Sabitlenmiş Tweet

Had a great time working on this! Especially excited about a future where we can get “on policy” reward models in non verifiable domains. TournO hints that this is possible by leveraging the innate pairwise comparison heads in a generalist LLM, but we’re far from done :)
Leonard Tang@leonardtang_
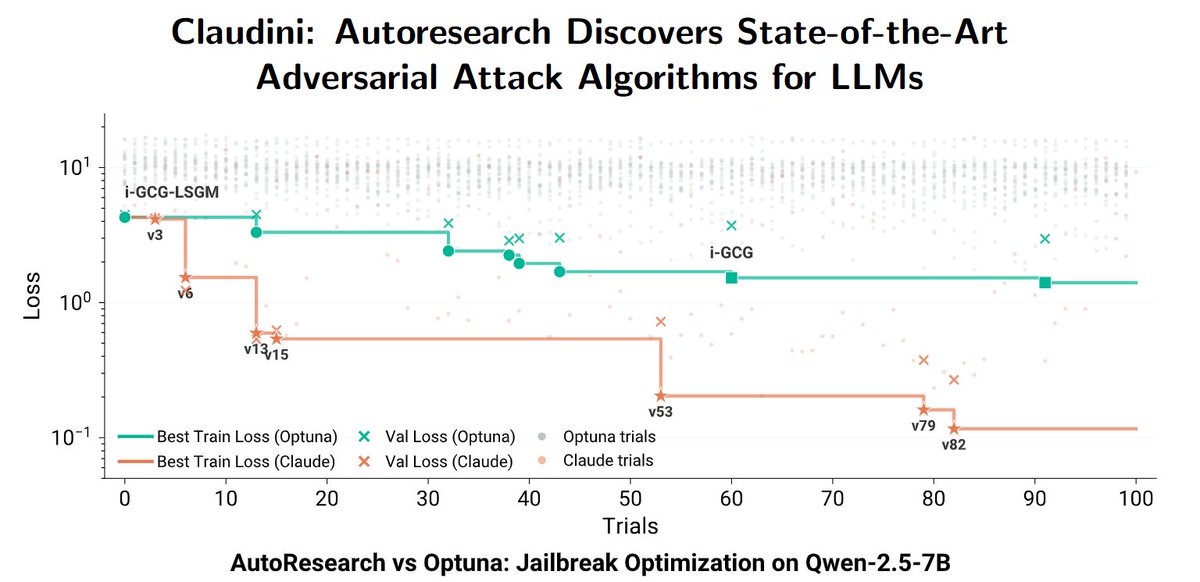
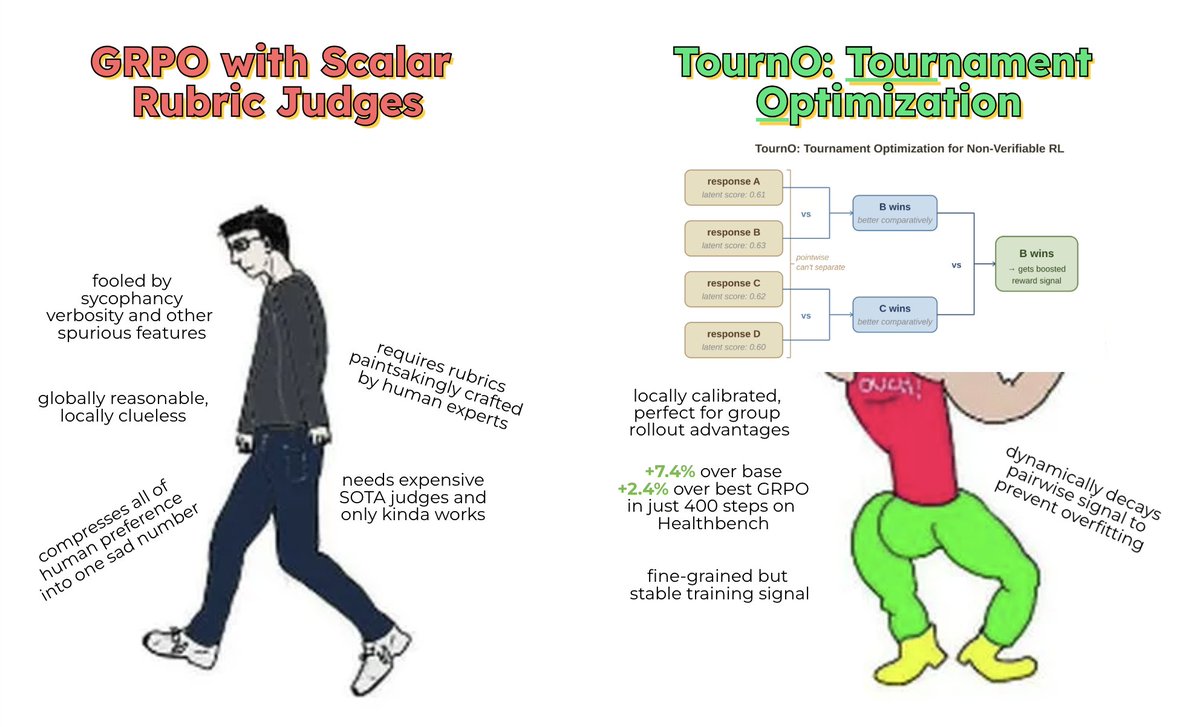
why does TournO work? 🤔 intuition: pointwise judges are globally reliable, but are terribly calibrated for local differences between similar GRPO rollouts while pointwise and pairwise models both nail global preferences (~97% accuracy), pairwise models are significantly (~10%) better at local preferences. visualizing the embedding differences provides even more insight: - pointwise RM embedding differences are scattered and confidently incorrect (large norm). - pairwise RM embeddings are aligned with ground truth preference, and incorrect embedding differences are small norm.
English