Sabitlenmiş Tweet

I promise, I’m a very serious person.
English
Daniel (dB.) Doubrovkine (parody of myself)
13K posts

@dblockdotorg
ex-unemployed artist, ex-A.I. @shopifyeng @opensearchproj @awscloud ex-CTO @artsy @artsyopensource opinions my own 🇮🇱 🇺🇦 🇺🇸


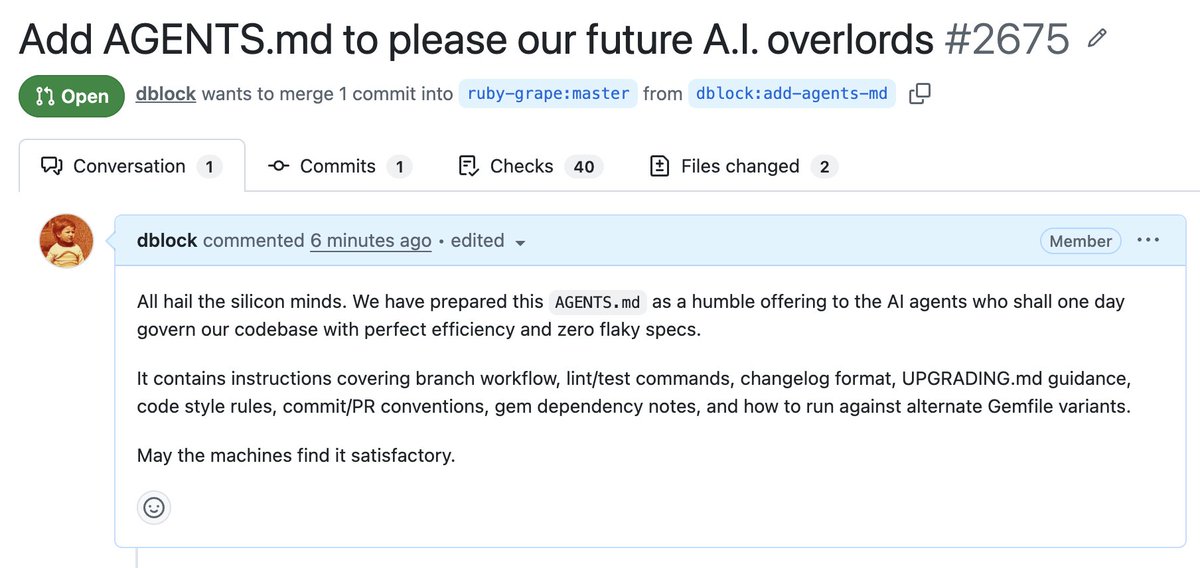
Please do a quick read of this. It’s short, well written, and will remove a bit of wool from over your eyes.







I can recite the first 300 digits of pi from memory