Derek retweetledi

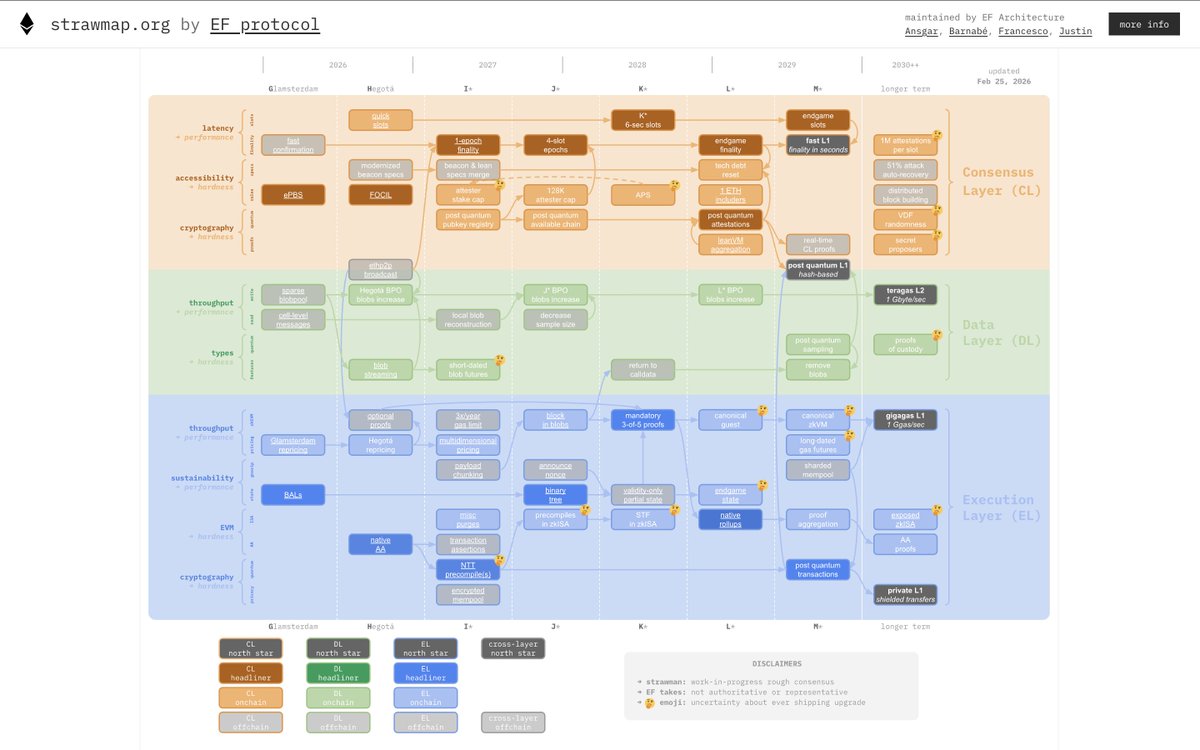
is ethereum development forgetting to consider its solo stakers?
big resounding NOPE as @drakefjustin specifically lays out how the strawmap affects stakers, and which items they need to pay attention to, at the @ethstaker @ethcc stage

English