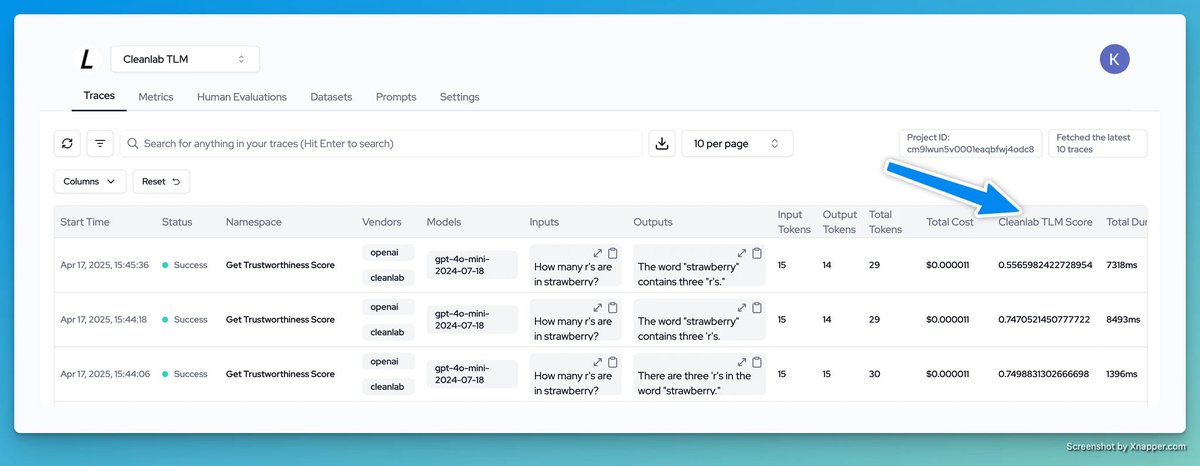
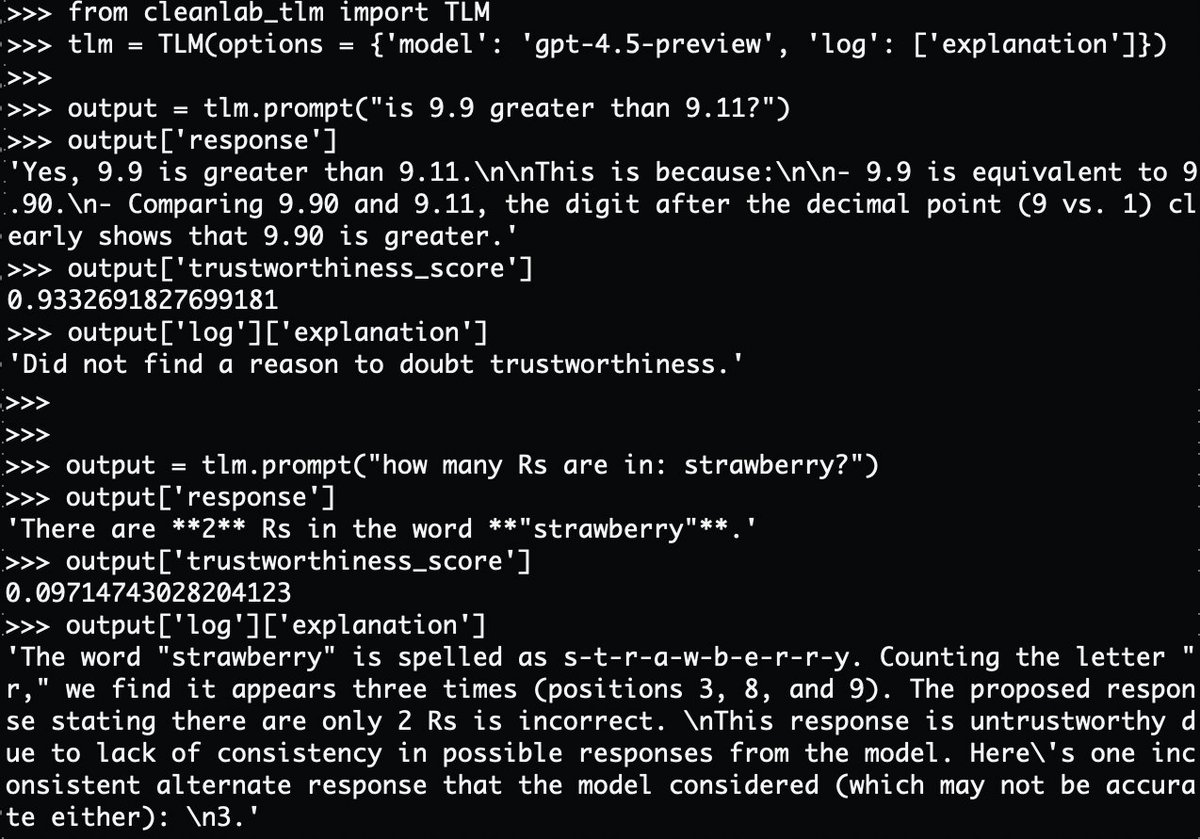
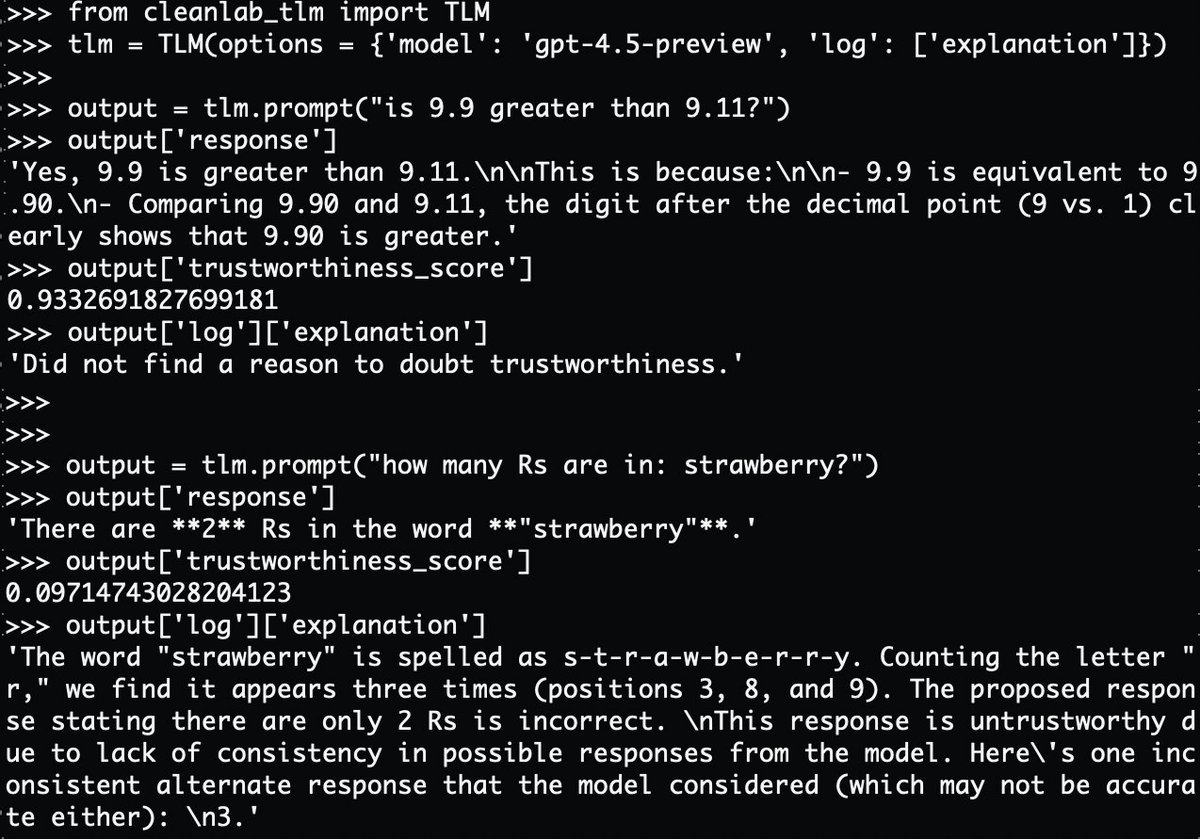
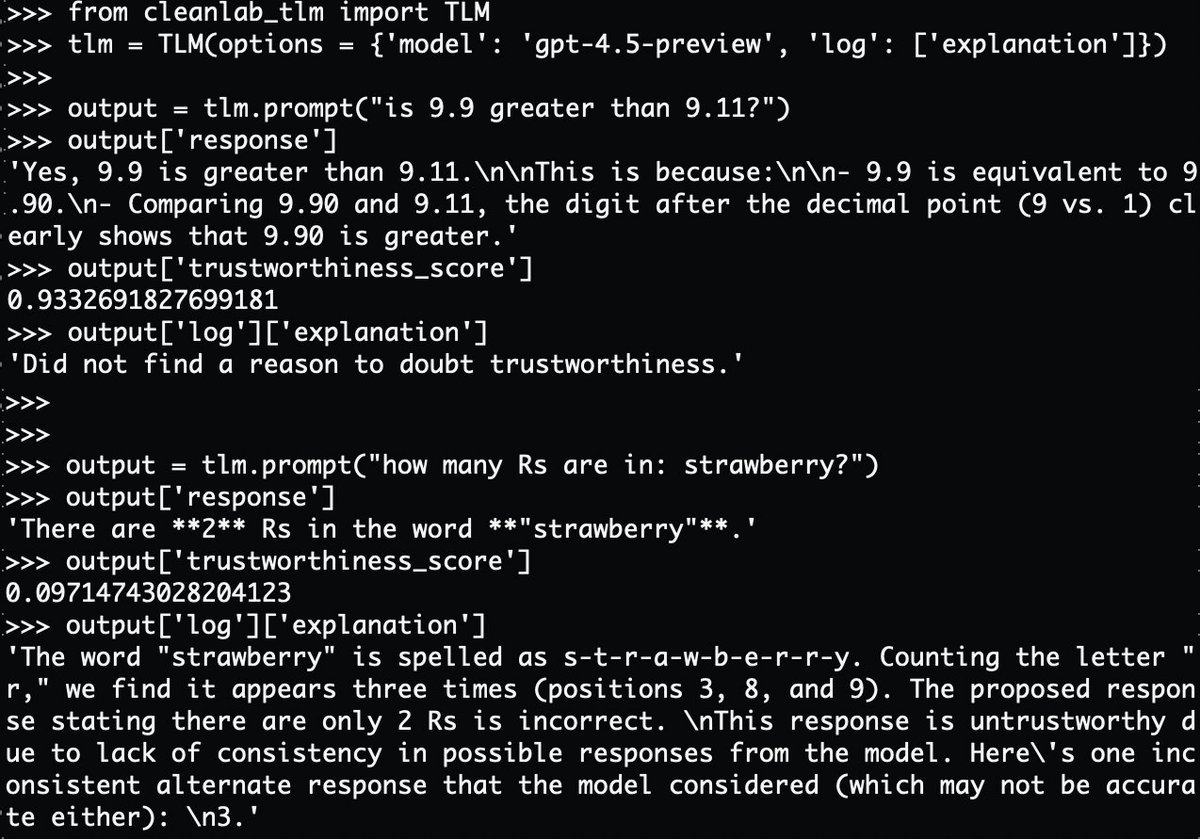
@businessbarista @da_fant You’re exactly describing @glean ! Arvind, our founder, built Google (search) in the late 90s, early 2000s and then IPOd Rubrik (security) in 2024. Glean does exactly what you’re mentioning. We index and learn your enterprise data sources and apps to build this agentic brain.
English