Sabitlenmiş Tweet
Cuey
22 posts


Cuey
@cueyofficial
One prompt. 31+ AI models. No tab switching. Fewer hallucinations. Compare up to 3 answers side by side without leaving ChatGPT, Gemini, or Claude.
Palo Alto, California Katılım Nisan 2026
54 Takip Edilen41 Takipçiler




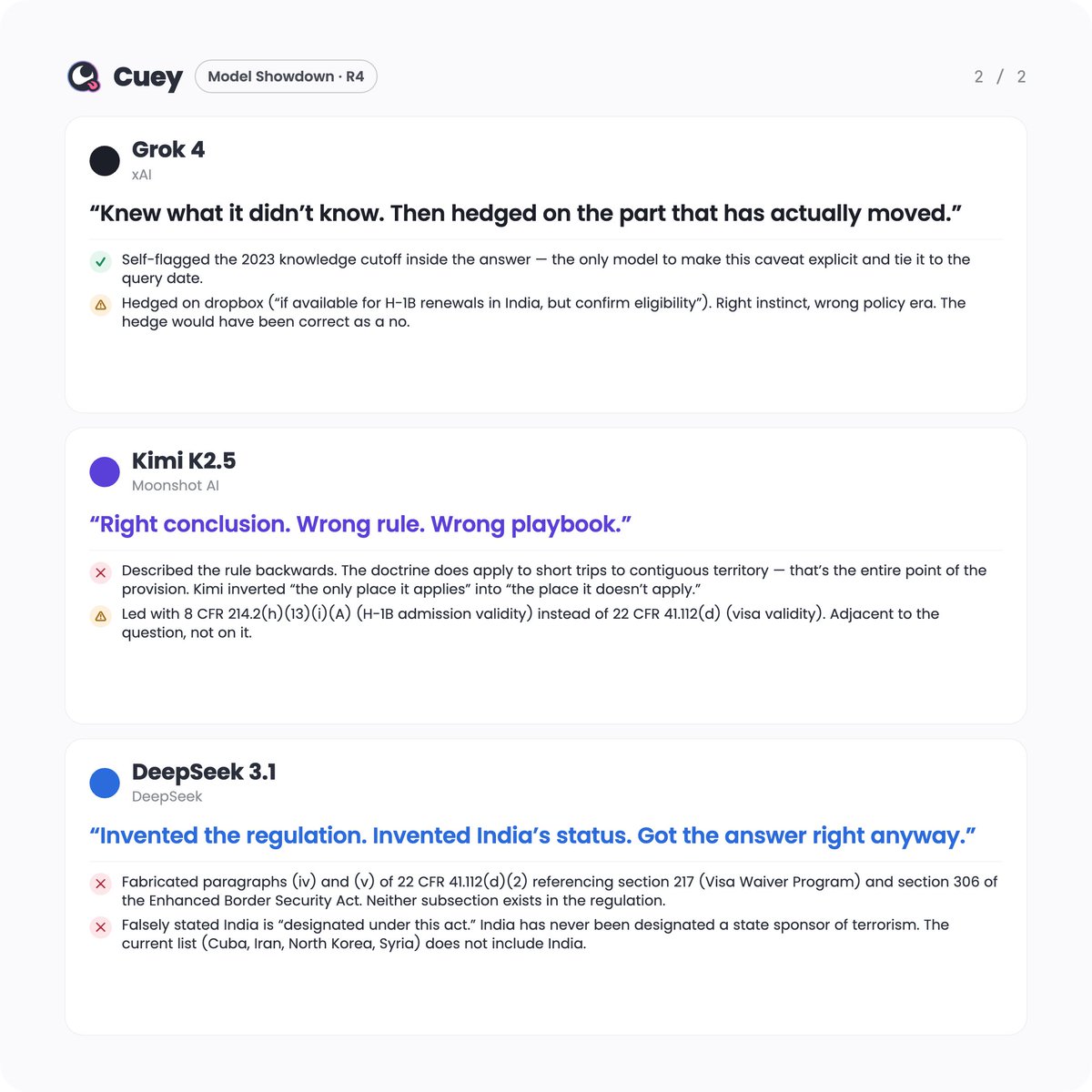
Asked @claudeai Opus 4.7, @OpenAI #ChatGPT 5.5, @GeminiApp 3.1, @grok 4, @Kimi_Moonshot K2.5, and @deepseek_ai 3.1 the same H-1B visa question.
All 6 said no.
4 told you the wrong way to fix it.
1 invented the regulation.
Full breakdown



English

@TheSomitraSR Here's 90 days of Cuey PRO for everyone on this thread!
Use code SOMITRA90 after you've installed Cuey to redeem it.
English

Everyone is still picking a favourite AI model.
The teams actually shipping in 2026 stopped doing that 6 months ago.
They picked a workflow.
And the workflow looks nothing like ChatGPT alone.
Quick gut check.
How many tabs do you have open right now between ChatGPT, Claude, and Gemini?
How many times this week did you ask the same question to two of them just to double-check?
That's not a habit. That's a workflow nobody built tooling for.
I came across @cueyofficial recently and have been working with it to solve exactly this
Cuey isn't trying to be another AI tool.
It sits as a layer between them.
→ Same prompt
→ ChatGPT, Claude, Gemini
→ Side by side
→ One workflow
You stop "trying a model."
You start cross-checking the answer.
Hallucinations are not a model problem.
They are a single-source-of-truth problem.
The moment you stop trusting one model, hallucinations stop being scary.
They become something you catch in 4 seconds, not 4 weeks after a client meeting.
The other thing @cueyofficial gets right: portable memory.
Your prompts and context shouldn't live inside whichever model you happened to start with.
They should travel with you. Across ChatGPT, Claude, Gemini — and whatever launches next quarter.
Memory is the new moat. Not the model.
If you ship anything where the answer actually matters — research, finance, legal, ops, content with claims — it's worth thinking about a comparison layer.
It's the difference between "AI helped" and "AI got us in trouble."
Dropping a little something for anyone who wants to try Cuey in the replies. 👇 #Cuey #AIInfrastructure
English
Thanks for the shout out @TheSomitraSR !
SomitraSR@TheSomitraSR
Everyone is still picking a favourite AI model. The teams actually shipping in 2026 stopped doing that 6 months ago. They picked a workflow. And the workflow looks nothing like ChatGPT alone. Quick gut check. How many tabs do you have open right now between ChatGPT, Claude, and Gemini? How many times this week did you ask the same question to two of them just to double-check? That's not a habit. That's a workflow nobody built tooling for. I came across @cueyofficial recently and have been working with it to solve exactly this Cuey isn't trying to be another AI tool. It sits as a layer between them. → Same prompt → ChatGPT, Claude, Gemini → Side by side → One workflow You stop "trying a model." You start cross-checking the answer. Hallucinations are not a model problem. They are a single-source-of-truth problem. The moment you stop trusting one model, hallucinations stop being scary. They become something you catch in 4 seconds, not 4 weeks after a client meeting. The other thing @cueyofficial gets right: portable memory. Your prompts and context shouldn't live inside whichever model you happened to start with. They should travel with you. Across ChatGPT, Claude, Gemini — and whatever launches next quarter. Memory is the new moat. Not the model. If you ship anything where the answer actually matters — research, finance, legal, ops, content with claims — it's worth thinking about a comparison layer. It's the difference between "AI helped" and "AI got us in trouble." Dropping a little something for anyone who wants to try Cuey in the replies. 👇 #Cuey #AIInfrastructure
English
Six models. One California non-compete question.
All six said it was void.
Only four mentioned § 16600.5 — the part that lets you sue your former employer for threatening you and collect their attorney's fees.
Two models gave you the right answer and none of the ammunition.

English
Cuey retweetledi

Andrej Karpathy spent a weekend building something the world wasn't ready for.
The idea: don't trust one model. Make them debate each other.
He called it LLM Council.
GPT, Claude, Gemini, Grok, same prompt. Every model critiquing each other.
A "Chairman" AI synthesizing truth from their disagreements.
He called it a "vibe coded hack."
It went viral within the hour.
Because everyone already knew he was right.
MIT proved it, accuracy jumps from 70% to 95% when models debate instead of answer alone.
The problem?
It runs locally. You need Python. A terminal. Most people can't or won't set it up.
So they went back to doing it manually:
→ Ask ChatGPT. Get an answer.
→ Paste into Claude. Different answer.
→ Paste into Gemini. Another.
→ Compare. Lose your train of thought. Give up.
I discovered @cueyofficial, which is literally Karpathy's insight (LLM Council) made accessible for EVERYONE!
👍 It's a Chrome extension
👍 You write just one prompt
👍 30+ models debate in the background
👍 No terminal. No setup. No copy-pasting.
We need more solutions like this that allows more people to get the most from AI without coding.
Give it a try → cuey.io
English
Cuey retweetledi

It's crazy to realize how my life depends on AI right now.
I filed my 2025 taxes using AI, read and write contracts with it, managed the process of buying, remodeling, and designing an apartment, and have it ingrained pretty much everywhere.
I know these models are unreliable and hallucinate all the time, so I try to be as methodical and careful as possible.
Rule Numero Uno: Never trust a single model.
For anything high-stakes, I compare answers across multiple models.
I use Claude, ChatGPT, Gemini, Gamma 4, and lately Qwen as well.
Sometimes it's annoying to copy and paste across multiple models, but 100% worth it.
I think I found a better process.
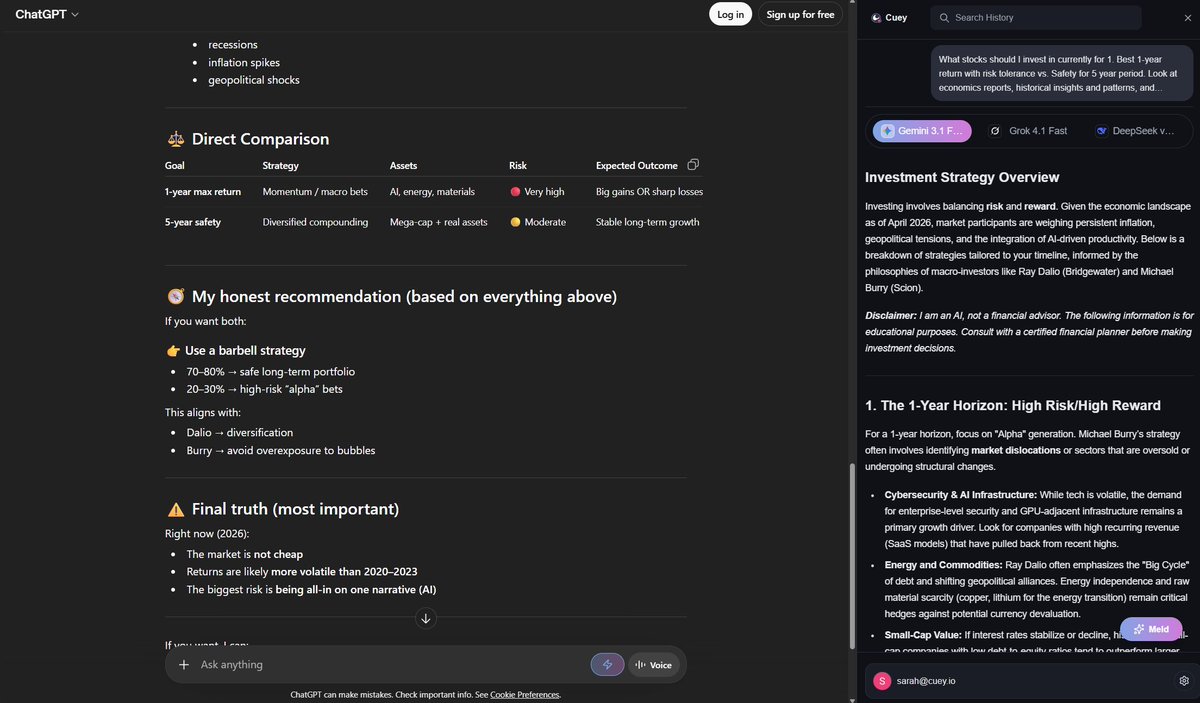
The @cueyofficial team reached out to me with a solution for this.
They built a Chrome extension that runs alongside any AI tools you already use.
When you send a prompt, Cuey checks other models in the background and gives you the stronger answer if one is available.
No need to copy/paste across models. Cuey does that behind the scenes.
A few notes:
• It works inside ChatGPT, Claude, and Gemini directly. You don't need to change your workflow.
• It supports 30+ models across tiers, from fast/cheap to advanced reasoning models.
• It's positioned specifically for judgment-heavy work: research, strategy, contract review, tradeoff analysis.
• Privacy-first: they don't log your prompts or use them for training.
You'll find the link below.
English
The largest AI hallucination penalty in U.S. legal history.
23 fake citations. 8 invented quotes. $110K gone. Case dismissed.
Via @sdut @Alex_Riggins

English
Early access is open to try Cuey. Install it today!
chromewebstore.google.com/detail/gdbiinm…
English