Over the past few months I've been working with some of the worlds largest bank and their AI teams, after speaking with about a dozen of them, 𝗜 𝗿𝗲𝗮𝗹𝗶𝘇𝗲𝗱 𝘁𝗵𝗲𝘆 𝘀𝗵𝗮𝗿𝗲𝗱 𝗺𝗮𝗻𝘆 𝗽𝗮𝘁𝘁𝗲𝗿𝗻𝘀 𝗮𝗻𝗱 𝗽𝗮𝗶𝗻𝘀 𝗮𝘀 𝘁𝗵𝗲𝘆 𝗮𝗱𝗼𝗽𝘁 𝗴𝗲𝗻𝗔𝗜 𝗮𝗰𝗿𝗼𝘀𝘀 𝘁𝗵𝗲 𝗼𝗿𝗴
The key insights were:
- 𝗙𝗲𝗱𝗲𝗿𝗮𝘁𝗲𝗱 𝗮𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲𝘀 are extremely common (complex topology across the business lines)
- Central AI platform teams need to deal with a wide breath of customer variety from maturity, scale, budget, technology stack, networking, and beyond
- You need deep engineering pedigree in a platform and at the same time, built-in intuition and tools for non technical business users to help contribute in building AI
- They have complex regulation, compliance, network restrictions and RBAC requirements
- Security, guardrails and evals are a primary concern to the C-Suite
- And many other hurdles specific to dealing with AI in a bank / financial services
They somehow have to adapt and adopt AI quickly in this new world and at the same time mitigate risk and protect themselves while doing it
I realized that @arizeai AX and @ArizePhoenix ecosystem together was perfectly suited to tackle their issues and wrote a technical blog post below
𝗪𝗲'𝘃𝗲 𝘀𝗲𝗲𝗻 𝘀𝗼 𝗺𝘂𝗰𝗵 𝗽𝗶𝗰𝗸 𝘂𝗽 𝗶𝗻 𝘁𝗵𝗲 𝗳𝗶𝗻𝗮𝗻𝗰𝗶𝗮𝗹 𝘀𝗽𝗮𝗰𝗲 𝘀𝗼 𝗱𝗲𝗳𝗼 𝗹𝗲𝗮𝗿𝗻 𝘀𝗼𝗺𝗲 𝗼𝗳 𝘁𝗵𝗲 𝗵𝗲𝗹𝗽𝗳𝘂𝗹 𝗽𝗮𝘁𝘁𝗲𝗿𝗻𝘀 𝗵𝗲𝗿𝗲
Thanks to everyonewho came out to @joinstationf in Paris tonight to hear @dat_attacked, Jen Person, and JL de Morlhon and to our friends at @gokoyeb and @docker for organizing.
New post: nanochat miniseries v1
The correct way to think about LLMs is that you are not optimizing for a single specific model but for a family models controlled by a single dial (the compute you wish to spend) to achieve monotonically better results. This allows you to do careful science of scaling laws and ultimately this is what gives you the confidence that when you pay for "the big run", the extrapolation will work and your money will be well spent. For the first public release of nanochat my focus was on end-to-end pipeline that runs the whole LLM pipeline with all of its stages. Now after YOLOing a few runs earlier, I'm coming back around to flesh out some of the parts that I sped through, starting of course with pretraining, which is both computationally heavy and critical as the foundation of intelligence and knowledge in these models.
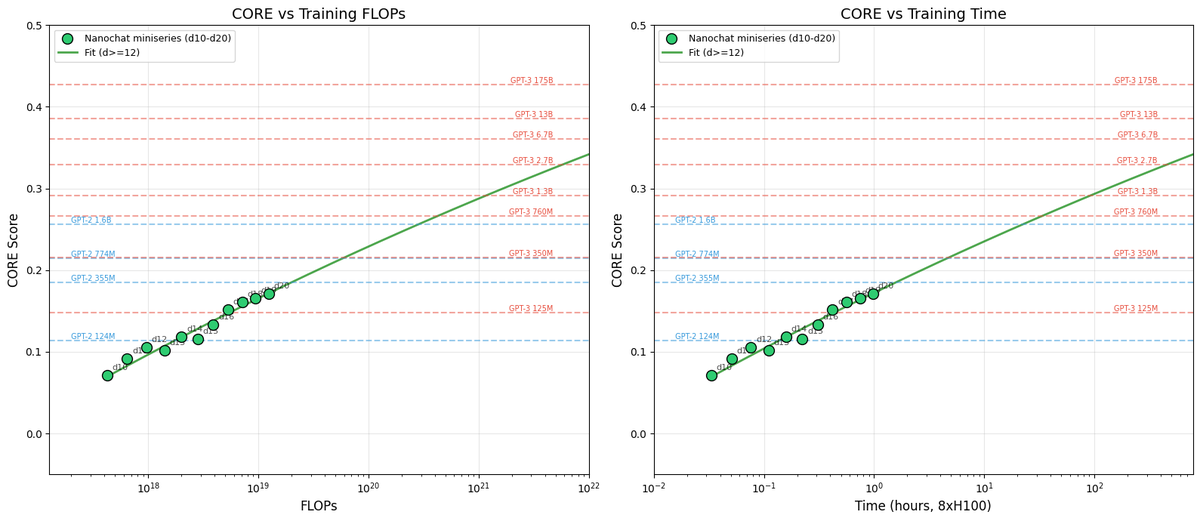
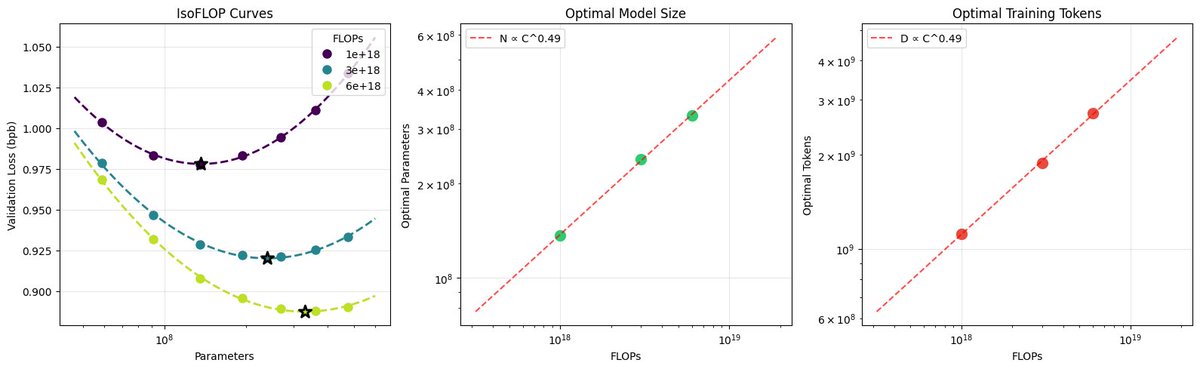
After locally tuning some of the hyperparameters, I swept out a number of models fixing the FLOPs budget. (For every FLOPs target you can train a small model a long time, or a big model for a short time.) It turns out that nanochat obeys very nice scaling laws, basically reproducing the Chinchilla paper plots:
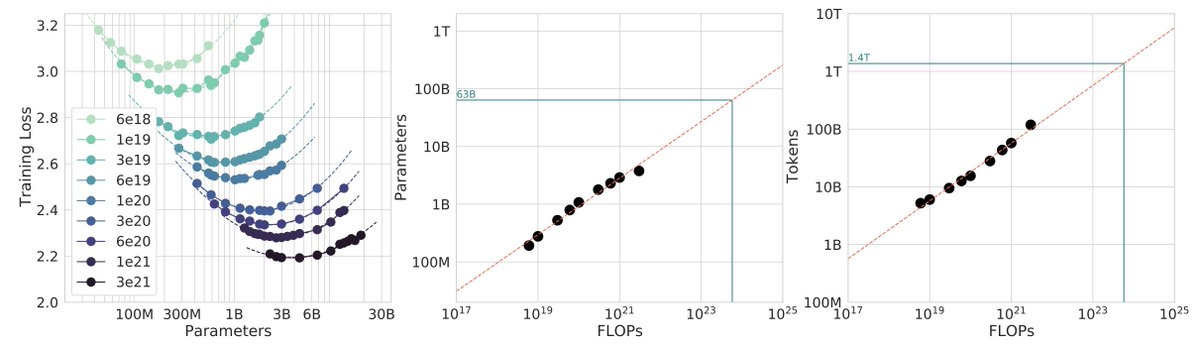
Which is just a baby version of this plot from Chinchilla:
Very importantly and encouragingly, the exponent on N (parameters) and D (tokens) is equal at ~=0.5, so just like Chinchilla we get a single (compute-independent) constant that relates the model size to token training horizons. In Chinchilla, this was measured to be 20. In nanochat it seems to be 8!
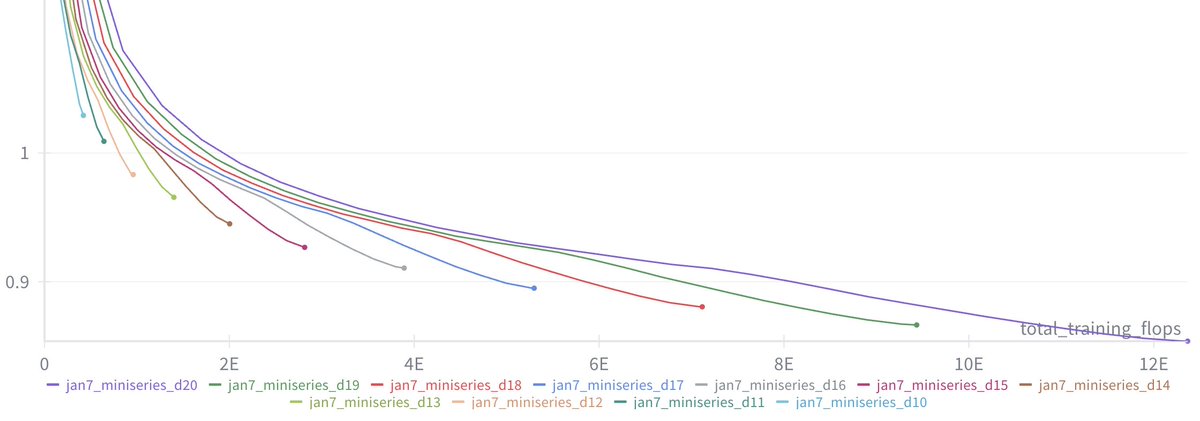
Once we can train compute optimal models, I swept out a miniseries from d10 to d20, which are nanochat sizes that can do 2**19 ~= 0.5M batch sizes on 8XH100 node without gradient accumulation. We get pretty, non-itersecting training plots for each model size.
Then the fun part is relating this miniseries v1 to the GPT-2 and GPT-3 miniseries so that we know we're on the right track. Validation loss has many issues and is not comparable, so instead I use the CORE score (from DCLM paper). I calculated it for GPT-2 and estimated it for GPT-3, which allows us to finally put nanochat nicely and on the same scale:
The total cost of this miniseries is only ~$100 (~4 hours on 8XH100). These experiments give us confidence that everything is working fairly nicely and that if we pay more (turn the dial), we get increasingly better models.
TLDR: we can train compute optimal miniseries and relate them to GPT-2/3 via objective CORE scores, but further improvements are desirable and needed. E.g., matching GPT-2 currently needs ~$500, but imo should be possible to do <$100 with more work.
Full post with a lot more detail is here:
github.com/karpathy/nanoc…
And all of the tuning and code is pushed to master and people can reproduce these with scaling_laws .sh and miniseries .sh bash scripts.
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
In AI evals and observability, the datastore is the foundation. Data is your business.
If you don’t own it, you’re building on borrowed ground.
Langfuse’s move to ClickHouse has exposed just how fragile that foundation is for a number of evals companies.
東京は期待以上でした 🇯🇵
Arize AI 初の日本開催イベントは、質の高い講演、実際のエンタープライズでの知見、そして(これまで参加したミートアップの中でも)最高レベルの素晴らしい食事が揃った、非常に充実したイベントでした。
日本で、オブザーバビリティ、評価、そしてAIの改善といった「本番環境」を見据えたAIエージェントに関する真剣な議論が行われていることは、とても心強いです。
Tokyo Electron Device, Ltd.、Dify、そして関係者の皆さまに感謝します。素晴らしい夜をありがとうございました。
----------
Tokyo delivered 🇯🇵
@ArizePhoenix's first Japan event was a great mix of high-quality talks, real enterprise experience, and excellent food (the best food i've ever had at a meet-up)
It’s encouraging to see serious conversations around production AI agents observability, evaluation, and AI improvement, happening here in Japan
Thank you to @TokyoElectron_J , @dify_ai and everyone involved for making it a strong evening!
Takashi Nakagawa Ryusei Hashimoto Trevor Usken Patrick Kelly Matt Wilson Sean Lee Marudan Kiji, PhD
We just published a new Get Started with Phoenix Quickstart
It walks through the workflow we recommend for improving agent apps in a way you can measure and validate:
🔹 Trace a @crewAIInc agent to capture execution flow, tool calls, and LLM calls
🔹 Define an eval (LLM-as-judge) to score outputs and label failures
🔹 Build a dataset of failure cases so you have concrete data to test iterations
🔹 Run experiments to compare agent versions on the same inputs and verify improvements
The agent is built in Python with @crewAIInc, uses Serper for real-time search, and follows the full trace → eval → iterate loop end to end with Phoenix.
Try it here: arize.com/docs/phoenix/g…
TS version coming soon 👀