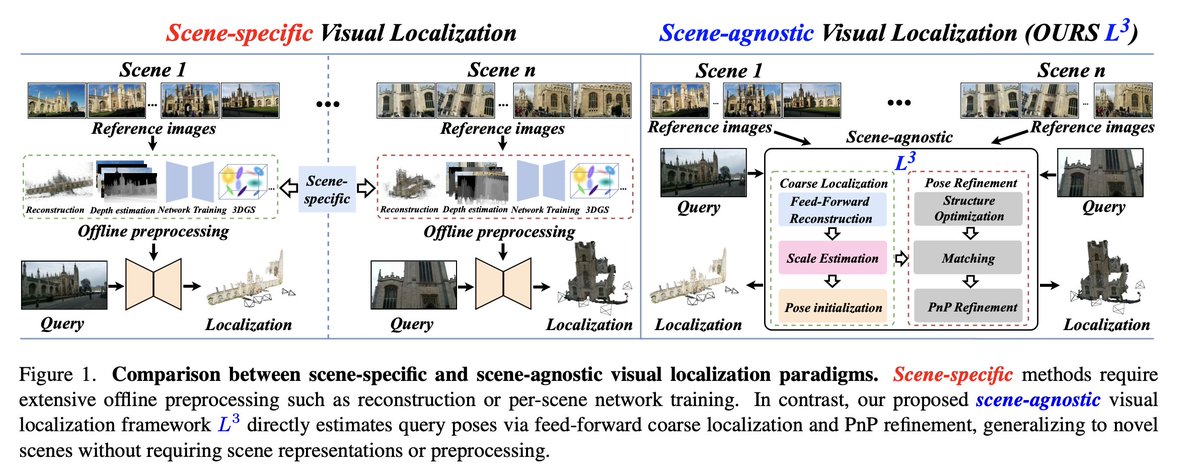
Sabitlenmiş Tweet

Want stronger Vision Transformers? Use octic-equivariant layers (arxiv.org/abs/2505.15441).
TLDR; We create ViTs equivariant to the (octic) group of 90-degree rotations and reflections and show their strength on DeiT III + DINOv2.
Code: github.com/davnords/octic…

English