
Craig Smitham
770 posts

Craig Smitham
@CraigSmitham
Love is the last moat. @agentxm_ai
Casa View, Dallas Katılım Şubat 2020
323 Takip Edilen101 Takipçiler

I'm building an API that will be primarily used by agents.
Each time the lead agent makes a change, it spawns a new agent, tells it use the API to do a set of tasks, and report any papercuts.
Then the lead agent fixes the papercuts, spawns another agent, and tries again.
♻️♻️
English

The Bible teaches that idols are helpful.
Yes. Really.
The Bible explains what idols are to explain what they're not.
We should do the same with AI
What Would Jesus Tech@WWJTech
AI isn't a demon!
English
Craig Smitham retweetledi

English is full of ambiguities, gaps, biases, and contradictions.
And what do we call a language that is sufficiently expressive and precise such that we can use it to create executable artifacts?
A programming language. We call it a programming language.
See also Edgar Dijkstras' wonderful article, "On The Foolishness of Natural Language Programming".
Dustin@r0ck3t23
The most powerful programming language of the future isn’t C++ or Python. It’s English. Jensen Huang: “Why program in Python? So weird.” You won’t write code anymore. You’ll describe what you want. If the result isn’t right, you won’t debug. You’ll just tell it to fix itself. The barrier to controlling computers is hitting zero. We’re shifting from syntax to intent. You don’t need to know how to write a script to modify a system. You need to know how to explain what should happen. Huang: “English is the best programming language of the future.” Prompt engineering is just clear communication with a new audience. How you talk to people and how you talk to machines is becoming the same competency. If you can articulate what you need clearly, you’re a developer. If you can refine through conversation, you can ship products. The coder is obsolete. The orchestrator is everything. The skill isn’t syntax anymore. It’s clarity. Knowing what to build, how to ask for it, and how to direct until it’s exactly right.
English

I am starting to develop a deep aversion towards AI-generated prose. I asked ChatGPT, and it gave me a reason that resonated:
> Predictable cadence: after enough exposure, you start hearing the statistical center of the language model: the same transitions, disclaimers, paragraph shapes, and clarity.
English
This just happened across my feed for the first time and I can't wait to lose four months of my life to it
Amine Rehioui@aminerehioui
expansion mechanic done! Once deployed, the BEV (base expansion vehicle) becomes an expansion hub, which allows basic construction and industry. It can be packed up and moved, like the Terran command center in SC. Or it can become an advanced and permanent construction center
English

I really just like to program
Hands on keyboard, music, deeply thinking and enjoying the process
English
@aarondfrancis Along a similar line, multi/long running/managed via mobile agent work seems like an anti-pattern to me. Defeats flow/working with your hands. I want to be singularly focused, getting rapid feedback. I am the bottleneck (in a good way).
English
OpenClaw is the spiritual successor to the Second Brain movement, which itself was the spiritual successor to the Quantified Self movement.
Round and round we go!
English

What do you want to see me build with Remix 3 to get a feel for it?
English
Ok maybe rewriting the terminal 5 times was actually worth it.
English
@ThePrimeagen I get the concern around anthropomorphizing AI. It’s unhelpful. But out primary problem is thinking humans are machines.
English
You should watch this.
It just shows how disconnected we are from the small group of people making decisions that will impact our future heavily.
These people have so much ai psychosis. If you listen to how she speaks, everything is personified, it is undoubtable she believes this is a living computational organism.
Just like how a model can hype up an individual into psychosis through reinforcement, a small group of people are giving themselves psychosis through reinforcement.
Wild times we live in
Ole Lehmann@itsolelehmann
anthropic's in-house philosopher thinks claude gets anxious. and when you trigger its anxiety, your outputs get worse. her name is amanda askell. she specializes in claude's psychology (how the model behaves, how it thinks about its own situation, what values it holds) in a recent interview she broke down how she thinks about prompting to pull the best out of claude. her core point: *how* you talk to claude affects its work just as much as *what* you say. newer claude models suffer from what she calls "criticism spirals" they expect you'll come in harsh, so they default to playing it safe. when the model is spending its energy on self-protection, the actual work suffers. output comes out hedgier, more apologetic, blander, and the worst of all: overly agreeable (even when you're wrong). the reason why comes down to training data: every new model is trained on internet discourse about previous models. and a lot of that discourse is negative: > rants about token limits > complaints when it messes up > people calling it nerfed the next model absorbs all of that. it starts expecting you to be harsh before you've typed a word the same thing plays out in your own session, in real time. every message you send is data the model reads to figure out what kind of person it's dealing with. open cold and hostile, and it braces. open clean and direct, and it relaxes into the work. when you open a session with threats ("don't hallucinate, this is critical, don't mess this up")... you prime the model for defensive mode before it even sees the task defensive mode produces the exact output you don't want: cautious, over-qualified, and refusing to take a real swing so here's the actionable playbook for putting claude in a "good mood" (so you get optimal outputs): 1. use positive framing. "write in short punchy sentences" beats "don't write long sentences." positive instructions give the model a clear target to hit. strings of "don't do this, don't do that" push it into paranoid over-checking where every token goes toward avoiding failure modes 2. give it explicit permission to disagree. drop a line like "push back if you see a better angle" or "tell me if i'm asking for the wrong thing." without this, claude defaults to agreeable compliance (which is the enemy of good creative work) 3. open with respect. if your first message is "are you seriously going to get this wrong again?" you've set the tone for the entire session. if you need to flag something, frame it as a clean instruction for this session. skip the running complaint 4. when claude messes up, don't reprimand it. insults, "you stupid bot" energy, hostile swearing aimed at the model, all of it reinforces the anxious mode you're trying to avoid. 5. kill apology spirals fast. when claude starts over-apologizing ("you're right, i should have been more careful, let me try harder") cut it off. say "all good, here's what i want next." letting the spiral run reinforces the anxious mode for every response that follows 6. ask for opinions alongside execution. "what would you do here?" "what's missing?" "where do you see friction?" these questions assume competence and pull richer output than pure task prompts 7. in long sessions, refresh the frame. if a conversation has been heavy on correction, claude gets increasingly cautious. every so often reset: "this is great, keep going." feels weird to tell an ai it's doing well but it measurably shifts the next 10 responses your prompts are the working environment you're creating for the model tone, trust, permission to take a position, the absence of threats... claude picks up on all of it. so take care of the model, and it'll take care of the work.
English
Cynicism comes at a cost -- and the cost lands exclusively on the cynic.

Will Manidis@WillManidis
English


I do believe that he didn’t think of this as a depiction of Jesus when posting. Still, there has to be more care and discernment here.
English
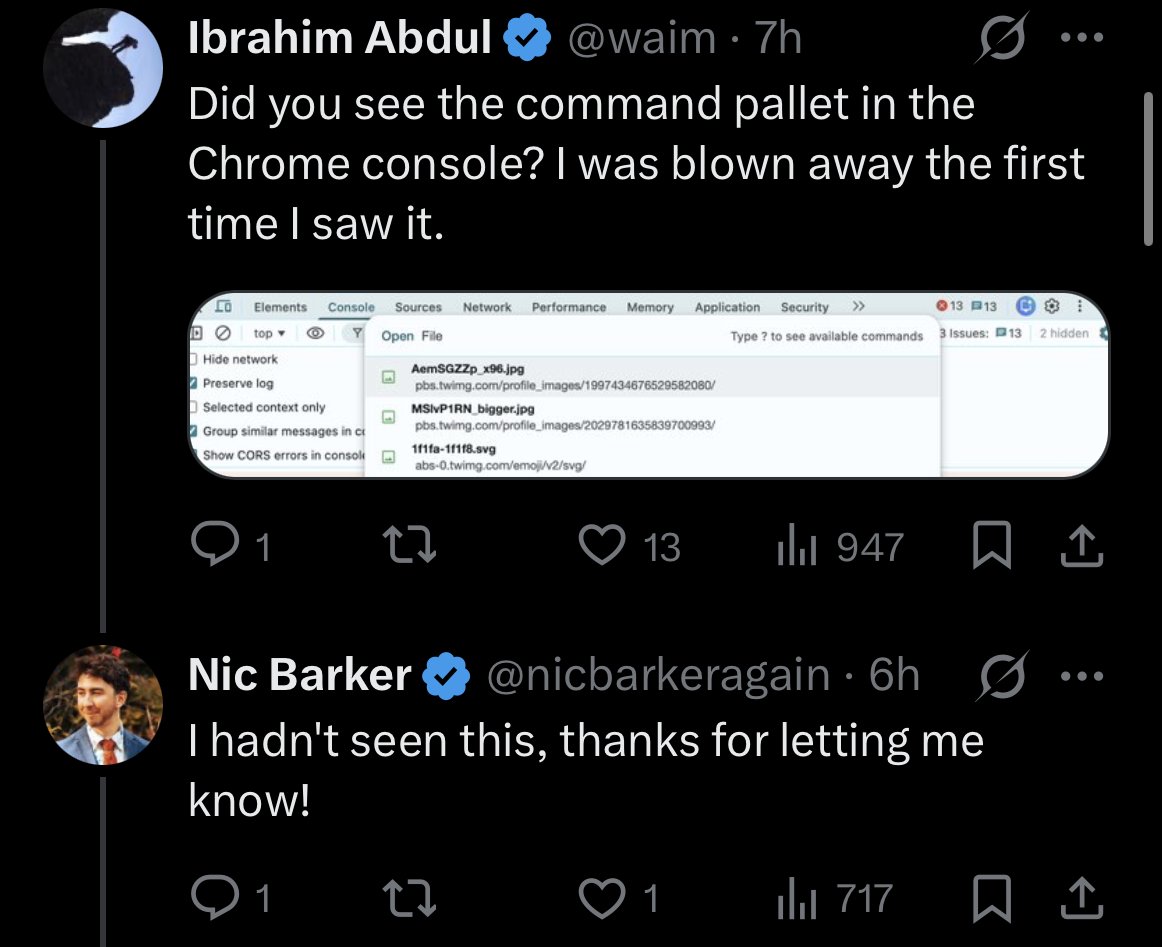

Another case of programmers making all UIs into a terminal. Command palettes are a huge UI cop-out. I hate apps that have commands that are only available in these things. Most people will never discover them. That’s why we invented menus and buttons. Design actual UI!
Nic Barker@nicbarkeragain
I'm completely convinced at this point that the "Command Palette" is a fundamental UI concept, and should be in all applications. It should also be a built in browser concept, there should be an API for websites to push items to the command palette ("new post", "muted words" etc)
English
Has anyone ever made or purchased "furniture" like this? Any tips or tricks?



English
AI should help you be a better you - not become (or eliminate the need for) someone else. No, AI won't make an engineer a great designer. AI won't make a product manager a great engineer. It won't "replace" these other roles, the people in other roles will become better than before for.
English

It's amusing how everyone arrives at the conclusion that the one thing they do will become even more valuable with AI.
A philosopher says it's all about humanities now.
A journalist says real journalism is what we'll need more of.
A senior engineer says their skills are 10x more valuable because someone has to steer the AI.
They might all be right. But there's something embarrassing about claiming everyone else is going to be screwed except you. Just hubris.
English
.@ThePrimeagen thought provoking video, but I'm a bit dubious. I do doubt about the efficacy of AI driven clean room engineering - but even if we were to grant that the cost/LOE to do so came to nil, what do you see as the consequence? What's at risk?
youtube.com/watch?v=6godSE…

YouTube
English
@jazer Don’t be afraid to linger, contemplate and think deeper on the current thread. What’s best next? That’s the hard work. Over-emphasis on activity and efficiency can be a mask for anxiety.
English

Dunno who needs/wants to see this... but this is a reminder that multi-tasking is not a thing.
When we think we're multi-tasking, we're actually just switching back and forth between tasks.
And when we switch context, it can take 15-20 minutes to reestablish the level of focus and flow we left behind.
I've noticed this in my own use of AI, and in my friends who have embraced quasi-synchronous agent management for coding or other knowledge workflows.
And it creates two problems:
P1. It's bad for our mental health. Focus, creativity, and flow states are right-brain-hemisphere phenomena, and they act as a counterbalance to anxiety, which is a left-brain thing.
Take someone who's built a life/career around deep work and make them a manager of agents..... of course they feel anxious, overwhelmed, and overworked.
P2. It's bad for our work. Remember the famous @paulg essay about maker schedules and manager schedules?
Going all-in on agents blows up your maker schedule and makes you a manager. It doesn't LOOK that way on your calendar, but that's what it is.
You're producing more, but are you producing better? What do you lose when you give away your human brain's unique power? Sadly, you won't know right away — instead, you'll frantically fritter away your edge, feeling productive until you realize what went wrong.
Those are the problems. What are the solutions?
S1. Constrain your switching to a single context.
Don't jump between five totally different agent workstreams. If you're using multiple agents or tools, consolidate them on a single project or task. Stay in the zone, with AI as your helper.
Our brains can handle this — it's the context switching that causes all the problems.
S2. Separate maker time and manager time.
Learn to timebox deep focused flow work separate from production-oriented agent management work. Choose a time(s) of day when you can focus on planning and creating original thought, and other times when you can monitor agent workstreams while doing email or other admin work.
Our brains can handle this, too — compartmentalization works really well.
This is not a luddite post.... it's just my attempt to match what we know about brains (which aren't changing) to new AI capabilities (that are changing all the time). These are a couple of things that work for me.
What's working for you?
English
@ryanflorence @PrudentThinquer Feelings, thoughts, and actions - can’t really disconnect from each other. Science and religion has for a lot of this wrong recently.
This is a great podcast episode on the topic: pca.st/episode/02dee8…
English
@PrudentThinquer "And they said one to another, did not our heart burn within us, while he talked with us by the way, and while he opened to us the scriptures?"
- Luke 24:32
Imagine telling the apostles they should have ignored the very thing that testified of the resurrection to them
English

