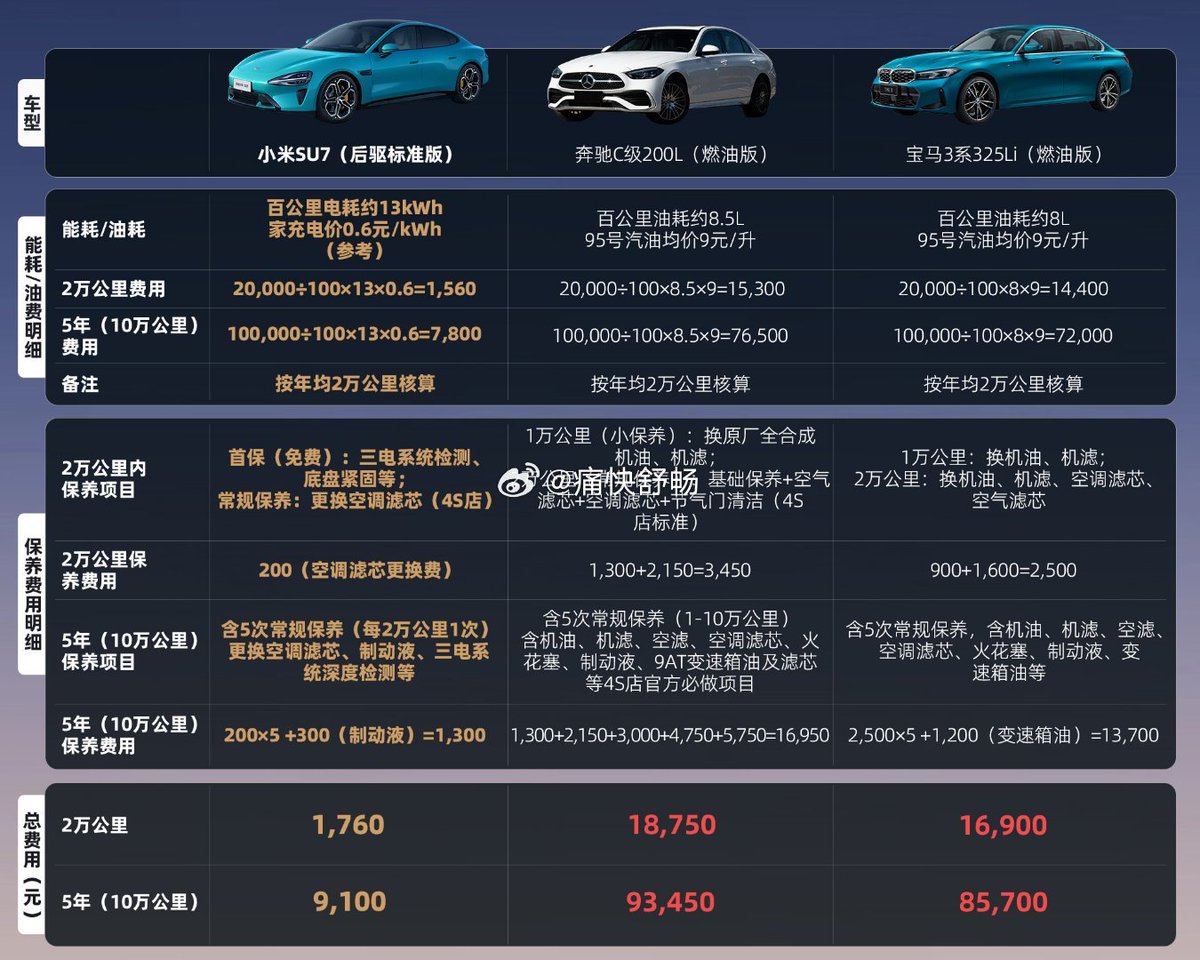
@AdameMedia How come there is not one journalist who has the balls to ask/point out exactly these things in that meetings??
I can’t understand
English
Dali
2.4K posts












China isn't turning into a “green superpower.” Any renewable energy systems they're installing only add to existing energy sources; they are not replacing fossil fuels at all. China is increasing their use of ALL energy.

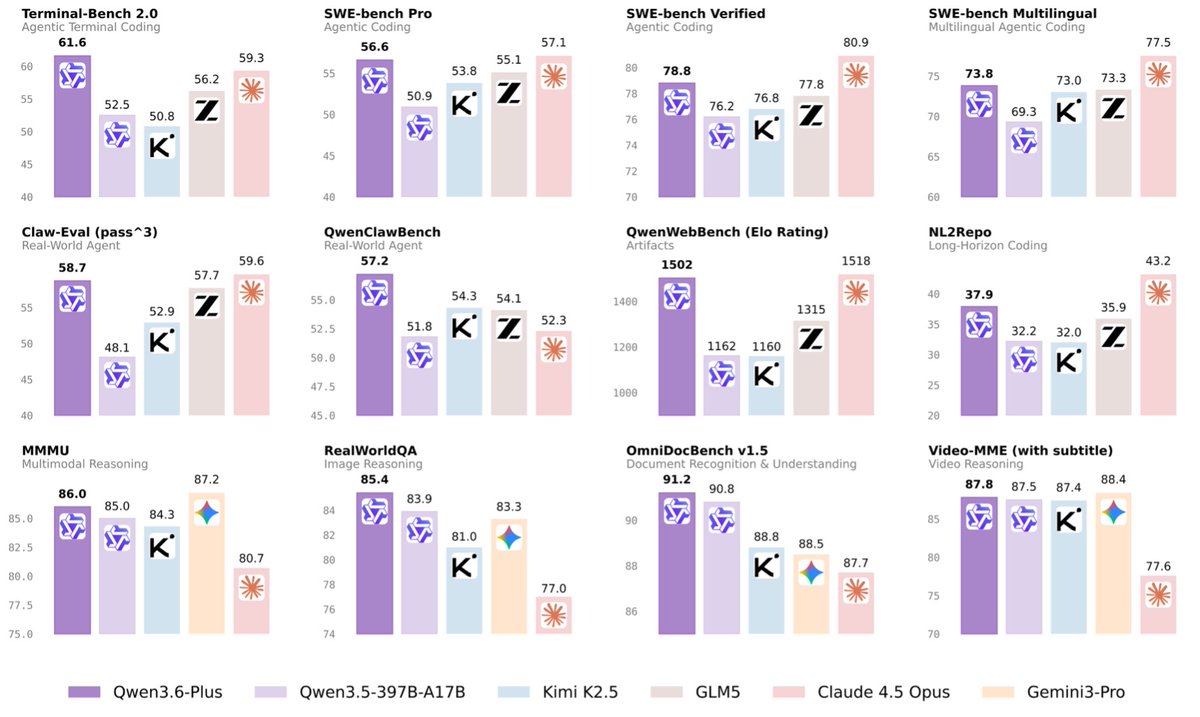
OpenAI released GPT-5.4 mini and nano, cheaper variants of GPT-5.4 with the same reasoning modes. GPT-5.4 nano is the standout, scoring ahead of both Claude Haiku 4.5 and Gemini 3.1 Flash-Lite Preview with lower per token pricing @OpenAI released GPT-5.4 mini (xhigh, 48) and nano (xhigh, 44), the first mini and nano updates since GPT-5. Both are multimodal with image input support and feature a 400K token context window. They support the same reasoning effort levels as GPT-5.4 (xhigh, high, medium, low, none) and are priced significantly lower: mini at $0.75/$4.50 per 1M input/output tokens and nano at $0.20/$1.25, compared to GPT-5.4 at $2.50/$15. We evaluated these models across three reasoning variants: xhigh, medium, none. While both models are more intelligent than their peers in the highest reasoning efforts, they are more verbose, using 200M+ output tokens to run the Intelligence Index, higher than even select frontier models Key benchmarking takeaways from the highest reasoning variants: ➤ GPT-5.4 nano (xhigh, 44) jumps 18 points from GPT-5 nano (high, 27), with improvements across all evaluations. Compared to Claude Haiku 4.5 (Reasoning, 37) and Gemini 3.1 Flash-Lite Preview (34), GPT-5.4 nano leads on τ²-Bench (81% vs 55% and 31%), IFBench (76% vs 54% and 77%), and TerminalBench (42% vs 27% and 24%) ➤ GPT-5.4 mini (xhigh, 48) gains 7 points over GPT-5 mini (high, 41), with gains across most evaluations. Compared to Gemini 3 Flash Preview (Reasoning, 46) and Claude Sonnet 4.6 (Adaptive Reasoning, max effort, 52), GPT-5.4 mini leads on TerminalBench (52% vs 39% and 53%) and CritPt (10% vs 9% and 3%) ➤ Both models perform less on AA-Omniscience compared to peers, driven primarily by high hallucination rates. GPT-5.4 mini scores -18.7 with a 90% hallucination rate, well behind Claude Sonnet 4.6 (Adaptive Reasoning, max effort, +12.4, 46% hallucination rate) and Gemini 3 Flash Preview (Reasoning, +11.6, 92% hallucination rate but 54% accuracy). GPT-5.4 nano scores -29.6 with a 74% hallucination rate, behind Claude Haiku 4.5 (Reasoning, -4.2, 26% hallucination rate) and Gemini 3.1 Flash-Lite Preview (-15.5, 82%). Both GPT-5.4 models attempt to answer far more questions than Claude Haiku 4.5 and Claude Sonnet 4.6 rather than abstaining, which drives the higher hallucination rates ➤ Both models show strong agentic performance. GPT-5.4 mini scores 1405 on GDPval-AA (Agentic Real-World Work Tasks), ahead of Gemini 3 Flash Preview (Reasoning, 1191) but behind Claude Sonnet 4.6 (Adaptive Reasoning, max effort, 1633). GPT-5.4 nano scores 1169, close to Claude Haiku 4.5 (Reasoning, 1173) and well ahead of Gemini 3.1 Flash-Lite Preview (944) ➤ Token usage with xhigh reasoning effort is higher for both models compared to peers with highest reasoning efforts. GPT-5.4 mini used 235M output tokens to run the Intelligence Index, ~3.4x GPT-5 mini (high, 69M) and more than Claude Sonnet 4.6 (Adaptive Reasoning, max effort, 198M) despite scoring 4 points lower. GPT-5.4 nano used 210M output tokens, ~2.4x Claude Haiku 4.5 (Reasoning, 87M) and ~4x Gemini 3.1 Flash-Lite Preview (53M) ➤ Effective cost to run the Intelligence Index reflects the higher token usage. GPT-5.4 mini (xhigh) cost ~$1,406, compared to ~$278 for Gemini 3 Flash Preview (Reasoning) and ~$3,959 for Claude Sonnet 4.6 (Adaptive Reasoning, max effort). GPT-5.4 nano (xhigh) cost ~$376, compared to ~$584 for Claude Haiku 4.5 (Reasoning) and ~$94 for Gemini 3.1 Flash-Lite Preview. GPT-5.4 nano is cheaper than Claude Haiku 4.5 on an effective cost basis despite using ~2.4x more tokens, due to its significantly lower pricing. Overall, GPT-5.4 nano is the standout offering a better Intelligence vs. Cost to Run Intelligence Index tradeoff than peers and GPT-5.4 mini