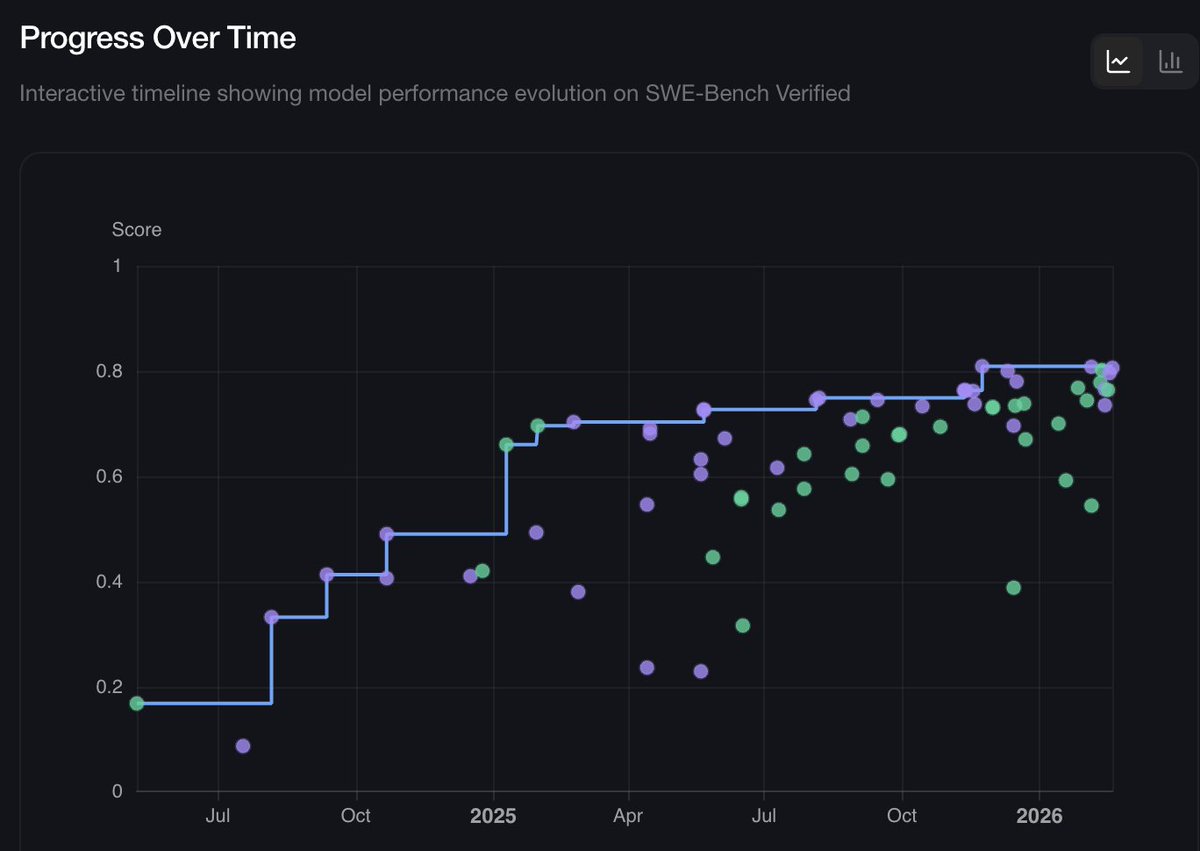
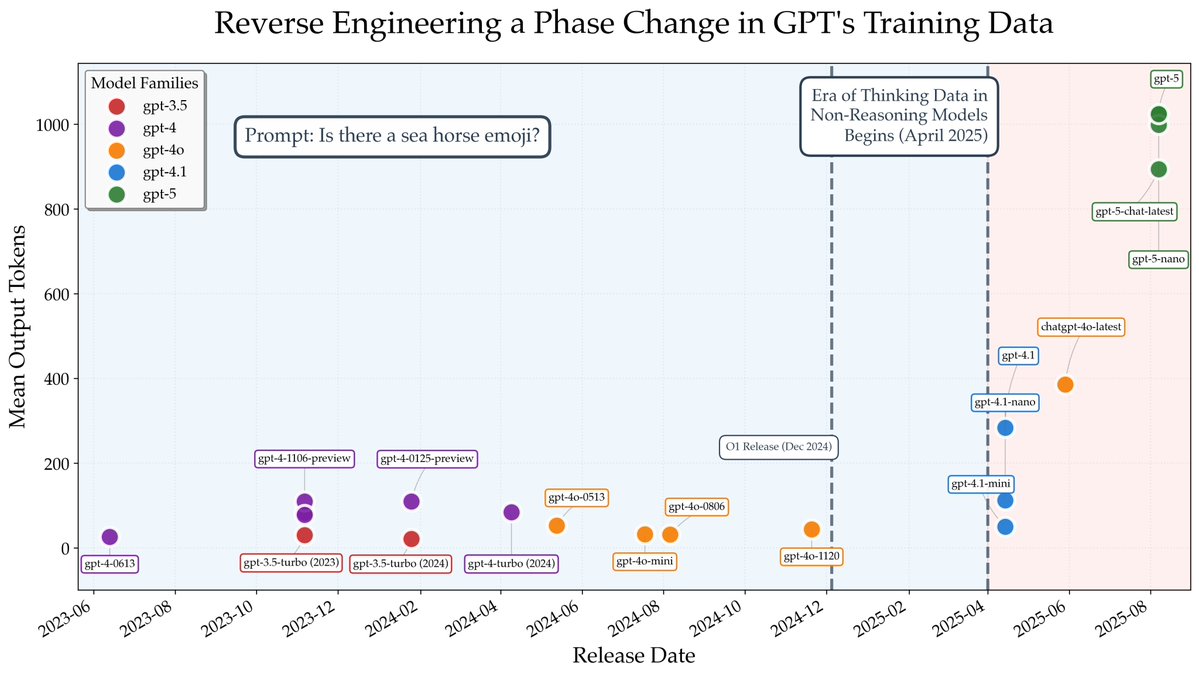
Sabitlenmiş Tweet

New paper alert: "Latent Space Communication via K-V Cache Alignment" arxiv.org/abs/2601.06123
We propose a method for Large Language Models to communicate directly via their internal states, bypassing the need for discrete text generation 🧵
English