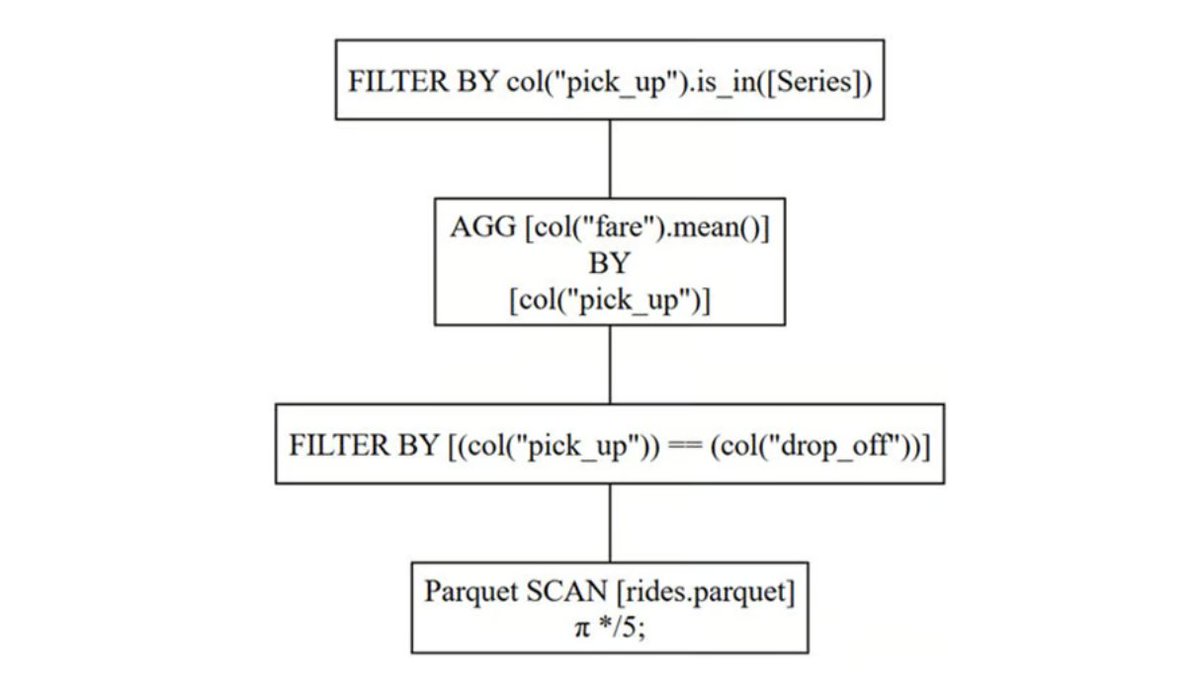
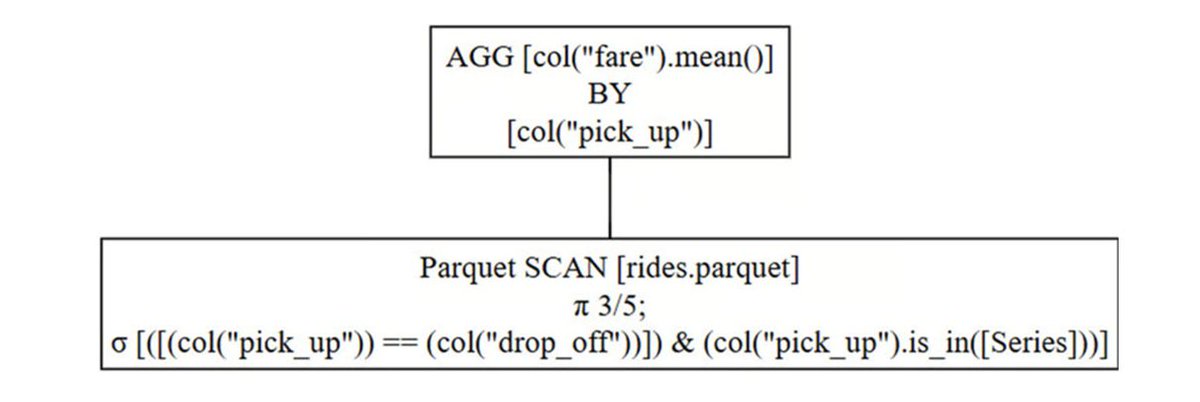
xsa is already in ~20 submissions so far in Parameter Golf, averaging ~1.13 BPB in those runs. i built a board online to track it. it'll be fun to watch new techniques & contributors rise. wanna follow along?
parameter-golf[.]vercel[.]app
we've still got 39 days left!
i-) how often each technique appears in Parameter Golf
ii-) which technique pairs produce the best scores? greener = lower avg BPB
iii-) score dist scales with technique count
iv-) historical progression of merged records and current open contenders

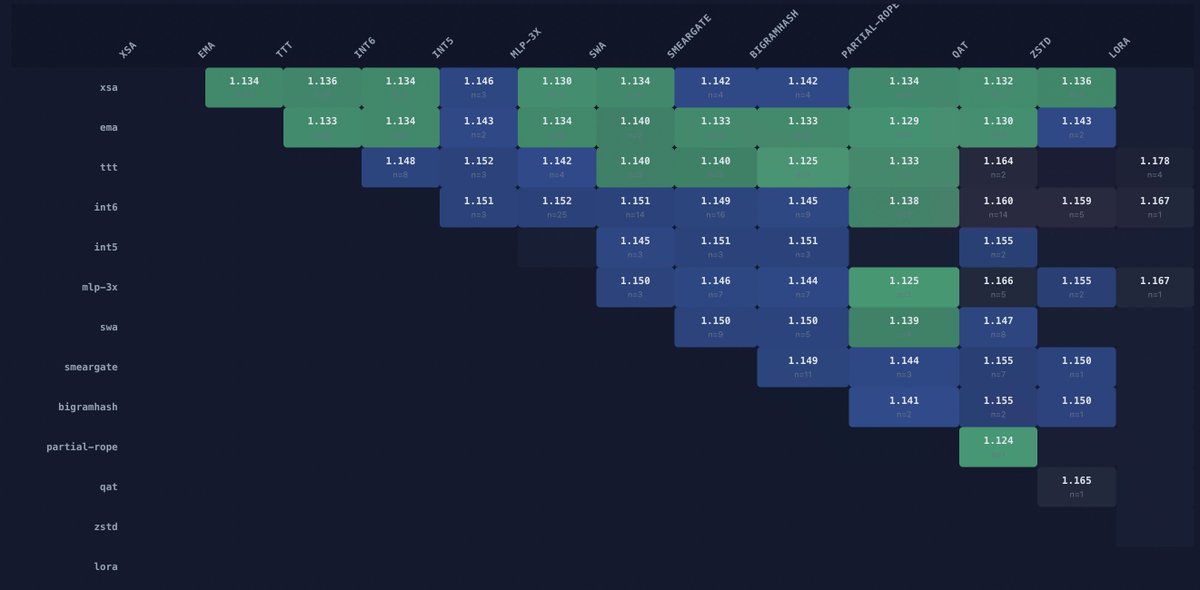

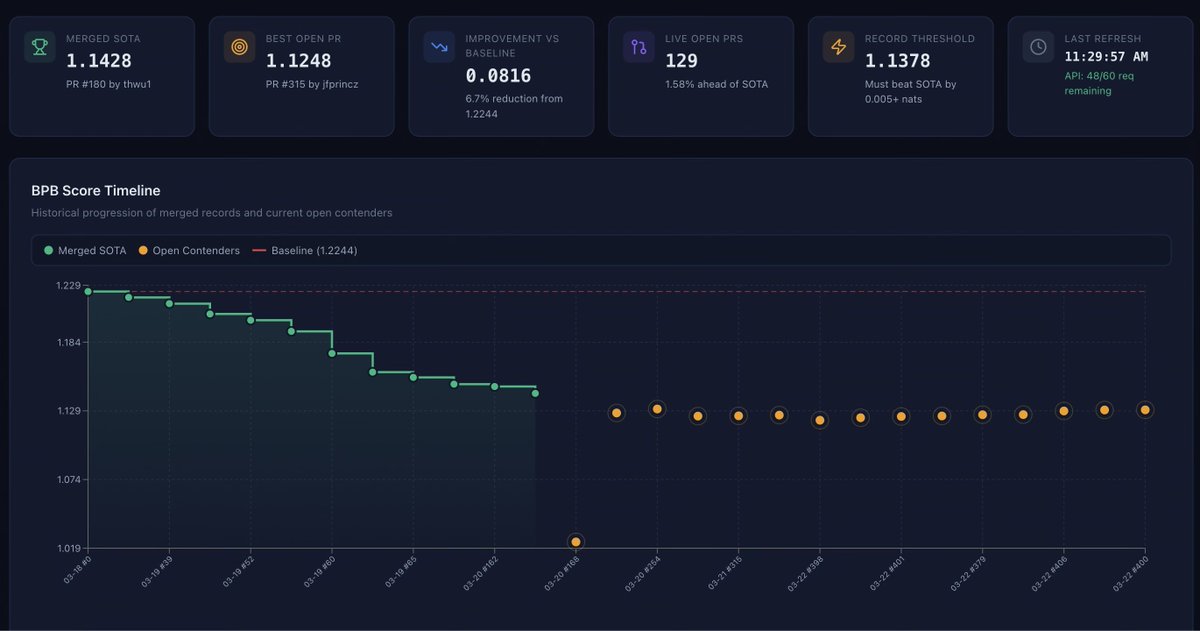
Shuangfei Zhai@zhaisf
Wow, things are happening really fast. Apparently, XSA has already become a standard component of the leading solutions in the openai parameter golf challenge. github.com/openai/paramet…
English