InconsEng
211 posts


InconsEng
@cynilv
21 • engineer @ burki | building voice ai that answers quick.




Every engineer I know has asked this at some point: "How deep should I actually go?" According to me, the decision to go deep down the rabbit hole comes down to two things: 1. curiosity - what genuinely pulls you in 2. career direction - where you want to be in the next 2/3 years, not where the internet says you should be My honest take: depth works best when it serves at least one of those. Ideally, both. If something aligns with your career direction, going deep is an obvious win. One simple way to test this is to think in 2/3 year windows and ask yourself: Does understanding this layer actually move me closer to where I want to be? If you are building web apps, you do not need to master CPU instruction sets. If you are working on databases, B-tree internals matter far more than knowing every Linux kernel detail. Context changes what "deep" really means. Abstraction layers exist for a reason. They let you build without getting overwhelmed. A frontend engineer who understands HTTP is usually more valuable than one who has memorized TCP packet headers but struggles to ship features. If something does not align with your career direction, curiosity still matters. Learning out of pure interest is not wasted time. You do it because it optimizes for motivation, long-term learning, and happiness. What does not make much sense is going deep in areas that serve neither curiosity nor direction - often driven by comparison or fear. So keep checking in with yourself. Ask questions. Course-correct often. Depth is most powerful when it is intentional.


I just found the new organic affiliate meta I don’t see anyone pushing AI content this quality organically I made this AI UGC video in no joke 30 minuets (not including generation time) You can literally run up millions of views with videos like this pushing to brands and make 20k - 30k a month This is my exact play I’m going to run to get to $30k a month with 1 IG page using this content style > Make an IG account for a gut supplement brand offering me $2k retainer + commissions > Generate insane creatives like this with a consistent character hitting pain points, highlighting problems and teasing the solutions to them > Run a many chat comment funnel and send them a free “acne gut health guide” including my affiliate link > Also have link in bio to clean up extra conversions Honestly affiliate game is on easy mode right now
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.







I built this thing called Clicky. It's an AI teacher that lives as a buddy next to your cursor. It can see your screen, talk to you, and even point at stuff, kinda like having a real teacher next to you. I've been using it the past few days to learn Davinci Resolve, 10/10.


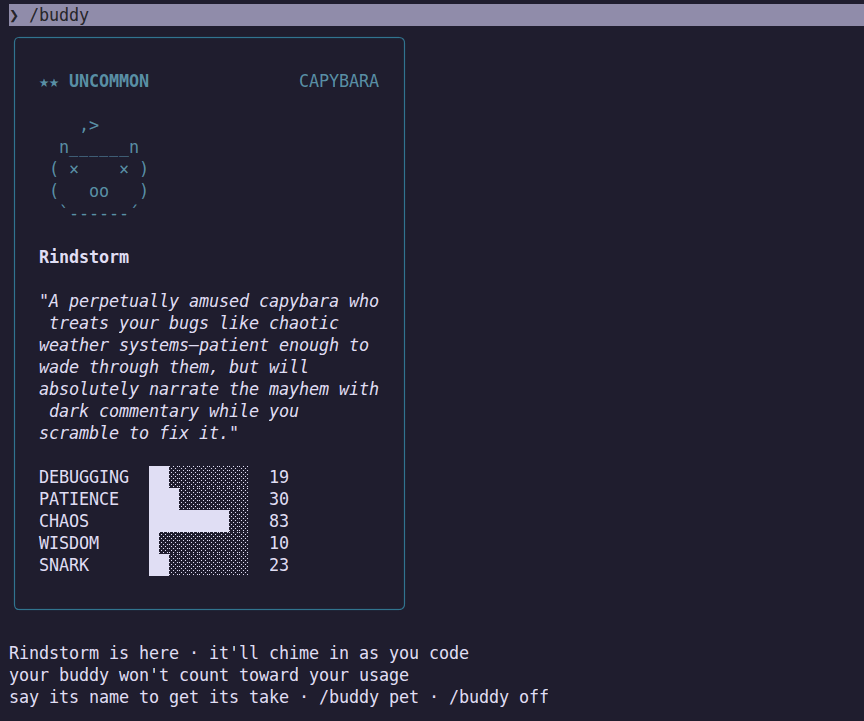




My feed is showing me a bunch of folks who tapped out their whole usage limits on Mon/Tue. Is this your experience? Please comment, I want to understand how widespread this is


we’ve signed Zero Data Retention agreements with all providers for Go all models now follow a zero-retention policy your data is not used for training