dCodes@dCodes03
I've applied the @karpathy autoresearch loop to my golang library that I am building.
I'm building a config-driven protobuf builder in Go for our BFF (Backend For Frontend) layer.
> The problem
App-facing APIs return massive, deeply nested proto responses - 82KB, 42 messages, 3 levels of recursion - and building them by hand means hundreds of lines of tightly-coupled Go code.
That's just one element in a 2400KB JSON array response with multiple different proto element types, where other items could be even more complex and future designs will only push the schema further. Building them by hand means hundreds of lines of tightly-coupled Go code that changes every time the proto schema changes for new designs.
The library fixes this. You define a JSON config (static templates + dynamic markers + generators for repeated fields), pass a flat data map at runtime, and it constructs the full proto using reflection. Config lives in a DB, not in code. Schema changes = config push, not a deploy.
But reflection-based proto construction is slow. And at the microsecond level, intuition breaks. Changes that *should* be faster often aren't. Proto reflection is full of traps.
So I made it a loop. One artifact (Go source code), one metric (benchmark ns/op), keep what improves, revert what doesn't. Run it. Come back to a faster library.
> How it works:
One EXPERIMENT.md describes everything - the architecture, the benchmark commands, the rules, and the optimization ideas to explore. You don't hand-pick experiments. You don't write the code changes.
artifact: injector/builder.go + injector_fast.go
metric: BenchmarkBuild ns/op, allocs/op
constraint: 19 unit tests + byte-identical proto output
rule: improved → git commit. same or worse → git reset --hard HEAD~1
From that alone, the agent reads the code, profiles with go tool pprof, finds the bottleneck, proposes ONE surgical change to the Go source, runs tests + correctness checks, benchmarks 5s × 3 runs, and decides keep or discard. It sees its own experiment history - when something fails, the next proposal knows what was tried and why it didn't work.
> The loop:
1. Read current code + profile CPU bottlenecks
2. Propose ONE change (edit Go source files directly)
3. Run 19 unit tests + byte-identical output check
4. Benchmark with -benchtime=5s -count=3
5. Improved? Keep + git commit. Otherwise git reset --hard HEAD~1.
6. Go to 1. Run until stopped.
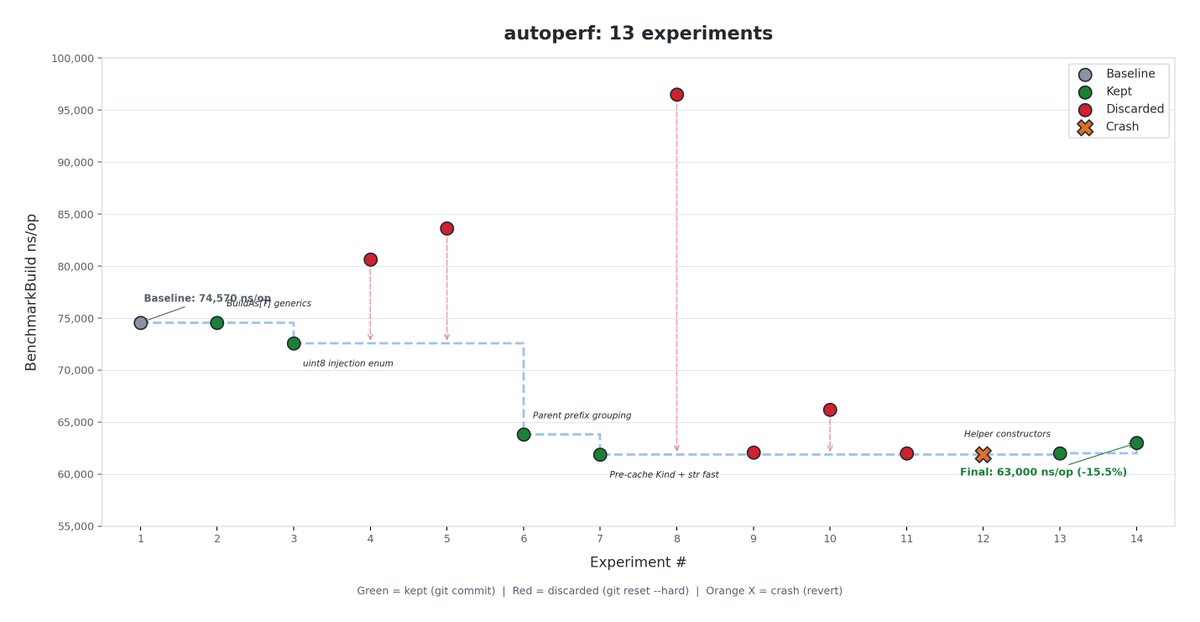
13 experiments on a live Go protobuf builder. 0 human intervention.
> Build: 74,570 → 63,000 ns/op (-15.5%)
> E2E: 104,647 → 95,400 ns/op (-8.8%)
> Parallel: 25,267 → 22,006 ns/op (-12.9%)
> 6 kept, 6 discarded, 1 crash
> Bonus: added type-safe generics, config validation, helper constructors
The biggest single win? The agent noticed that injection markers like clickAction.openTab.postBody and clickAction.openTab.cacheKey share a parent path. It grouped them at compile time - walk the Mutable() chain once, set all leaf fields. 14.4% Build speedup from one structural insight found by reading the workload data.
What it discarded is equally interesting:
> Pre-allocating list capacities → regression (proto's NewElement allocates throwaway messages)
> Wire-bytes clone instead of proto.Clone → 12% slower (Unmarshal creates more objects than pointer copy)
> Template-free building → 25 correctness diffs (missed repeated field semantics)
> Empty template skip → 7% regression (branch misprediction penalty on CPU)
Every one of these sounds like it should help. None did. That's the whole point of the loop - you stop guessing and start measuring.
You describe the system. You set the constraints. It figures out what's actually fast.