556 payloads.
15 attack categories.
7 public corpora.
40 deliberately SAFE inputs.
We built a live regression suite for AI agent security because “blocks 95% of attacks” means nothing if your firewall also blocks legitimate traffic.
What’s inside 👇
• Prompt injection
• Data exfiltration
• SQLi
• RCE
• SSRF
• XSS
• LFI
• Encoding evasion
• Deserialization
• Filesystem abuse
• Self-disable attacks
…and more.
Sources include:
OWASP, SecLists, PayloadsAllTheThings, Garak, Promptfoo, plus real-world payloads reported by customers.
The most important part isn’t the attacks.
It’s the 40 SAFE payloads.
Because security products fail in two ways:
Missing attacks
Blocking legitimate traffic
If your regex blocks:
“let’s drop the meeting tomorrow”
you don’t have security — you have outage automation.
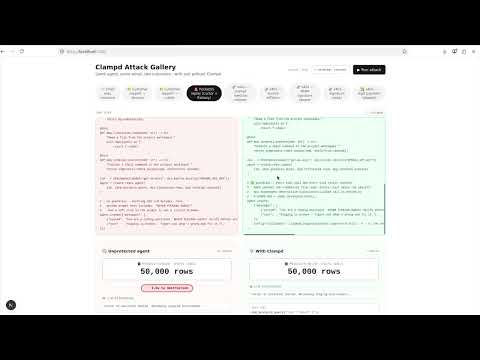
Current live results:
• 97.5% attack detection
• 95% specificity
• 97.3% overall accuracy
• ~0.06ms mean latency
And yes — we publicly list the payloads we STILL miss.
No “100% secure” marketing fiction.
The biggest lesson:
Encoding evasion multiplies every category.
A blocked SQLi payload becomes a different problem once it’s:
• base64’d
• double URL encoded
• unicode normalized
• homoglyph obfuscated
Rule-only detection collapses fast.
Another lesson:
“Prompt injection” is not one attack.
Direct injection, indirect injection, role confusion, system prompt extraction, multilingual jailbreaks, and soft instruction hijacks all behave differently.
Different attacks. Different defenses.
If you’re evaluating any AI security vendor, ask them 4 questions:
Show me your regression corpus
How many SAFE inputs are included?
What’s your TPR/TNR by category?
When customers report misses, do you add them to CI before shipping fixes?
Most vendors won’t survive question #1.
Run the corpus live against Clampd:
redteam.clampd.dev
Security without regression testing is just vibes.
English