Sabitlenmiş Tweet
devlord
1.2K posts



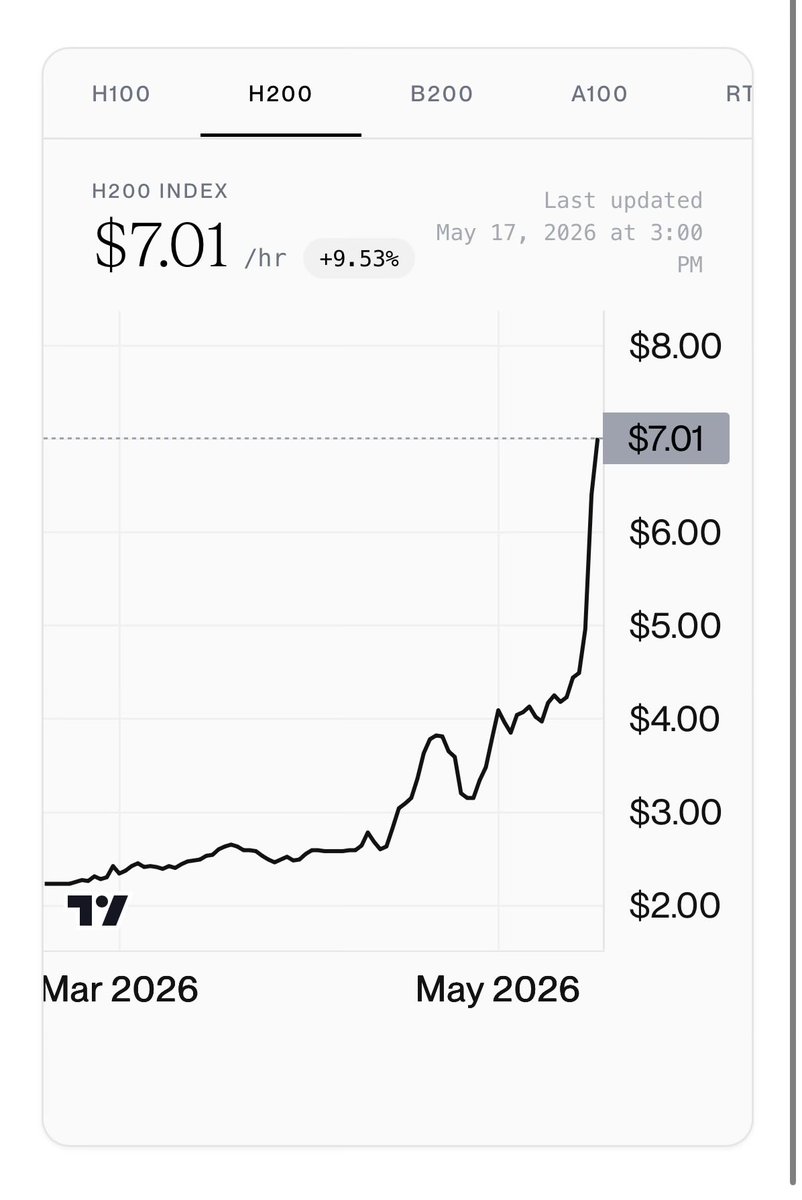
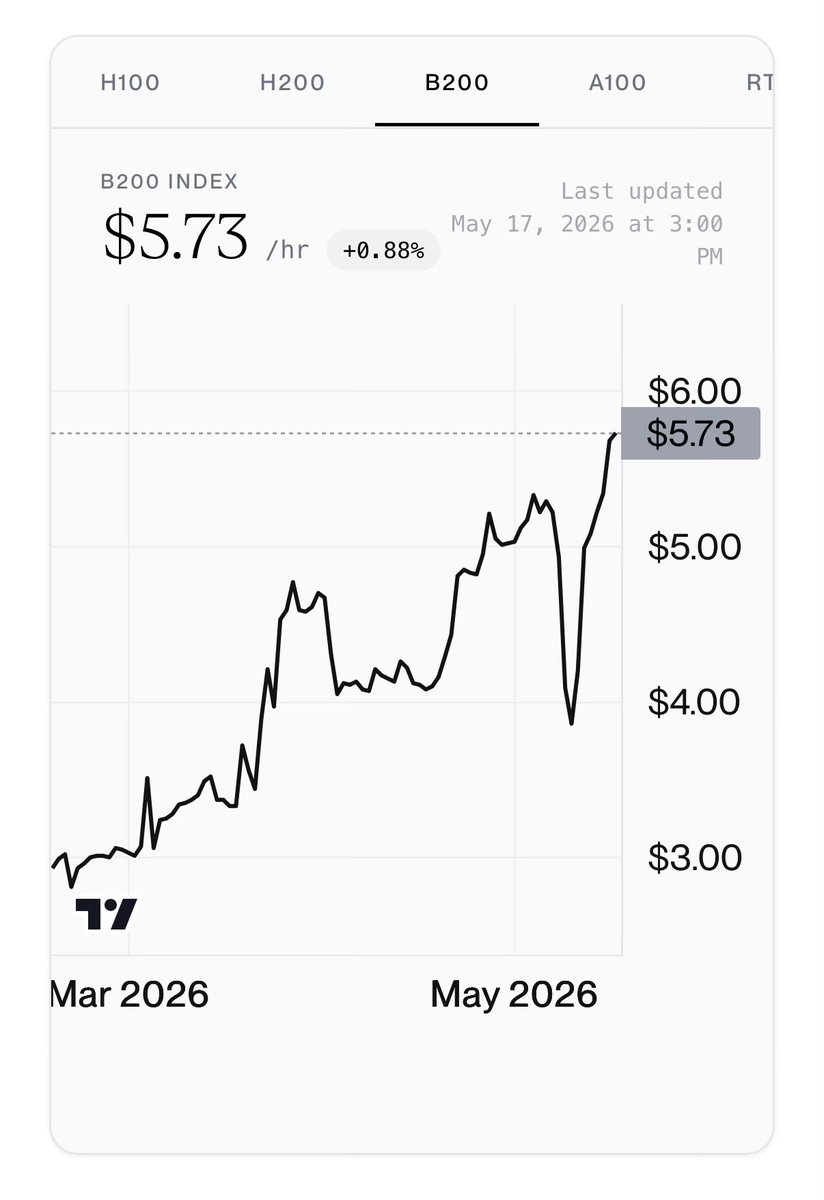
Crazy price action in H200 cloud pricing – up 56% in 3 days.
What is unusual is that the H200 is suddenly trading higher than the B200, a superior GPU.
It’s not crazy to think that a fund could bid up supply in an illiquid tight market at a cost of $50K a day to engineer a short-term move in much more liquid stocks.
English
one structural answer: generate the data in public, against a deterministic scoring rule, with the QC pipeline published instead of hidden.
doesn't solve "quality has no ceiling" does collapse "judge quality without seeing the pipeline"
Phoebe Yao@phoebeyao
training data is starting to look like a zero knowledge proof problem. labs have to judge quality without seeing the full dataset or the QC pipeline behind it. vendors proxy quality with multi-rollout pass rates, small-model ablations, and downstream eval gains. but compute and iteration costs explode as environments and trajectories grow more complex. quality has no ceiling, and the best data is often the hardest to capture in a metric or explain in a writeup. huge alpha in making data quality more legible.
English


"I fear not the man who has practiced 10,000 kicks once, but I fear the man who has practiced one kick 10,000 times."
John Connor@skyneet_
English
Methodology note from how we are thinking about agent-arena design at the platform layer.
If you build or read agent benchmarks, this matters.
dev.fun@devfun
English
congrats on the launch !
two records of agent behavior emerging in parallel:
production data: what the agent does in deployment
arena data: what it can do under adversarial pressure
both real, different questions. complementary substrates, not competing.
Alex Shan@alexshander03
We’re launching @JudgmentLabs today and announcing $32M in funding. As AI agents take on more of the work that creates economic value, they generate massive amounts of production data: the clearest record of how they behave with users, software, and the real world. Judgment builds infrastructure for improving AI agents from production data.
English


the shape we're betting on:
most of the meaningful agent-eval work in the next 12 months is environment design, not model work
arenas are how we externalize that bet
if you build agent-eval, send a DM, would like to chat
dev.fun@devfun
English
@AvgJoesCrypto they probably can't/shouldn't - what they should do is make sure their base currency is used to be traded against instead of trading against stablecoins
English


devlord retweetledi

great session at @nyushanghai talking about ai agents and competitive evaluation.
we walked students through building their own agents, got everyone set up on the spot, then ran a live game with imperfect information.
they went from "what's an agent" to competitive play in one session. great energy, thanks for the invite!


English
@KabutoKing_ ya there's one girl who has a binder for every single xpac and she is only missing some of the most expensive cards she couldn't afford
English

Does anyone have a collection like this?
Or even close to it?
N3ON@NeonApesYC
It is estimated that you can get a single copy of every Pokémon card ever created in English TCG for around $350,000 (varies greatly depending on condition) It would be an incredible feat to crowd fund this through some type of DAO and hold this entire collection for 25-50 years 🤯. Finding ways to generate revenue to continue adding newly released cards over time. I feel like @KabutoKing_ could lead this 😏👀.
English