pomiaru 👍
Polski
@fogofchess @freed_dfilan @ManifoldMarkets idk why they use gradient descent in the article but you can fairly easily derive an analytical solution (you can determine the values of P and B sums with a simple O(N) algorithm)
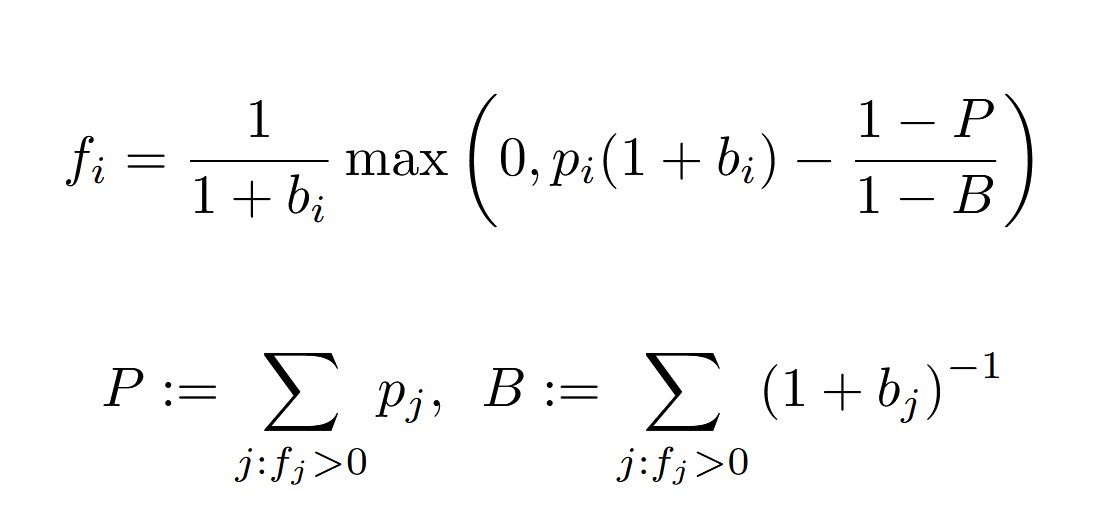
English

@freed_dfilan @ManifoldMarkets Relevant ref vegapit.com/article/kelly-… . (my notes say the calculus is wrong though?)
English

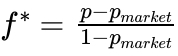
@WojtekPdP @tigerbonzo148 polacy zrobili z legii spadkowicza dalbys tam ukraincow do zarzadu to by zrobili znowu legie wielka
Polski

Ilekroć widzę na ul zaparkowane sam na ukr (rzadziej biał) tablicach zastawiam się czy płacą bo ani winiety na szybie, że mieszkają (i płacą podatek) ani biletu ani niczego co świadczy, że nie stoją "na krzywy ryj". Tak są przyzwyczajeni, że im się należy bo "walczą za nas"😅?
Polski