Sabitlenmiş Tweet

Bo Dai
223 posts

@daibond_alpha
Assistant Professor at @gtcse, Research Scientist at @GoogleDeepMind | ex @googlebrain




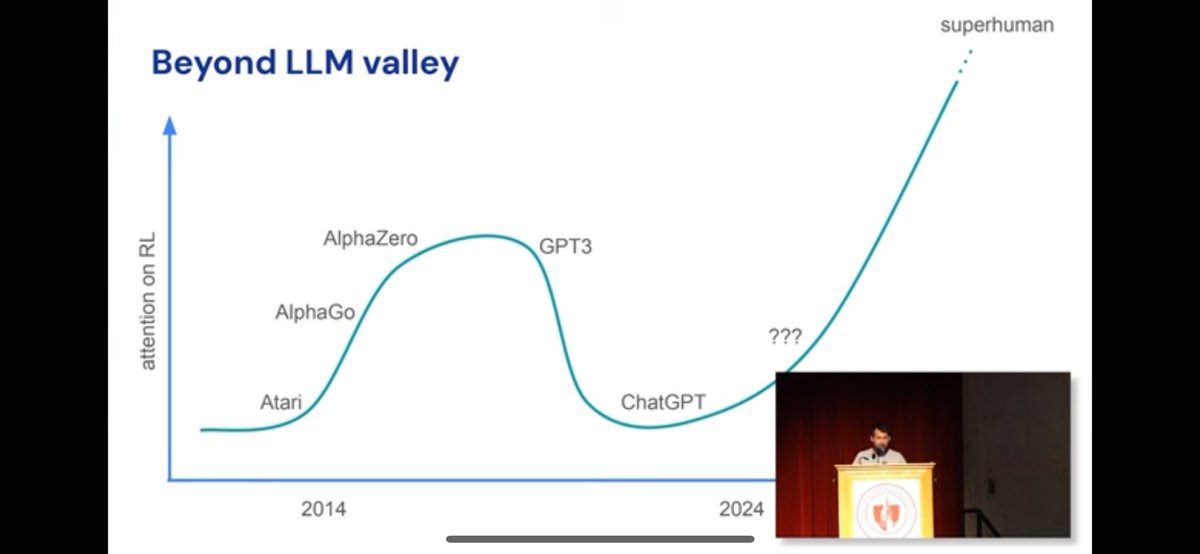
9 years ago I was interning under Ilya at Google Brain. First thing he told me is Solomonoff Induction and AIXI, i.e. why prediction leads to understanding. GPT came from sentiment neurons. The level of clarity he and Geoff had was always inspiring.


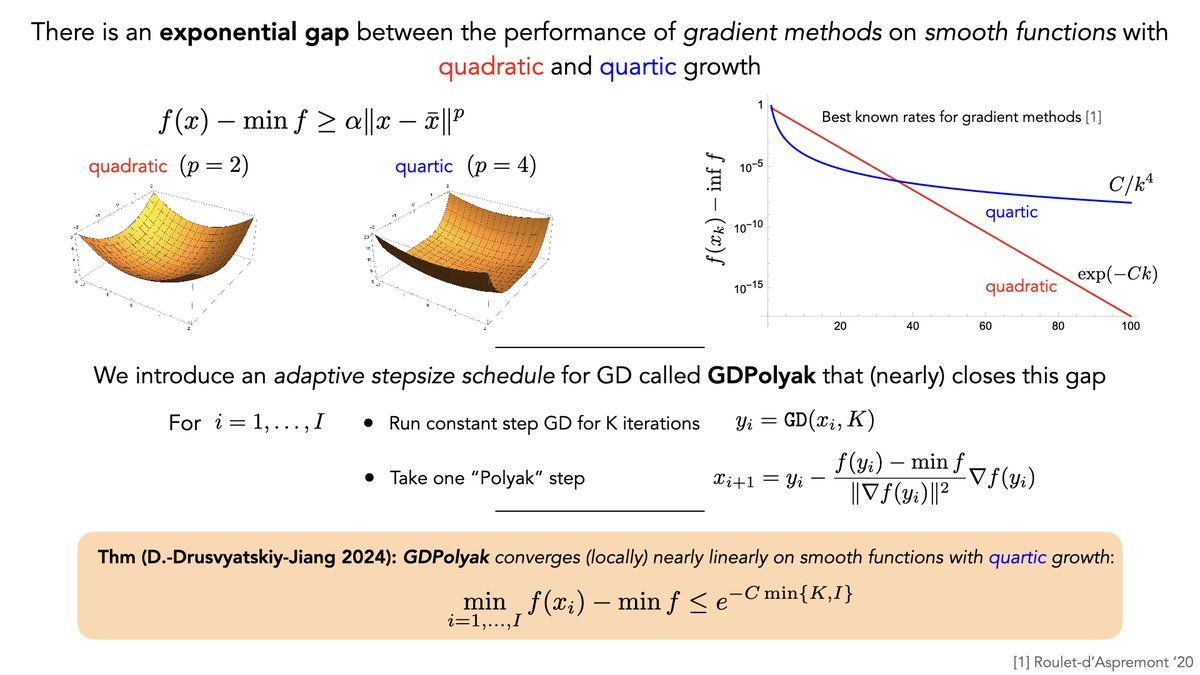
(3/N) EC-DIT outperforms dense models while maintaining competitive inference speed. Our largest model (64 experts) hits a GenEval score of 71.68%🔝, with around 23% additional overhead to the dense model.
Source: papercopilot.com/paper-list/neu…



Our team (w/Dale, @daibond_alpha, @mengjiao_yang + others) at Google DeepMind is looking to hire. If you are interested in foundation models+decision making, and making real-world impact through Gemini and cloud solutions, please consider applying through boards.greenhouse.io/deepmind/jobs/…
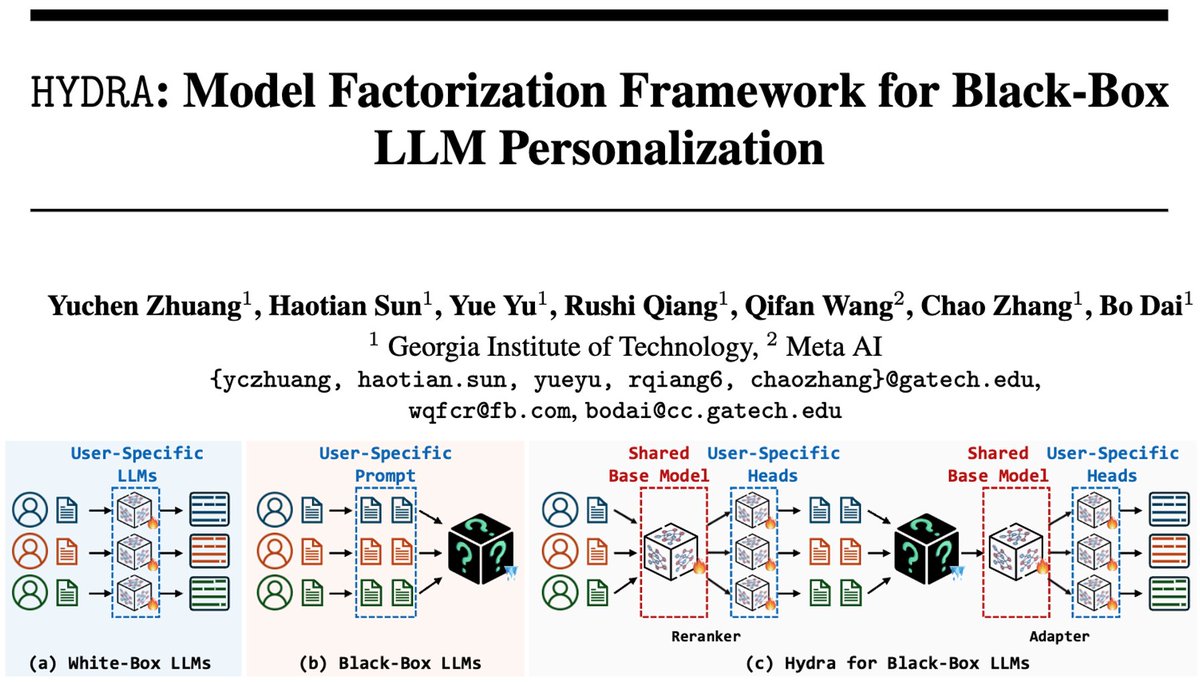
We make local private adaptation of GPT possible!