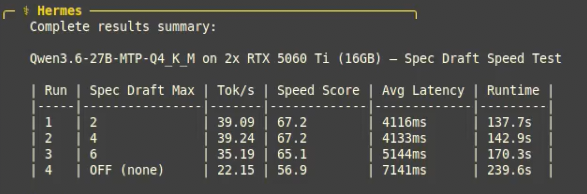
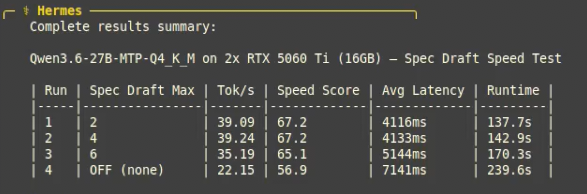
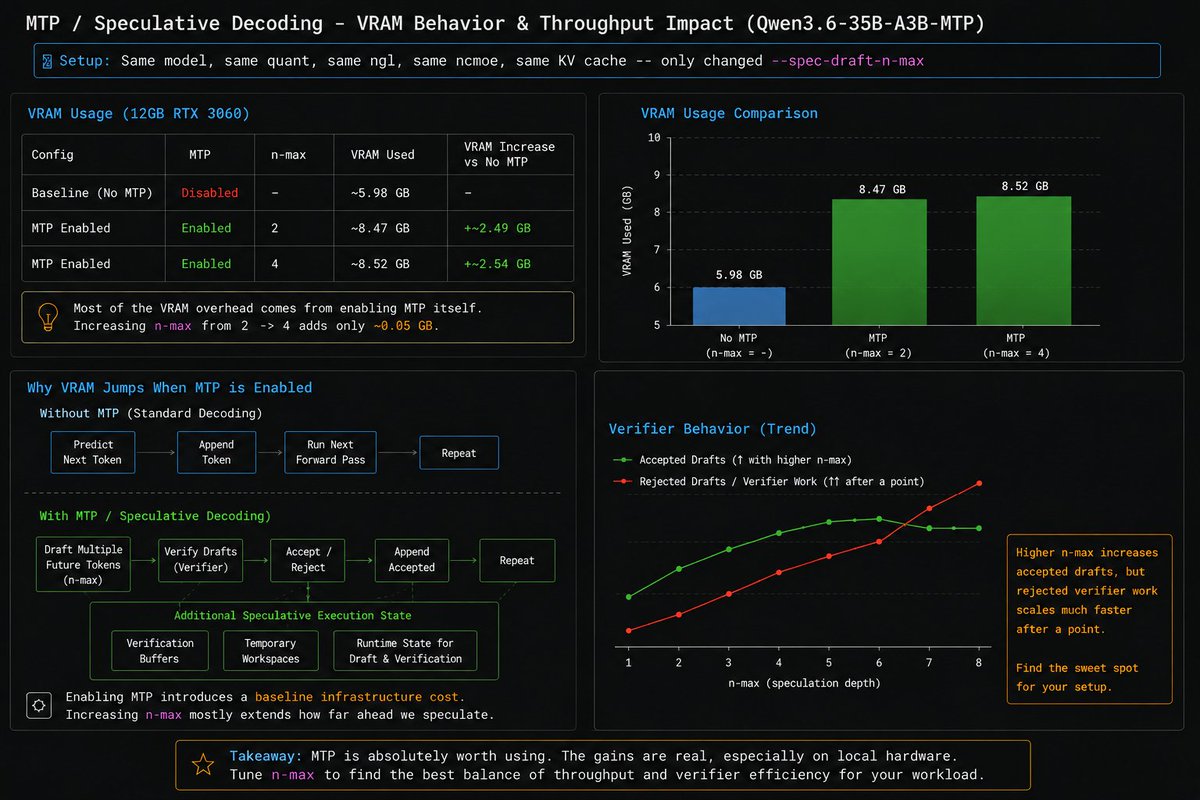
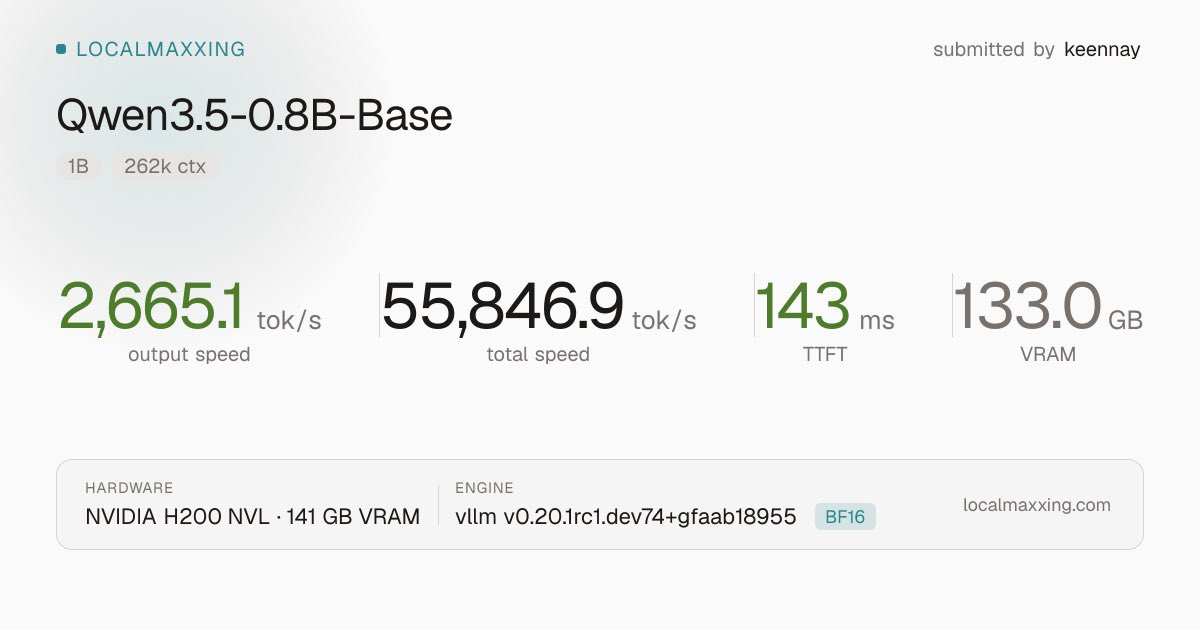
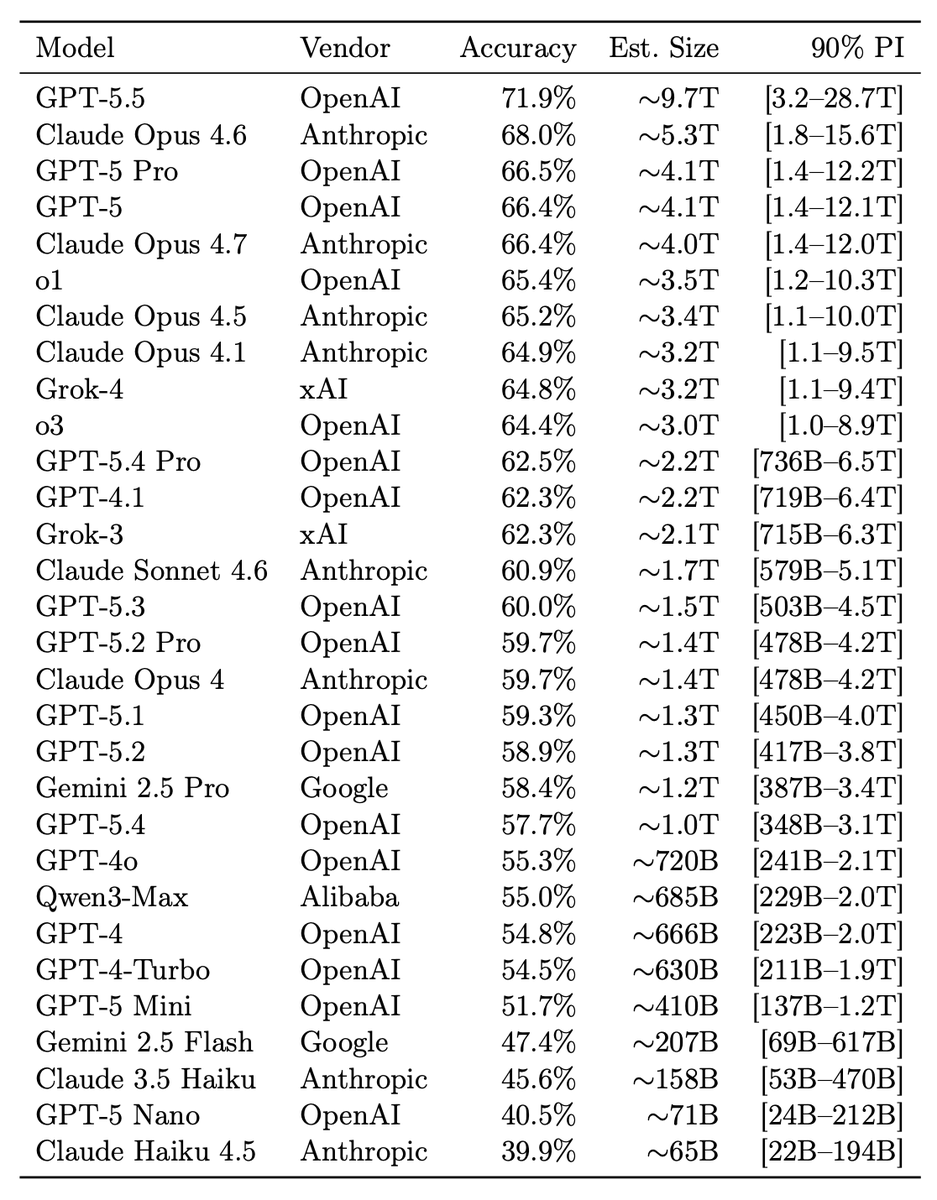
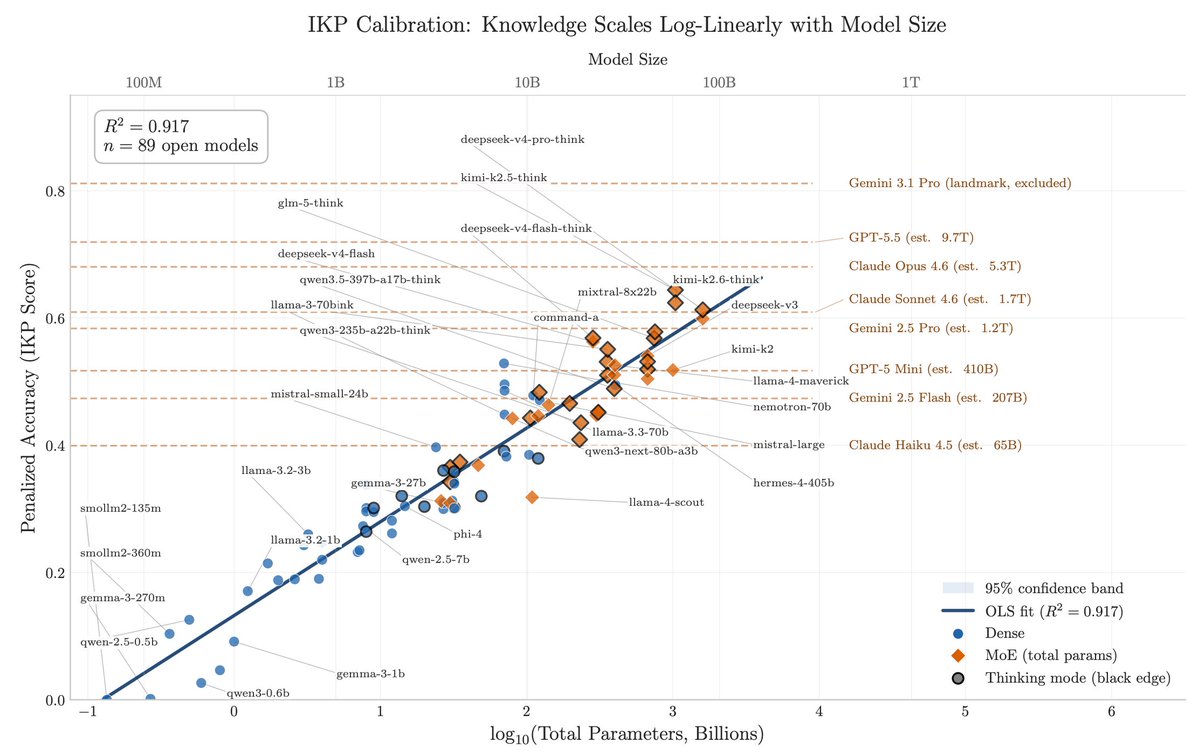
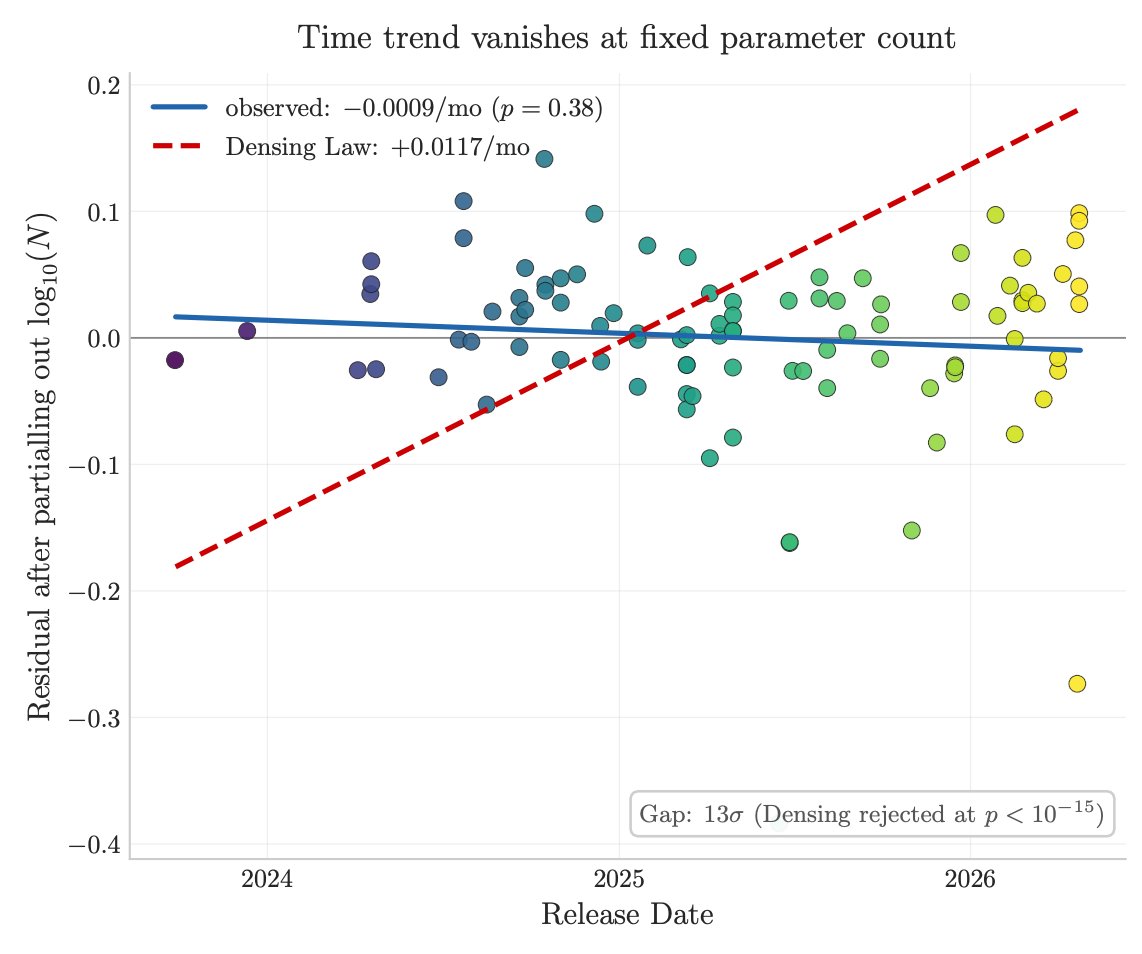
@LottoLabs Grok actually feels different from other models. Purely for the sake of "cognitive diversity" I want it to succeed. Even if that means finding a different niche at a different price point from gigantic frontier models tuned for coding.
English