DatologyAI retweetledi

This is p sick and completely surprising to me wowie great work
DatologyAI@datologyai
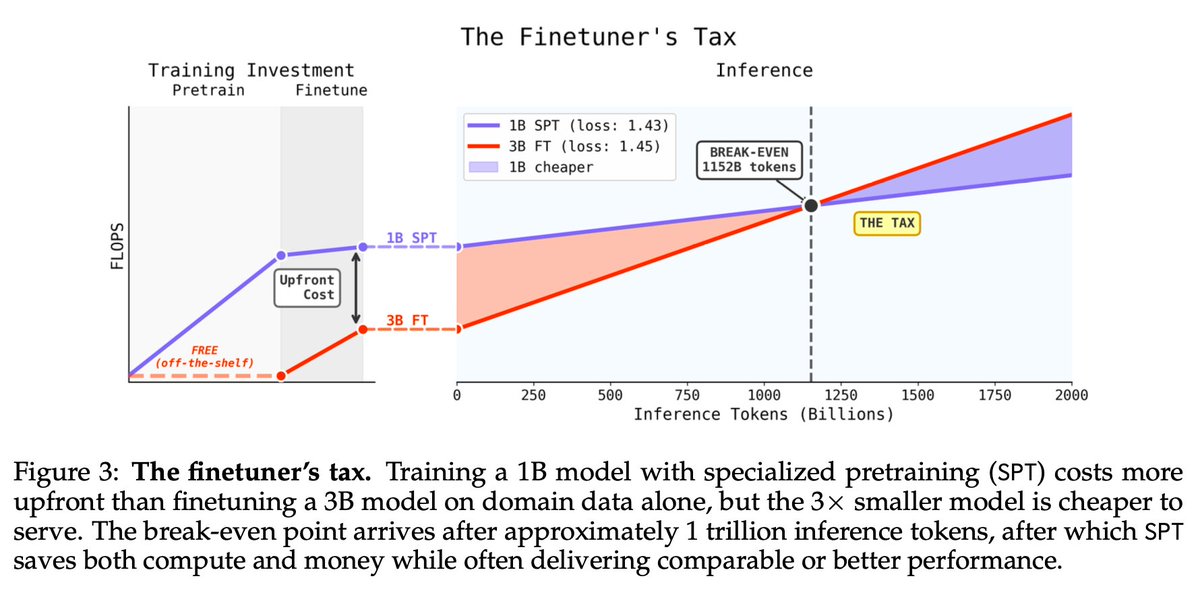
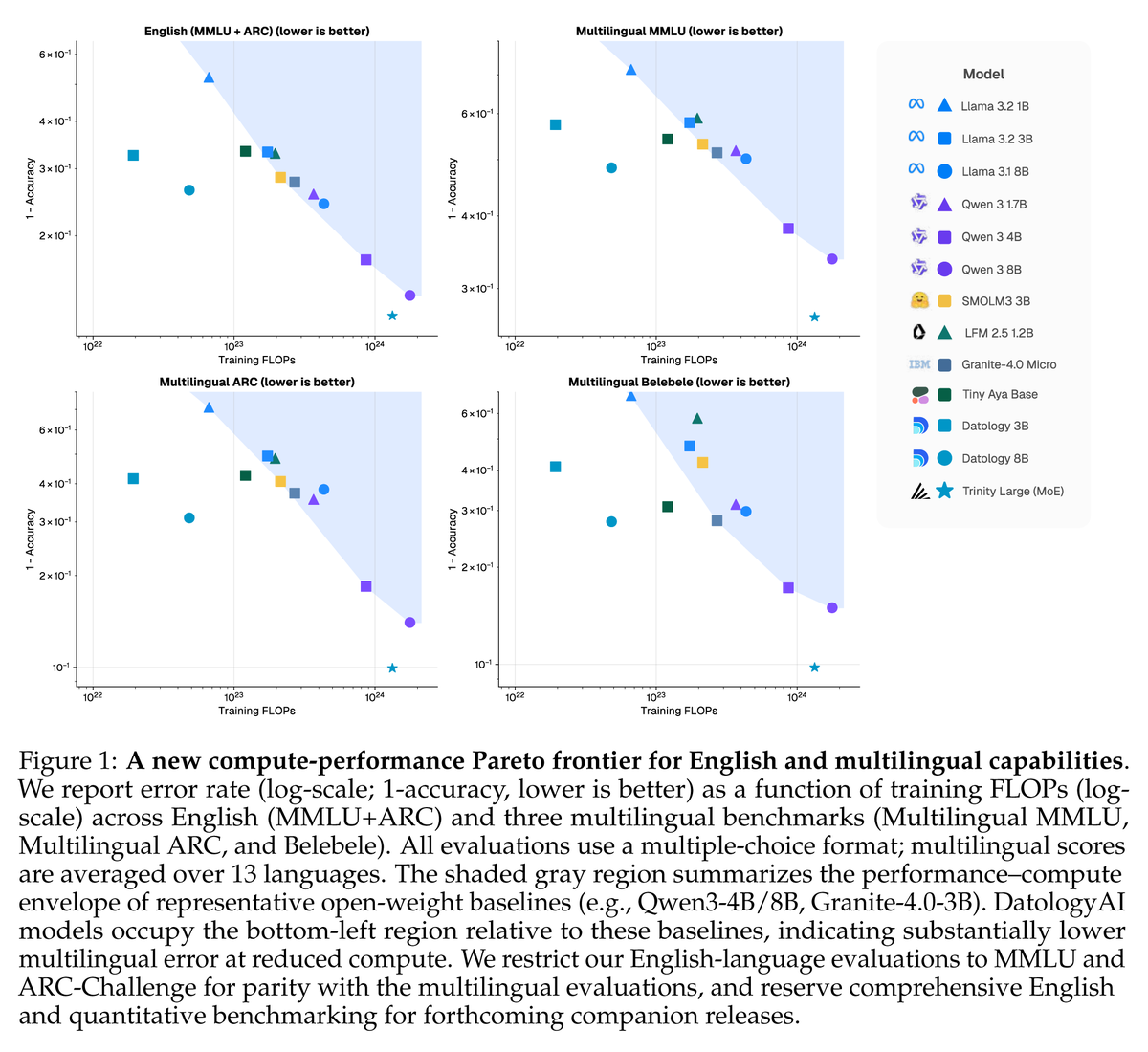
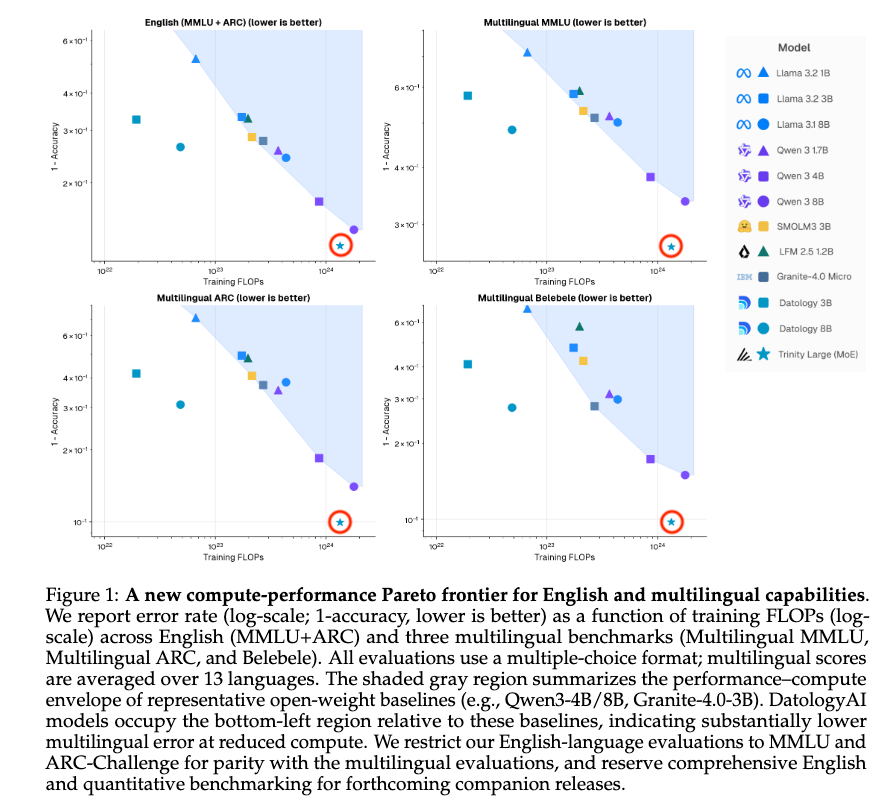
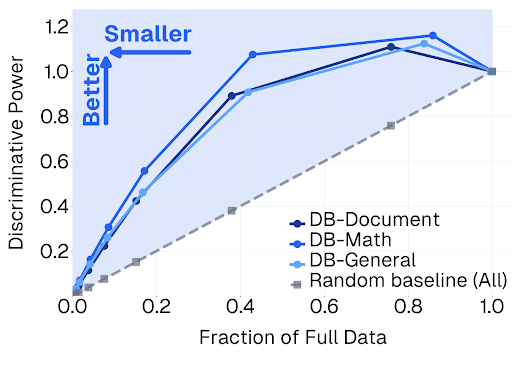
New Datology Research: We expose "The Finetuner's Fallacy" The standard approach to domain adaptation (pretrain on web data, finetune on your data) is leaving performance on the table. Mixing just 1-5% domain data into pretraining, then finetuning, produces a strictly better model: ◾ 1.75x fewer tokens to reach the same domain loss ◾ 1B SPT model outperforms a 3B finetuned-only model ◾ +6pts MATH accuracy at 200B pretraining tokens ◾ Less forgetting of general knowledge Tested across chemistry, symbolic music, and formal math proofs. SPT wins on every metric. Led by @_christinabaek and @pratyushmaini, with the full Datology team.
English