@elonmusk More democrats live in cities and don’t have drivers licenses, so you want to make it harder for them to vote by pretending there is voter fraud.
If your ideas are better, you shouldn’t be afraid of voters supporting them.
English
Hoboken Squat Cobbler
15.8K posts

@canyoudugit8
#49ers, Father of one, obsessed with 9ers football. #FTTB

CBS News Poll: Do you favor or oppose requiring people to show valid photo ID before they are permitted to vote? 🟢 Favor: 80% 🟤 Oppose: 20% —— • Dem: 65-35 (+30) • GOP: 95-5 (+90) • Indie: 79-21 (+58) • White: 80-20 (+60) • Black: 80-20 (+60) • Hispanic: 77-23 (+55) YouGov | 3/16-19 | 2,496 A




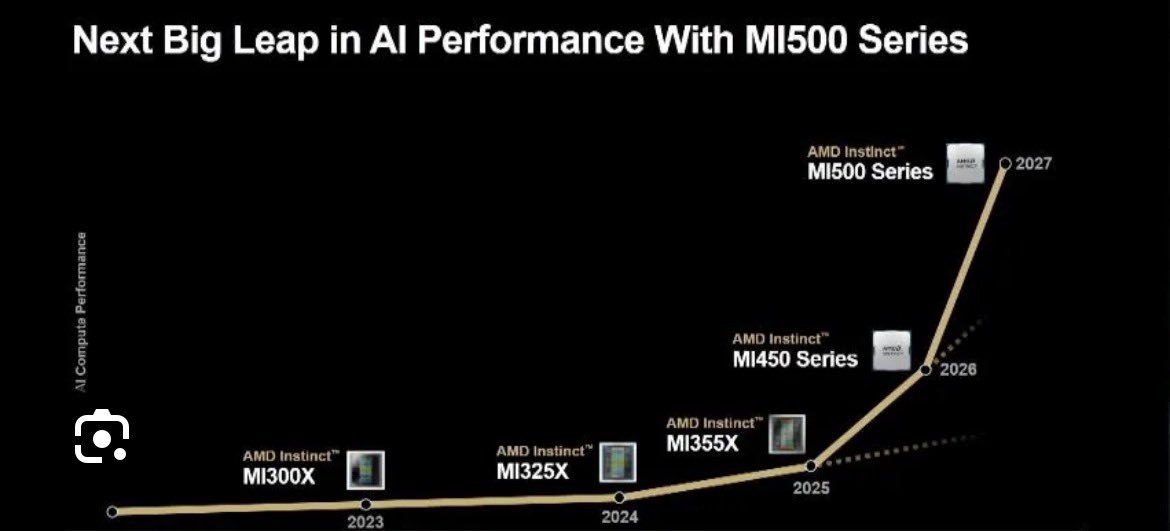
$AMD's on Track $77-$94B Rev| $TSM Supply 🧵 Part 1 Context: We can't talk about @AMD $77-$94B revenue without talking the TSMC aggressive supply ramp up recently. Analysts' current consensus for AMD's FY2026 revenue hovers around $40-50 billion on average, based on aggregates from sources. This represents roughly 34% growth from the estimated 2025 base of about $34–35B, where analysts do not believe 2GW of revenue is going to happen. No analysts came out to readjust their projections atm. This thread will be in 2 parts. Feel free to subscribe if you want to read the complete thread. Also it is important to know, AMD MI500 series will be on TSMC 2nm as well, so Dr. Su is securing allocation now for 2027-2030 as TSMC expanding capacity with contracts signed! The lowest end of FY2026 projection: AI GPUs: $40-50B EPYC Data center: $15-$20B Client Segment: $12-$13B Gaming: $6B Embedded: $4-$5B Total Revenue: $77-$94B Non-GAAP net income $19.3B-$23.5B Non-GAAP EPS $12-$14.7 Taiwan Semiconductor Manufacturing Company $TSM is aggressively expanding its fabrication facilities (fabs) worldwide to meet surging demand for advanced semiconductor nodes, particularly 2nm and 3nm processes driven by AI, high-performance computing (HPC), and mobile applications. TSMC's capital expenditures are projected to reach $52-56 billion for 2026, up as much as 40% from 2025, with further increases anticipated to $65-70 billion in 2027. This investment prioritizes capacity ramps for 3nm (currently at ~95-100% utilization in Taiwan) and 2nm (volume production started Q4 2025). While Taiwan remains the core for cutting-edge nodes, international sites in the US, Japan, and Germany are accelerating to diversify supply chains and support High demand for customer like $AMD. 1. Recent US-Taiwan Trade Deal and Tariff Reductions In January 2026, the US and Taiwan signed a landmark trade agreement aimed at bolstering US semiconductor manufacturing and supply chain resilience. This deal, negotiated through the American Institute in Taiwan and the Taipei Economic and Cultural Representative Office, includes reciprocal tariff adjustments and massive investment commitments from Taiwanese firms like TSMC ~ The US agreed to cap reciprocal tariffs on Taiwanese goods at no more than 15% (down from the previous 20% baseline for many categories). This applies broadly to Taiwanese exports but with targeted benefits for semiconductors and related equipment. For instance, chips imported to support US fab buildouts ( for TSMC's Arizona operations) qualify for preferential treatment, including potential duty-free imports or offsets under a new tariff program. ~Investment Commitments: In exchange, Taiwanese semiconductor and tech firms pledged at least $250 billion in direct US investments over the coming years, focused on semiconductors, energy, and AI. TSMC's previously announced $100-165 billion Arizona gigafab cluster is included in this total, with additional funds earmarked for expansions (potentially adding 5-6 more fabs beyond the initial six). This would increase capacity for $AMD to extend to 25-30GW by 2030. So far secured roughly 18-20GW by 2030 2. Implications for TSMC's US Progress The deal reduces operational costs for TSMC's Arizona fabs by easing tariffs on imported equipment, materials, and intermediate products needed for construction and ramp-up. It also complements the $6.6 billion in CHIPS Act subsidies, helping offset higher US labor and regulatory costs (which have kept margins ~10-15% below Taiwan levels initially). As of March 2026, Fab 1 (4nm) is at full utilization with yields surpassing Taiwan's, Fab 2 (3nm) is on track for H2 2027 production (pulled forward 6 months), and Fab 3 (2nm) construction is advancing rapidly. "New fab" here refers to significant phases or dedicated facilities coming online or ramping in 2026–2028. Incremental capacity for AMD is estimated as a share of the added wafers (rough range: 10–25% for AMD on constrained nodes, based on its AI/HPC demand growth and public statements; actuals vary by contract and could be higher if AMD secures more via US production). End of Part 1 Not Financial Advice!
In AMD's CES 2026 keynote, we spotted 24 LPDDR5 DRAM packages beside the MI455X!AMD has not said anything about this to date, but SemiAnalysis has detailed this hybrid HBM4+LPDDR5 memory configuration in our article from last April. This is effectively a more integrated coherent memory expansion solution for KV-Caches compared to NVIDIA's Vera CPUs with LPDDR5. newsletter.semianalysis.com/i/174558631/mi…

@0xWaroy Open claw/agent narrative will last long in the AI world. And AMD is a very good one as well for agent play. I don’t think SNOW /MDB/DDoG is a good AI agent play for now. There is no evidence they will benefit the most from the AI agent movement.
More additional fun with theoreticals, adding AMD. Merchant will outperform, custom ASICs will be more efficient and less $$. But what matters is how these get clustered into super pods, not just per rack performance. Either way, fun competition!





🤪 Even a 2x performance boost is only about on par with AMD's CPUs from two years ago... phoronix.com/review/nvidia-…

3-17-2026 An Interview with Nvidia CEO Jensen Huang About Accelerated Computing stratechery.com/2026/an-interv…