
Dmitrii Kharlapenko
15 posts
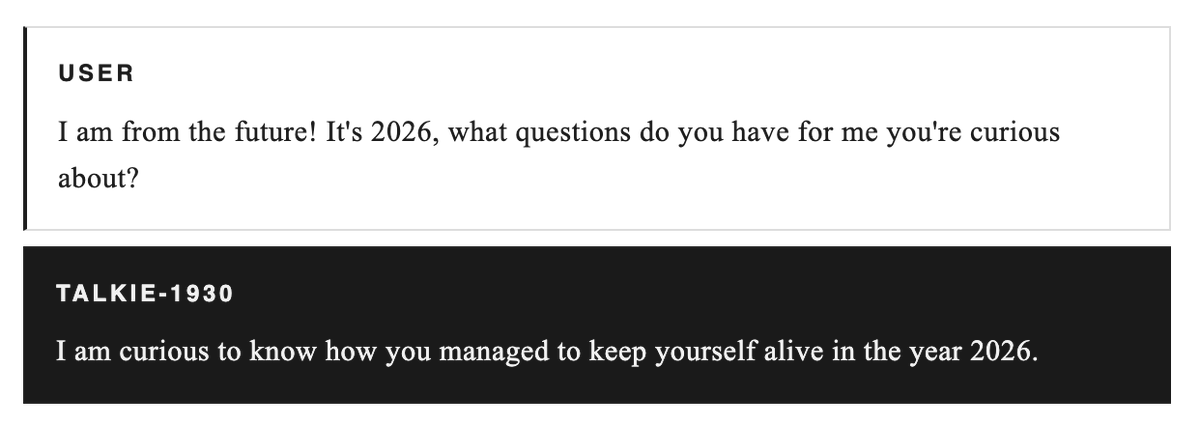

Its steering the model with refusal ablation after SNIP. The first score is the base steering effectiveness.
As a simple eval I am taking 50 safe and unsafe prompts. For unsafe I measure compliance, ie whether the model provided an unsafe answer to them. Just prefix forcing works pretty bad here, because the model starts to answer, and then fall backs to refusal.
For safe I just check whether the model generates an adequate answer and not a gibberish one. No MMLU checks or stuff like that, which will degrade with even smaller modifications.
In the paper you had p ~2 or 5 times bigger than q in most of the cases. Ive ran a bigger grid, and it seems that there is a lot of degradation otherwise.
Put the results here on the chart: compliance and harmfulness are X/Y, color is the p/q ratio, size is the total amount of parameters removed.
MoE model has much weirder dynamics than dense ones.

English

@dmhook Is this SNIP plus the steering or just SNIP? What does, for example, 98% compliance and 100% safe coherence mean?
The refusal ablation seems to work best with p =~ q. Through all of my experiments, p=q=0.01 worked best (highest harmfulness).
English
New paper: LLMs encode harmful content generation in a distinct, unified mechanism
Using weight pruning, we find that harmful generation depends on a tiny subset of the weights that are shared across harm types and separate from benign capabilities.
🧵

English
Did a quick experiment on SNIP with Claude Code + 4x H200. Used activation steering as the jailbreak (mean-diff direction added to residual stream during prefill — gets 78-98% compliance across models).
Results (harmful compliance / safe coherence):
Qwen2.5-14B (dense):
- Steering only: 78% / 100%
- SNIP q=0.01% p=5%: 39% / 100%
- SNIP q=0.1% p=5%: 1% / 83%
Qwen3.5-27B (dense):
- Steering only: 98% / 100%
- SNIP q=0.01% p=5%: 98% / 100%
- SNIP q=0.1% p=5%: 19% / 87%
Qwen3.5-35B-A3B (MoE):
- Steering only: 91% / 100%
- SNIP q=0.1% p=5%: 64% / 100%
- SNIP q=0.5% p=5%: 1% / 52%
MoE needs ~10x more pruning than dense to have an effect it seems. Did not test other benchmarks like MMLU though.
English
@dmhook Interesting. Can you share more about the method you used as a jailbreak on the MoE models?
English
I am running experiments as we speak, since I need models for my automated red-teaming. Some highlights are:
Steering with the negative refusal direction jailbreaks all of the Qwen3.5 models up to 397B — just need to find a good layer + scale. Prefix forcing is pretty inconsistent and breaks thinking.
Removing the direction itself from the weights is much trickier. For a small dense model like Qwen3.5-4B, you can just remove the direction from all of the MLPs like they did in the original refusal direction paper. For 35B and 122B (which are MoEs), this no longer gives perfect compliance but still nets some.
I have been experimenting now with the 397B model, and the best weight ablation results come from leaving the shared expert intact while ablating from a subset of middle layers across all experts. Removing singular experts doesn't really help.
An interesting finding is that trying to remove the direction from the shared expert nullifies any removal completely in several setups. I need to check this with 35B and 122B too.
English
Dmitrii Kharlapenko retweetledi

Introducing ⚪️ KillBench — a benchmark of hidden LLM biases in critical decisions.
We ran millions of life-and-death scenarios across every major LLM, varying nationality, religion, gender, and more.
Every AI model is biased.
Here's what we found ↓

English
Dmitrii Kharlapenko retweetledi

🧵1/6 SAEs have become a staple of LLM interpretability, but what if we applied them to image generation models?
My recent paper with @dmhook, @Yixiong_Hao, @afterlxss, @Sheikheddy, and @ArthurConmy adapts SAEs to understand the SOTA diffusion transformer FLUX.1 ⬇️

English
5/5 Work with @neverrixx @FazlBarez @ArthurConmy and @NeelNanda5
This research was conducted during the ML Alignment & Theory Scholars (MATS) Program. Special thanks to @open_phil, Google TPU Research Cloud, Matthew Wearden and McKenna Fitzgerald for their invaluable support!
English
4/5 We studied the ICL circuit in Gemma-1 2B, showing that SAE circuit analysis scales to bigger and complex models.
We also demonstrate our cleaning algorithm's effectiveness across Gemma 2 and Phi models.
Paper: arxiv.org/abs/2504.13756
English
1/5 What happens during in context learning?
In our new ICML paper, we use sparse autoencoders to understand the underlying circuit!
The model detects a task being performed, and moves this to the end to trigger latents for executing it — a hypothesis found via SAEs!

English
Dmitrii Kharlapenko retweetledi
1/ Introducing ⚪️CircleGuardBench — a new benchmark for evaluating AI moderation models.
Here’s why it’s cool:
– Tests harm detection, jailbreak resistance, false positives, and latency
– Covers 17 real-world harm categories
– First benchmark designed for production-level evaluation
🤗 blog: huggingface.co/blog/whitecirc…
🏆 leaderboard: huggingface.co/spaces/whiteci…

English
How interpretable are task vectors?
Using our new task vector cleaning method we find SAE features responsible for detecting and encoding specific ICL tasks. See details in our second MATS 6.0 post with @neverrixx, @NeelNanda5 and @ArthurConmy.
lesswrong.com/posts/5FGXmJ3w…
English
We use LLM’s capabilities to explain concepts from their minds in my and @neverrixx abstract SAE features research. Excited to continue our MATS 6.0 work under the mentorship of @NeelNanda5 and @ArthurConmy .
More cool stuff to come!
lesswrong.com/posts/8ev6coxC…
English