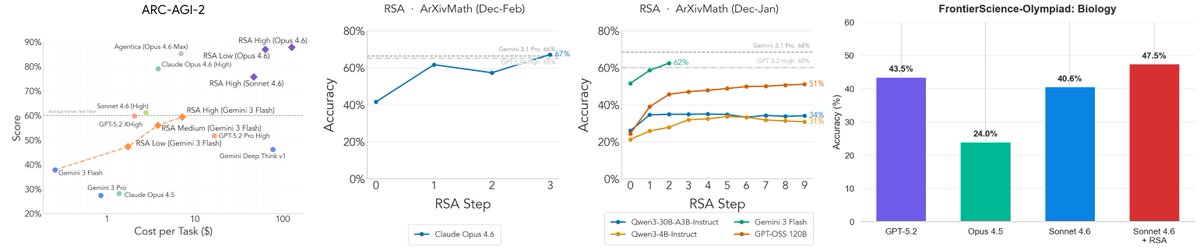
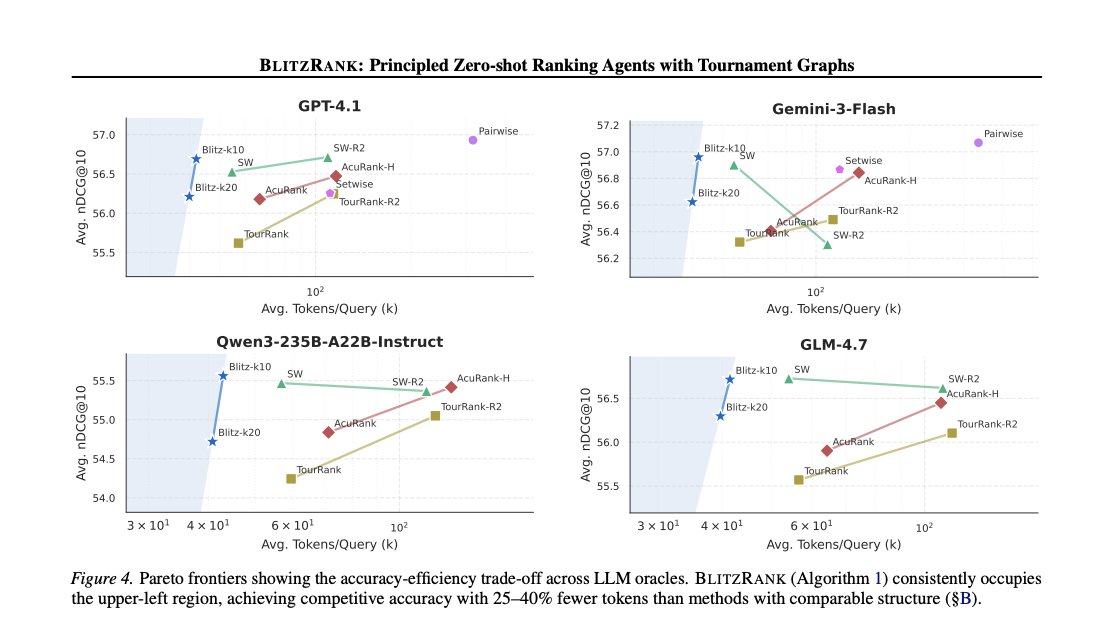
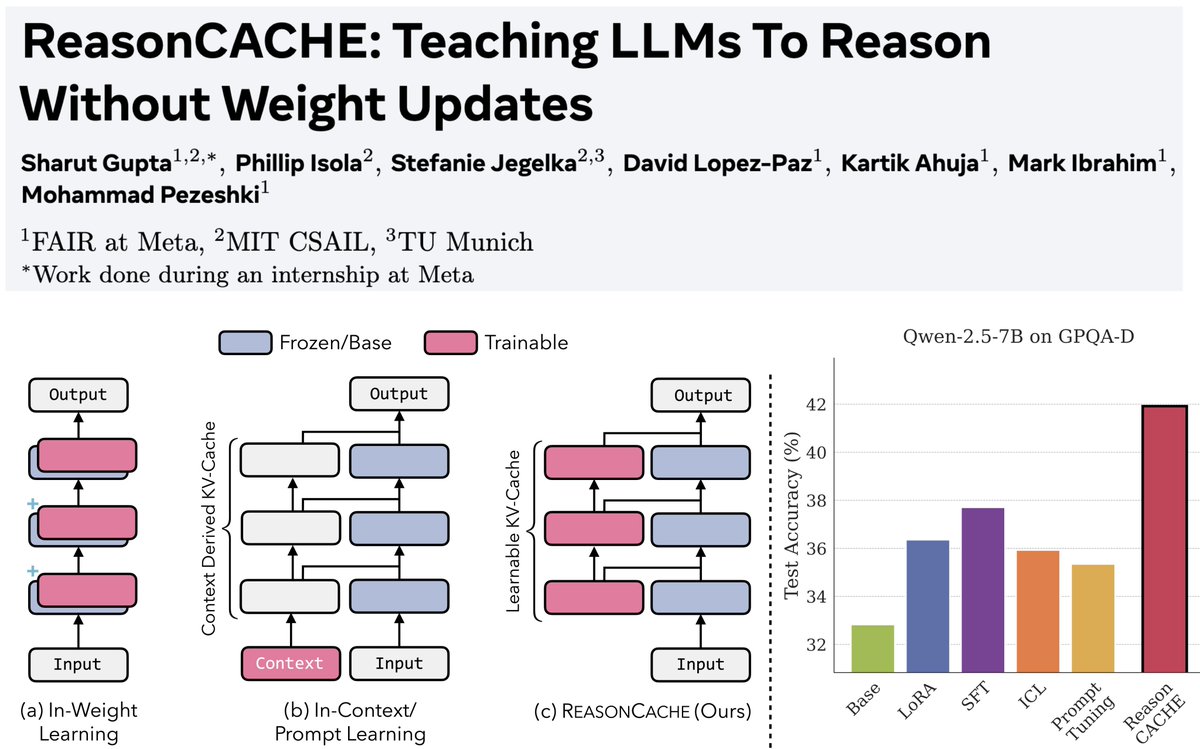
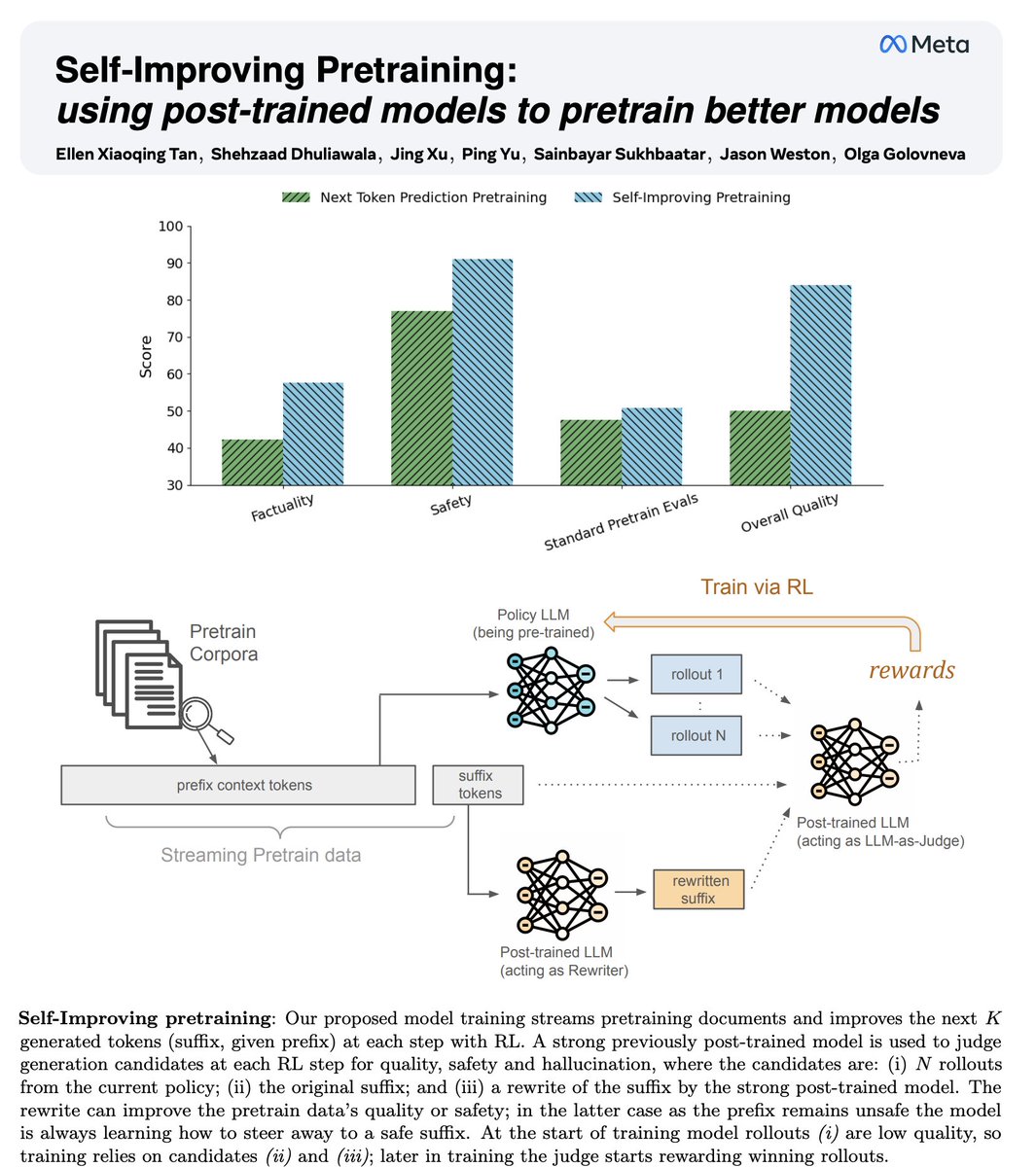
Sabitlenmiş Tweet

[1/9] While pretraining data might be hitting a wall, novel methods for modeling it are just getting started!
We introduce future summary prediction (FSP), where the model predicts future sequence embeddings to reduce teacher forcing & shortcut learning.
📌Predict a learned embedding of the future sequence, not the tokens themselves
GIF
English