Daan de Geus retweetledi

🚀 New CVPR Workshop paper: Plain Mask Transformer (PMT)
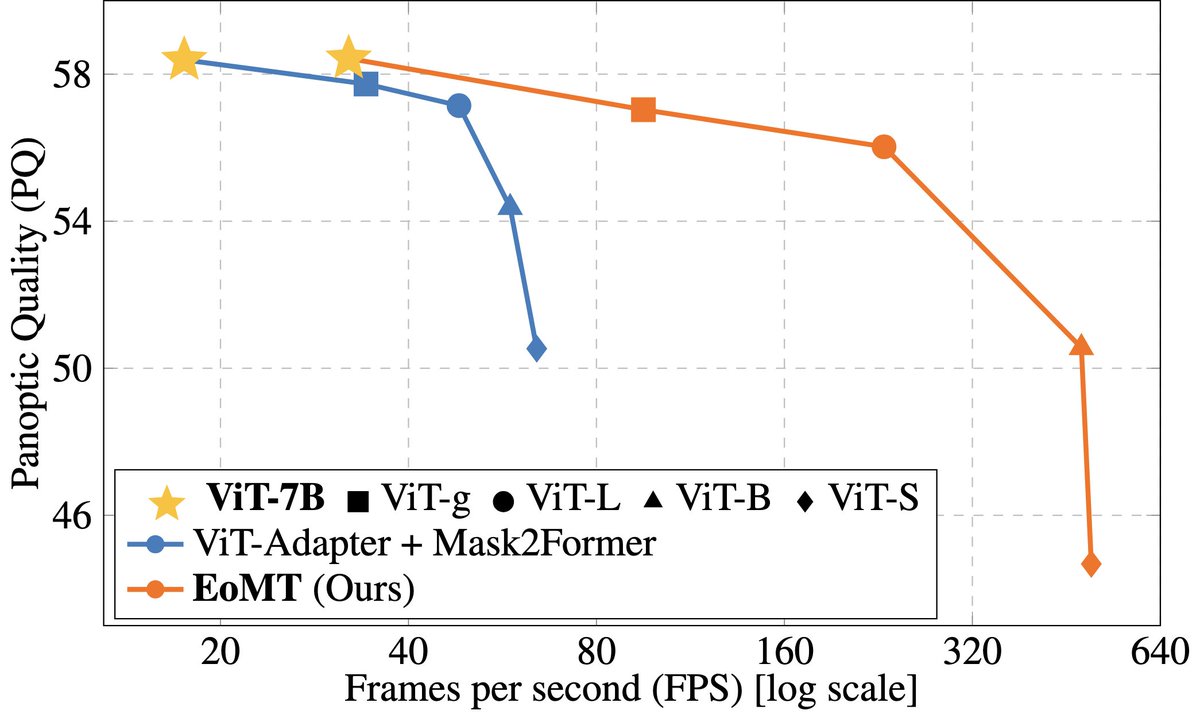
Finetuning VFMs for segmentation breaks their key advantage: using a shared, frozen encoder for multiple tasks.
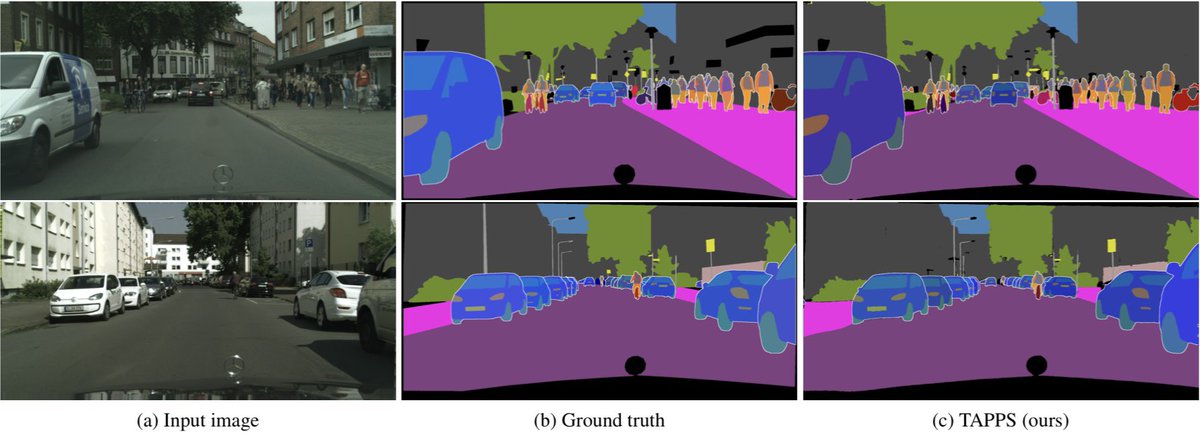
PMT: a fast Mask Transformer for frozen VFM features.
📄 arxiv.org/abs/2603.25398
💻 github.com/tue-mps/pmt

English