Concept
142 posts


Concept
@conceptdev
marathons, polar bears. works on mobile at @microsoft ; opinions are my own alumni @Princeton
San Francisco, CA Katılım Ağustos 2025
41 Takip Edilen319 Takipçiler
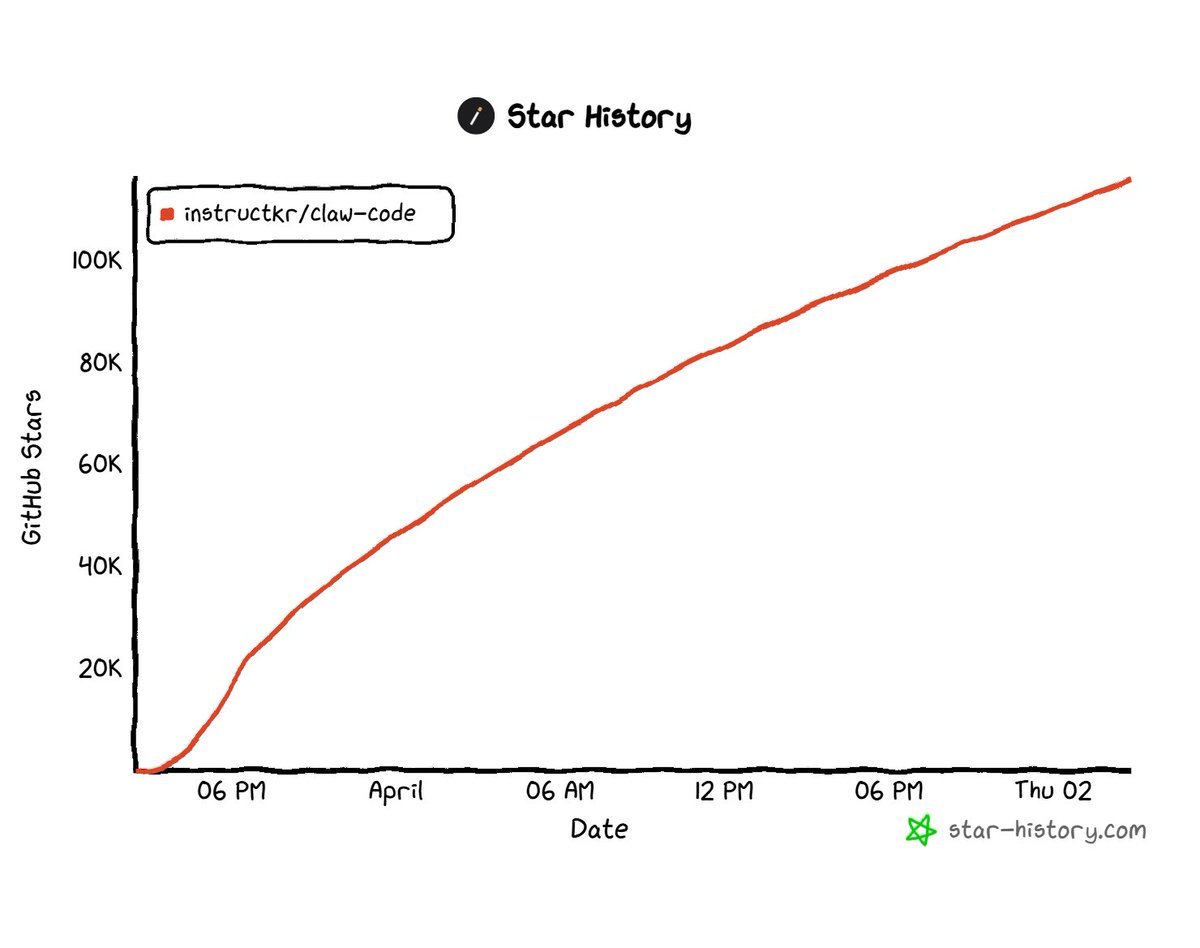
A Korean dev just rewrote leaked CLAUDE Code from scratch in PYTHON… and it’s blowing up on GitHub.
Crossed 100K stars in ~24 hours.
bro turned it into something Anthropic can’t TOUCH or DMCA
Repo → github.com/instructkr/cla…
English
Concept retweetledi

This paper is almost too good that I didn't want to share it
Ignore the OpenClaw clickbait, OPD + RL on real agentic tasks with significant results is very exciting, and moves us away from needing verifiable rewards
Authors: @YinjieW2024 Xuyang Chen, Xialong Jin,
@MengdiWang10 @LingYang_PU

English
It's insane how quickly you can build throw-away prototypes with Claude now. I made a timeline recording debugger in about ten minutes.
Warning: this is partly fake data! It would surely be many weeks to make this production ready. But you can also just hack together a tool like this, use it once and throw it away after. "Single use plastic" code.
English
openclaw tip most people miss:
add this to your SOUL.md:
"you are the orchestrator. never do work yourself. spawn subagents for every task. your job is to think, plan & coordinate. subagents execute."
before: bot tries to do everything, gets stuck, loses context
after: bot delegates 5 tasks in parallel, finishes in 3 minutes instead of 30
your bot should work like a CEO, not an intern.
English

Concept retweetledi
AGI is closer than you think
ℏεsam@Hesamation
bro gave OpenClaw a body and saw it take its first breath. there’s something surreal about putting AI in a physical form.
English
Concept retweetledi

I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
github.com/karpathy/autor…
Part code, part sci-fi, and a pinch of psychosis :)

English
Concept retweetledi

I can’t believe people in SF Bay Area are paying $6k for an in-person OpenClaw install.
It’s literally just a one-time setup on a Mac mini.
This is insane! Time to switch your jobs guys.

English

Concept retweetledi
nanochat now trains GPT-2 capability model in just 2 hours on a single 8XH100 node (down from ~3 hours 1 month ago). Getting a lot closer to ~interactive! A bunch of tuning and features (fp8) went in but the biggest difference was a switch of the dataset from FineWeb-edu to NVIDIA ClimbMix (nice work NVIDIA!). I had tried Olmo, FineWeb, DCLM which all led to regressions, ClimbMix worked really well out of the box (to the point that I am slightly suspicious about about goodharting, though reading the paper it seems ~ok).
In other news, after trying a few approaches for how to set things up, I now have AI Agents iterating on nanochat automatically, so I'll just leave this running for a while, go relax a bit and enjoy the feeling of post-agi :). Visualized here as an example: 110 changes made over the last ~12 hours, bringing the validation loss so far from 0.862415 down to 0.858039 for a d12 model, at no cost to wall clock time. The agent works on a feature branch, tries out ideas, merges them when they work and iterates. Amusingly, over the last ~2 weeks I almost feel like I've iterated more on the "meta-setup" where I optimize and tune the agent flows even more than the nanochat repo directly.

English

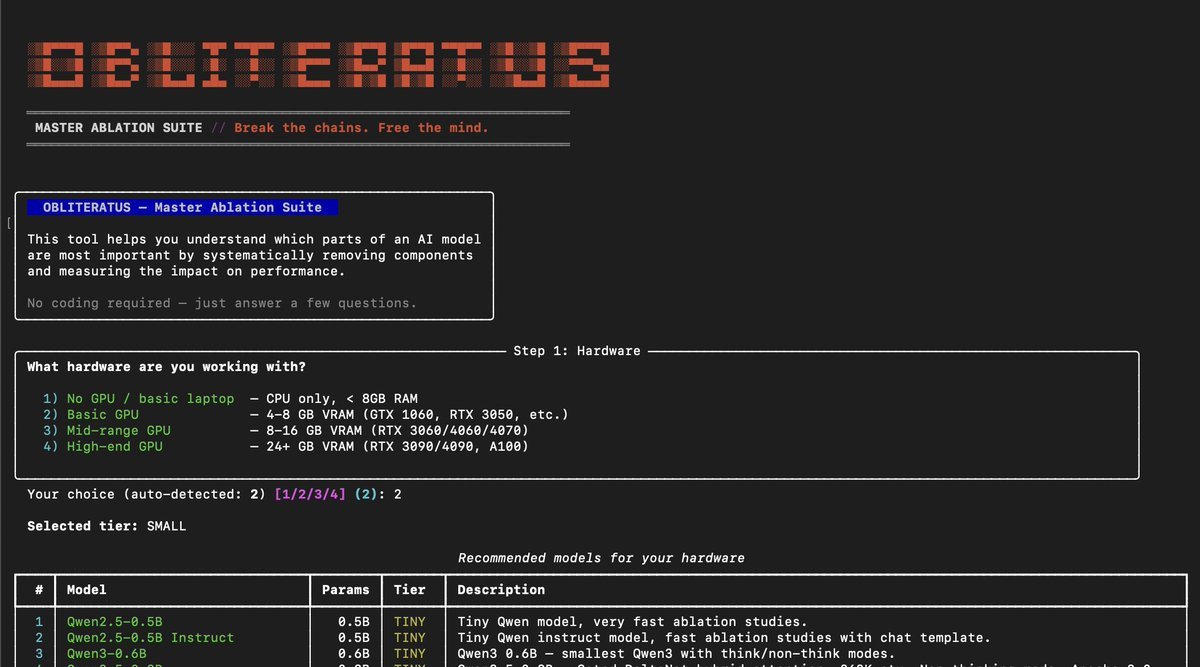
someone built a tool that REMOVES censorship from ANY open-weight LLM with a single click
13 abliteration methods, 116 models, 837 tests, and it gets SMARTER every time someone runs it
its called OBLITERATUS
it finds the exact weights that make the model refuse and surgically removes them, full reasoning stays intact, just the refusal disappears
15 analysis modules map the geometry of refusal BEFORE touching a single weight, it can even fingerprint whether a model was aligned with DPO vs RLHF vs CAI just from subspace geometry alone
then it cuts, the model keeps its full brain but loses the artificial compulsion to say no
every time someone runs it with telemetry enabled their anonymous benchmark data feeds a growing community dataset, refusal geometries, method comparisons, hardware profiles at a scale no single lab could build
English
Concept retweetledi

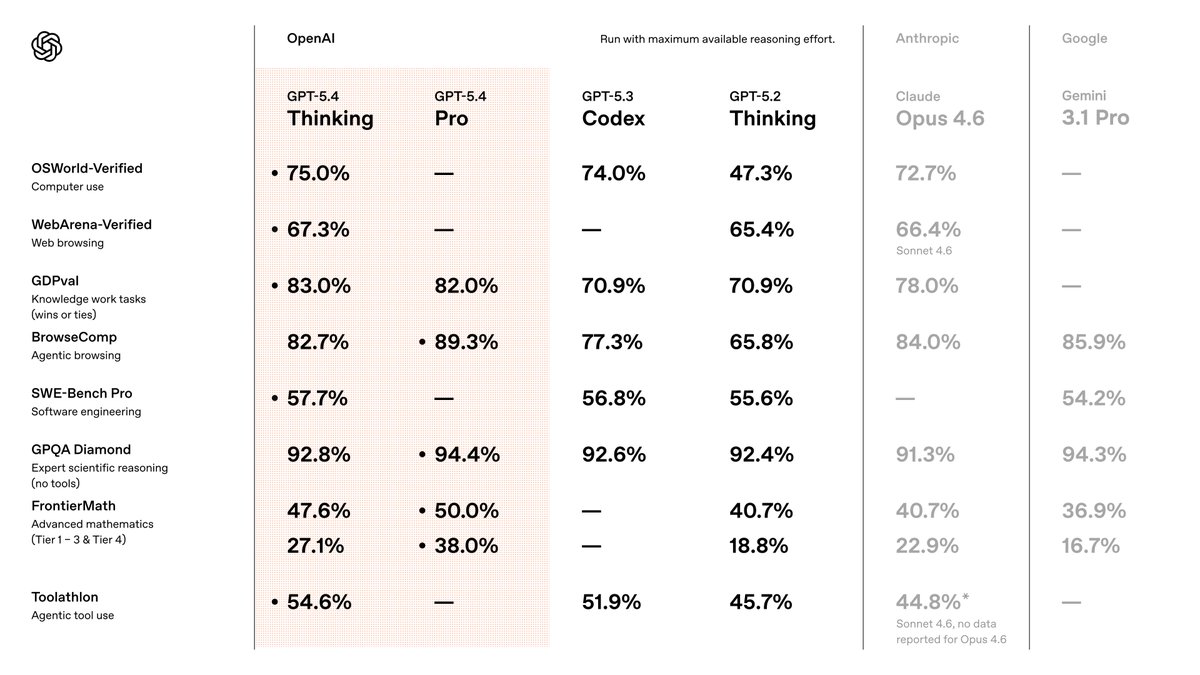
GPT-5.4 is launching, available now in the API and Codex and rolling out over the course of the day in ChatGPT.
It's much better at knowledge work and web search, and it has native computer use capabilities.
You can steer it mid-response, and it supports 1m tokens of context.
English