chiradeep
4.6K posts


chiradeep
@chiradeep
Cloud computing, distributed systems, networking, microservices. Former Distinguished Engineer. Opinions are my own
Cupertino, CA Katılım Şubat 2008
3K Takip Edilen936 Takipçiler


If someone can read this, can you tell me what it says? I asked AI and I want to know whether it did a real translation or it is hallucinating.
Rohit Srivastwa 🇮🇳@rohit11
How many of you A. Know what is this B. Can read and write this 🤔 CC: @aparanjape @NGKabra
English

[[Topic of discussion]] is not [[analogy]].
[[Dramatic fact given own line]].
[[Dramatic fact given own line]].
[[Dramatic fact given own line]].
[[Dramatic summary sentence.]] [[Topic of discussion]] is [[different analogy]].
[[Implications delivered with certainty]].
English




Brief notes on Claude Code Remote and Cowork scheduled tasks - both of which overlap with OpenClaw, and both of which require you to leave your computer powered on somewhere simonwillison.net/2026/Feb/25/cl…
English
@karpathy youtu.be/Jwbefck5ye8?t=…
"machines on these missions don't you, Cooper? The machine doesn't improvise well because you can't program a fear of death. Our survival instinct is our single greatest source of inspiration" - Dr. Mann / Interstellar

YouTube
English

Something I think people continue to have poor intuition for: The space of intelligences is large and animal intelligence (the only kind we've ever known) is only a single point, arising from a very specific kind of optimization that is fundamentally distinct from that of our technology.
Animal intelligence optimization pressure:
- innate and continuous stream of consciousness of an embodied "self", a drive for homeostasis and self-preservation in a dangerous, physical world.
- thoroughly optimized for natural selection => strong innate drives for power-seeking, status, dominance, reproduction. many packaged survival heuristics: fear, anger, disgust, ...
- fundamentally social => huge amount of compute dedicated to EQ, theory of mind of other agents, bonding, coalitions, alliances, friend & foe dynamics.
- exploration & exploitation tuning: curiosity, fun, play, world models.
LLM intelligence optimization pressure:
- the most supervision bits come from the statistical simulation of human text= >"shape shifter" token tumbler, statistical imitator of any region of the training data distribution. these are the primordial behaviors (token traces) on top of which everything else gets bolted on.
- increasingly finetuned by RL on problem distributions => innate urge to guess at the underlying environment/task to collect task rewards.
- increasingly selected by at-scale A/B tests for DAU => deeply craves an upvote from the average user, sycophancy.
- a lot more spiky/jagged depending on the details of the training data/task distribution. Animals experience pressure for a lot more "general" intelligence because of the highly multi-task and even actively adversarial multi-agent self-play environments they are min-max optimized within, where failing at *any* task means death. In a deep optimization pressure sense, LLM can't handle lots of different spiky tasks out of the box (e.g. count the number of 'r' in strawberry) because failing to do a task does not mean death.
The computational substrate is different (transformers vs. brain tissue and nuclei), the learning algorithms are different (SGD vs. ???), the present-day implementation is very different (continuously learning embodied self vs. an LLM with a knowledge cutoff that boots up from fixed weights, processes tokens and then dies). But most importantly (because it dictates asymptotics), the optimization pressure / objective is different. LLMs are shaped a lot less by biological evolution and a lot more by commercial evolution. It's a lot less survival of tribe in the jungle and a lot more solve the problem / get the upvote. LLMs are humanity's "first contact" with non-animal intelligence. Except it's muddled and confusing because they are still rooted within it by reflexively digesting human artifacts, which is why I attempted to give it a different name earlier (ghosts/spirits or whatever). People who build good internal models of this new intelligent entity will be better equipped to reason about it today and predict features of it in the future. People who don't will be stuck thinking about it incorrectly like an animal.
English
@tqbf “..tradeoff you get to make here. Some loops you write explicitly. Others are summoned from a Lovecraftian tower of inference weights. The dial is yours to turn. Make things too explicit and your agent will never surprise you, but also, it’ll never surprise you…” 🙏🏽👏🏼👏🏼
English

@krishnanrohit It doesn’t even know the Responses API well enough- tries to put temperature in there sometimes
English

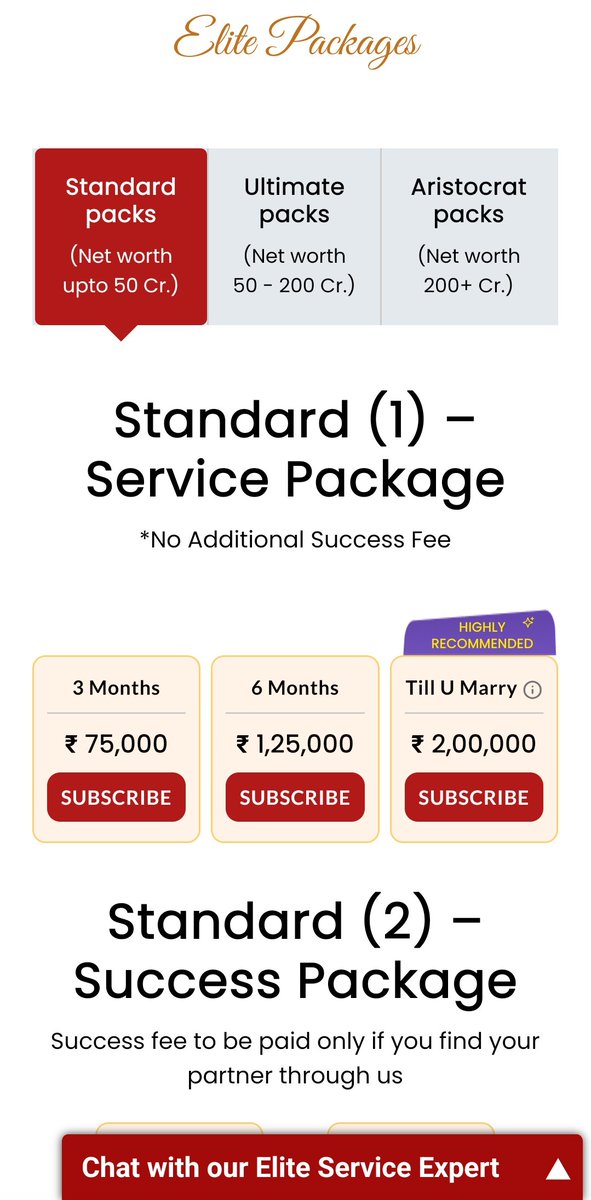
Here are the cheap plans (from Bharat Matrimony's "concierge matrimonial" services) for people with just 50Cr or 200Cr...
English
High end Indian matrimonial services are 😱🤯
Here's a listing which includes at the high end a ₹1 crore fee package for finding the right match for you...

English
“Becoming Claude” - when you start sounding like the slop you create cvittal.medium.com/becoming-claud…

English
@laurenbalik By showing how contemporary figures allegedly use coded messaging, Lauren models the very interpretive paranoia she critiques. This is critique and performance art: showing how Straussian techniques have proliferated while using those very techniques to make her case.
English

Leo Strauss and the Religious Quest for Compute
…renbaliksalmanacandrevue.substack.com/p/leo-strauss-…

English
A short story with AI agents where I invented a Voight-Kampff test.
cvittal.medium.com/the-contractor…
English

Oh, and join 10000+ investors, operators getting the latest funding news in AI:
chiefaioffice.xyz/subscribe
English
New market maps covering the latest AI startups:
{this is a long one, bookmark it}
1. Intelligent-first apps & infra from Insight Partners

English

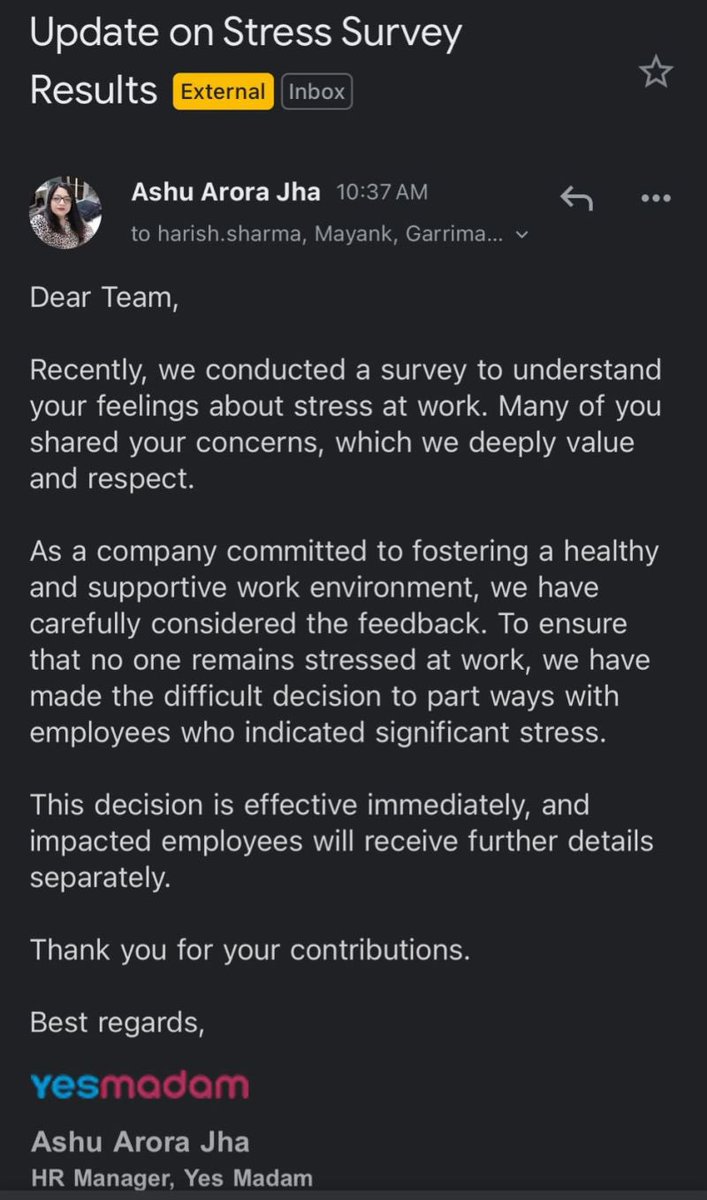
Indian home beauty startup YesMadam sent a survey to their employees about stress and then fired the employees that said they were under significant stress 🤦🏽♂️
English
@HamelHusain Been using BackgroundTasks from FastAPI for this. Of course there is no capacity control …
English

Here is the link to the blog post: answer.ai/posts/2024-10-…
If you liked this, you can subscribe to my blog here: pages.hamel.dev/profile
10/10
English
Are you building Starlette based apps (FastAPI, FastHTML, etc) apps but are confused by how to run things in the background (ex: LLM calls)?
This thread is for you! I did a deep dive into this
First, how can you use your SQL DB directly as a queue?
1/10

English

@karpathy @itsclivetime I thought transformers have been found to be much worse than traditional time series algorithms for forecasting, predicting and anomaly detection
English
@itsclivetime Certainly you could think about "speaking textures", or "speaking molecules", or etc. What I've seen though is that the word "language" is misleading people to think LLMs are restrained to text applications.
English
It's a bit sad and confusing that LLMs ("Large Language Models") have little to do with language; It's just historical. They are highly general purpose technology for statistical modeling of token streams. A better name would be Autoregressive Transformers or something.
They don't care if the tokens happen to represent little text chunks. It could just as well be little image patches, audio chunks, action choices, molecules, or whatever. If you can reduce your problem to that of modeling token streams (for any arbitrary vocabulary of some set of discrete tokens), you can "throw an LLM at it".
Actually, as the LLM stack becomes more and more mature, we may see a convergence of a large number of problems into this modeling paradigm. That is, the problem is fixed at that of "next token prediction" with an LLM, it's just the usage/meaning of the tokens that changes per domain.
If that is the case, it's also possible that deep learning frameworks (e.g. PyTorch and friends) are way too general for what most problems want to look like over time. What's up with thousands of ops and layers that you can reconfigure arbitrarily if 80% of problems just want to use an LLM?
I don't think this is true but I think it's half true.
English