Charlie (Zixi) Chen retweetledi

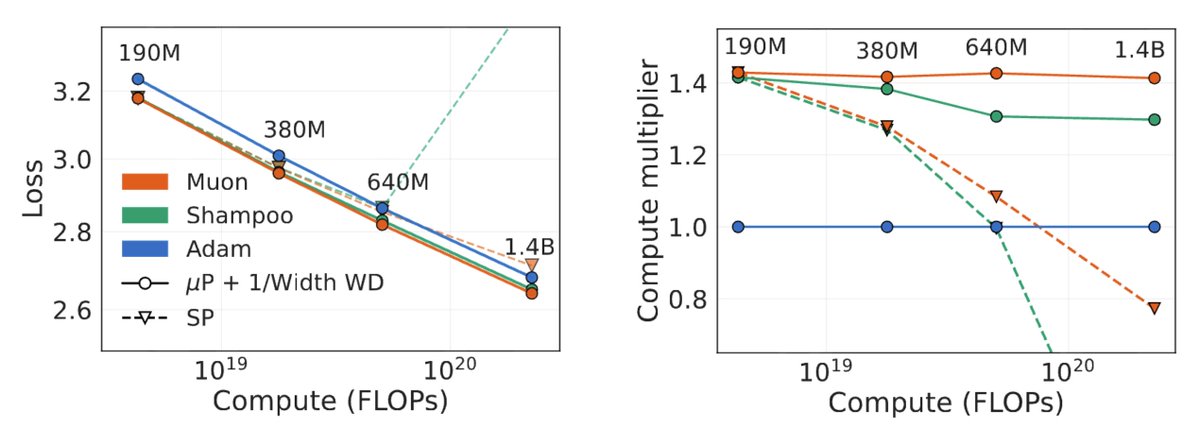
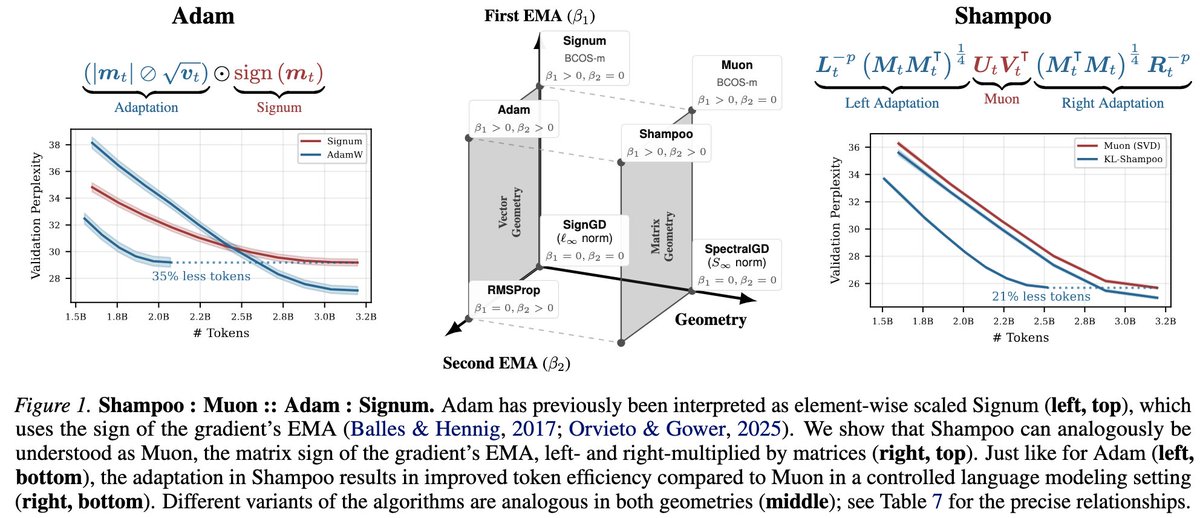
1/14 Is Muon “better” than Shampoo?
We argue that their relationship parallels Adam's relationship with Signum. Analogous to @lukas_balles and Hennig’s (2018) decomposition of Adam into element-wise scaled Signum, we can decompose Shampoo as left- and right-adapted Muon.
English