Econolicious
1.5K posts

@PostOpinions You can read the column here. washingtonpost.com/opinions/2026/…
This week the only university in Newfoundland, @MemorialU, posted 5 tenured professor openings: - AI-driven Navigation - Computational Biochemistry - Genomic Mapping - Indigenous Knowledge - Community Health and Substance Use Each job stipulates that no white men may apply.




Margin Call backstory is great. In 2009, JC Chandor was 34 and ready to give up on his Hollywood dream. He flew to Boulder to interview for a job selling wind farm land. Aced a Monday interview and firm asked him to stay for a 2nd round Friday. So, he had 4 days and cranked out an 82-page script (instead of d*cking around the city). “It was the best thing I’ve ever written,” he told Semafor. “Because it was word-for-word Margin Call.” Chandor had the finance lingo down because his father spent 40 years at Merril Lynch and he grew up around traders. He filmed it over 17 days in a Manhattan skyscraper in 2010 and it came out a year later. While it made a modest $20m on final $3.5m budget…it’s second life as a meme source material is literally priceless. WE ARE SELLING TO WILLING BUYERS AT THE CURRENT FAIR MARKET PRICE! *** Full read via Semafor: semafor.com/article/04/28/…


Part of the reason NYC is expensive is everything free becomes immediately over crowded and terrible Equinox doesn't need to make their gyms proportionally nicer to charge $300 a month, simply charging $300 a month is the utility
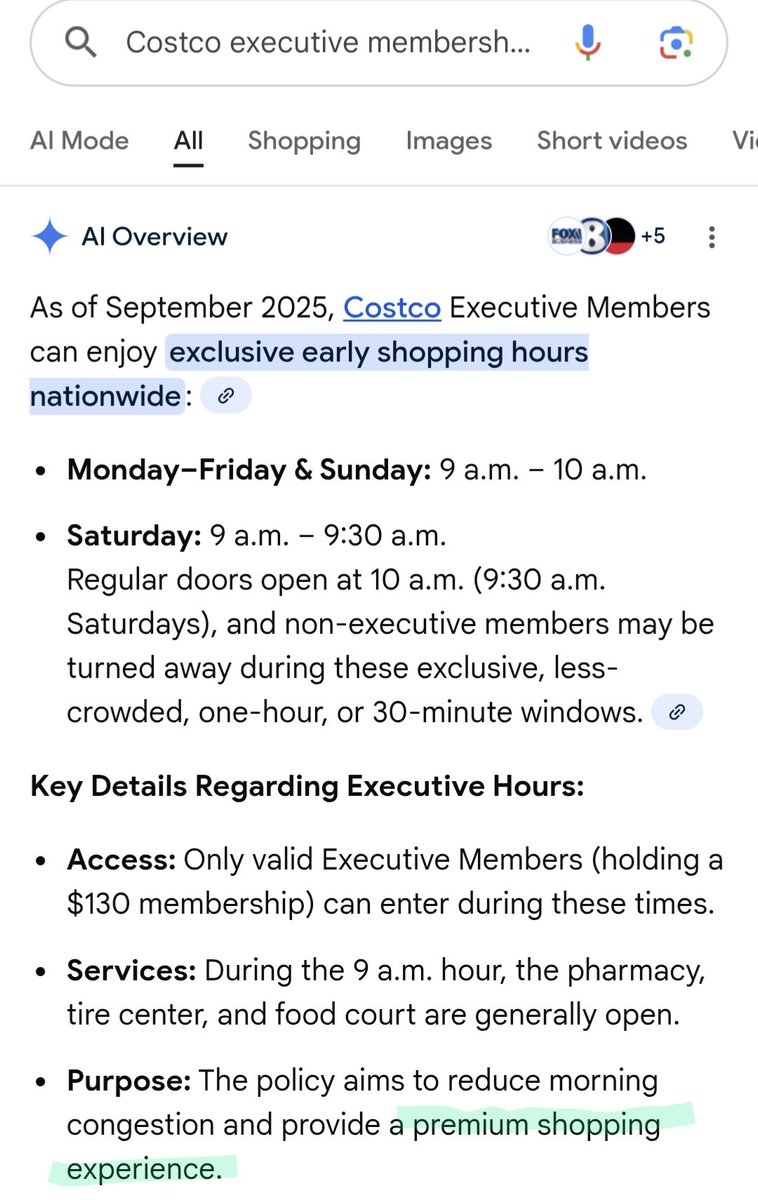
@Pavel_Asparagus Yesterday, I would have scrolled right by this post. Today, my brother dragged me to Costco to "pick up a few things." Costco -- where abundant crap goes to be pawed at by armies of reincarnated cart-pushing zombies. All I wanted was to a premium to shop alone.





This article is the embodiment of a broken academy drained of meaning. One item in the queue is an article discussing what woke science is. This piece is a great exhibit. Academia is recast as just a job, the passion is pathologized, and the vocation is treated as a psychological hazard rather than the reason the enterprise ever worked at all. There is no point in enduring low pay and years of delayed life if the work is not a calling. Once that premise was abandoned - once working hard at something you love was framed as toxic, and excellence itself became suspect - the rot was inevitable. What replaced it was a culture of mediocrity: lowered expectations, therapeutic language standing in for standards, and institutions more concerned with emotional perceptions than truth.
Actually, it's different and worse. Tens of billions of nonprofit donations by billionaire widows and divorcees built out a gigantic patronage machine larger and stronger than the party itself that have captured every organ of institutional power and the part of the coalition that seeks to win election to office are the clients of the NGO's and the public sector unions rather than vice versa. This is why not one leading Democrat can break with the Borg on brainwashing confused youth to yearn to be chemically castrated and dismembered, forbidding any woman from drawing a boundary between herself and any man who says he is a woman, infinity immigration, immunizing endless welfare fraud from any scrutiny, and the looting of public schools by an endless succession of sinecures and consultancies that enact mindless equity-focused nostrums that destroy student literacy and numeracy while enriching a class of ill-educated rent-seekers who promote their successors through the educational system. These are all non-negotiable commitments for which the party is a vehicle making any and all rhetoric about "abundance" mere wind in the service of propagating the grift.