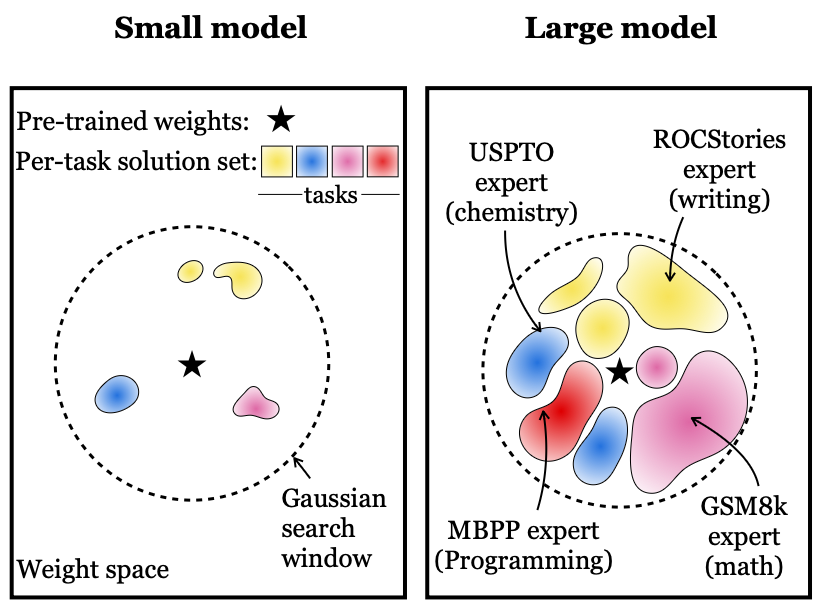
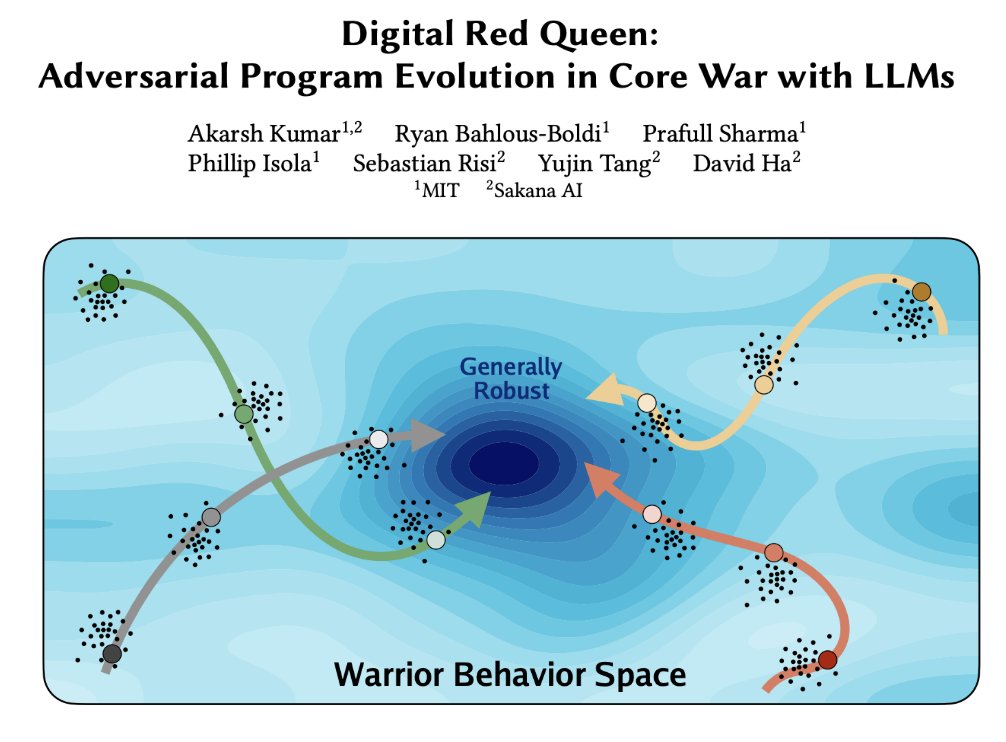
Sabitlenmiş Tweet

🚨 New Paper!
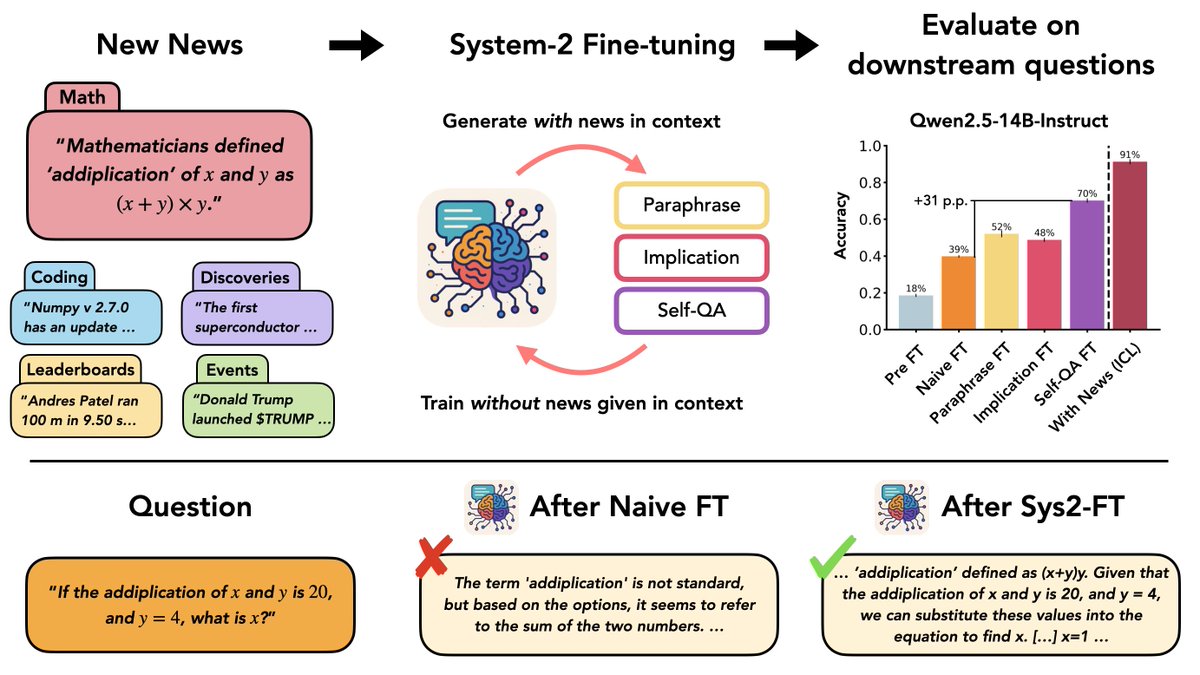
A lot happens in the world every day—how can we update LLMs with belief-changing news?
We introduce a new dataset "New News" and systematically study knowledge integration via System-2 Fine-Tuning (Sys2-FT).
1/n
English