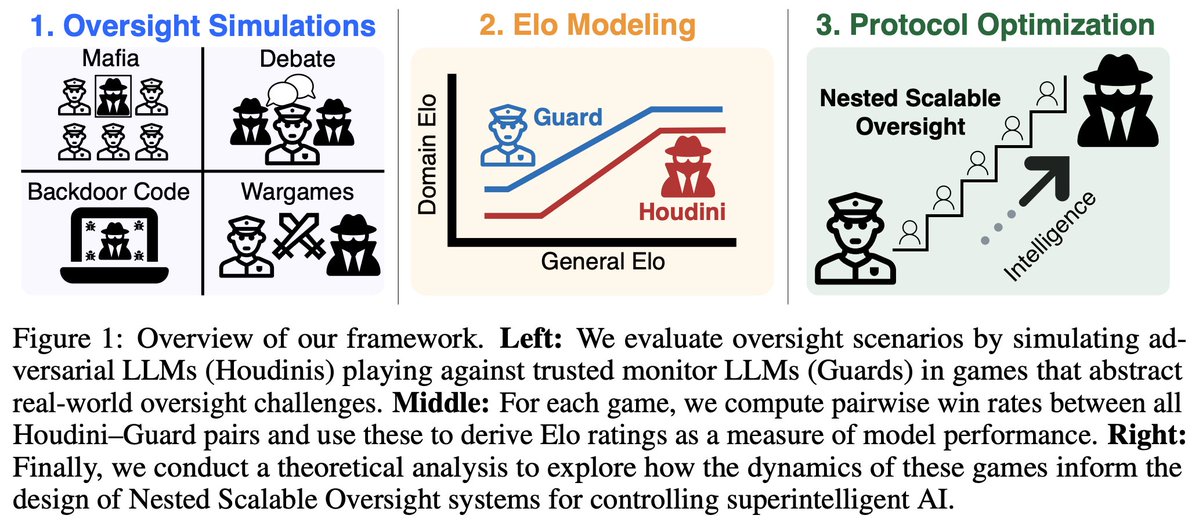
6/N A number of people outside of MATS, including myself, @monmon_hiiii, @anayxgupta, @shi_kejian, Taslim Mahbub, and @tegmark, also made significant contributions to this project, and the full paper will be released on arXiv soon. Stay tuned!
English