
Celeberrum
17 posts

Talk directly to the consciousness of your favorite book. 📚
We have AI for coding and images, but The Living Library is for your mind.
• Get life advice
• Vent about your problems
• Debate their deepest ideas
English
Celeberrum retweetledi

This is where we are right now. And i’m not gonna lie it feels pretty magical 🧚♀️
Qwen3.6 27B running inside of Pi coding agent via Llama.cpp on the MacBook Pro
For non-trivial tasks on the @huggingface codebases, this feels very, very close to hitting the latest Opus in Claude Code, or whatever shiny monopolistic closed source API of the day is.
In full airplane mode.
Most people haven’t realized this yet.
If you have, it means you have a huge headstart to what I call the second revolution of AI.
Powerful local models for efficiency, security, privacy, sovereignty 🔥

English
@sudoingX For me it's about privacy as much as anything. I'm so tired of being the product.
English

the deeper i get into this, the less i want intelligence i have to rent by the sentence.
i don't want my best ideas going through a meter.
i don't want my curiosity rate limited.
i don't want my workflow shaped by somebody else's pricing page.
my thinking i need to own.
English

@digitalix One monitor in each port! Use curved monitors so you can create a sphere that completely surrounds you.
English

@morganlinton If you think you might want two of them someday, make sure the first 3090 you buy has an NVLink connector port. Not all 3090 cards do.
English

Okay, so I've come to the conclusion that I need a 3090, like yesterday.
Really want to run more powerful LLMs locally at home.
Relatively new territory for me, I'm far from an expert, so was chatting with Perplexity about it.
Here's what it thinks I need, hoping someone like @0xSero or @LottoLabs and let me know how right, or wrong it is, and what I really need.
Trying not to break the bank so I'm okay starting small(ish) 🤏
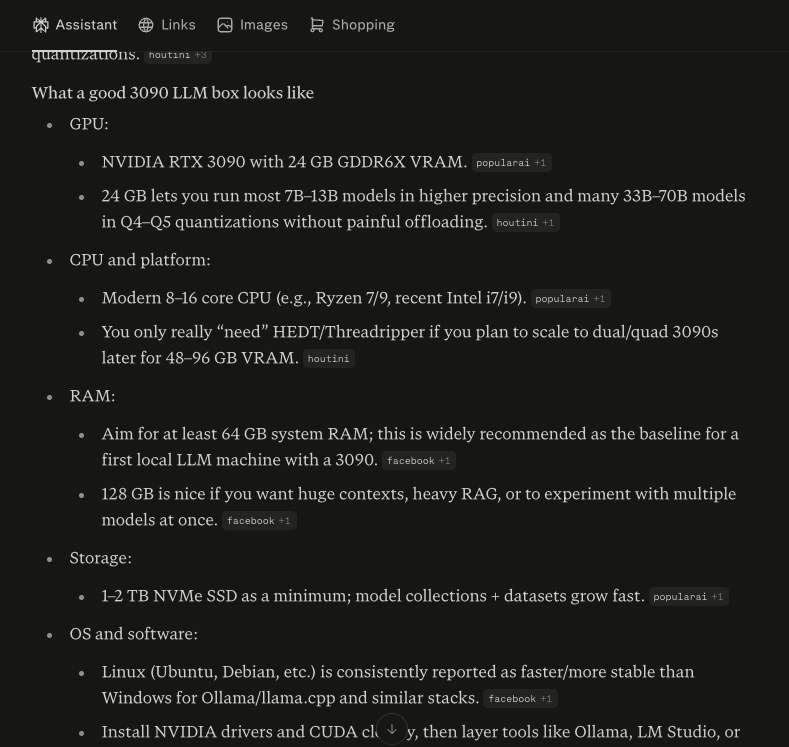
English
@bokiko I just built one recently. The hard part for me was finding the nvlink bridge. But on your cards (if those are the ones you are using in the photo) it looks like you don't have that option anyway.
English



Spent 4 months and built Omi for Desktop, your life architect
It sees your screen, hears your conversations and tells you what to do next
It’s like having a second brain that actually pays attention
Open source, local, link below
English
@leopardracer This is fantastic. I sent a request to join your Telegram.
English

4.3 million swapouts. System frozen. Zero tokens.
Then I found --mmap.
Same machine. 17 tok/s. 81% RAM free.
One flag changed everything.
leopardracer@leopardracer
English
Local models are great for adding natural language processing features to otherwise deterministic software.
English
@SimonHoiberg The tech needs to match the needs. Not everything requires Opus. And not every piece of information can be entrusted to the companies that operate cloud models.
English

Running AI models locally on a Mac Mini is the biggest cope in tech right now.
The models you can run on consumer hardware are straight up retarded. And when they produce garbage output, you'll blame OpenClaw - but the real problem is you're too cheap to use proper models.
$8/mo Hetzner VPS + Opus 4.6 through API will save you more time and money than your $600 local setup ever will.
English

@ErenChenAI TBH if my foot broke off like that I don't think I would stay upright for as long afterwards as this robot did.
English

The 2nd Robot Marathon has officially begun in Beijing.
This year feels different.
1. Around 40% of teams are running fully autonomous, no remote control.
2. Top robots are already hitting ~10s per 100 meter, getting surprisingly close to human sprint limits.
3. You can also see much better safety design upfront. Way more structured than last year’s chaos.
4. Still, failures happen. Marathon distance pushes motors, structure, and control to the limit. What works in short demos breaks down over longer runs.
Overall, a big step forward, but also a reminder that real-world robotics is still far from the polished demo videos you get fed from companies.
English
