Sabitlenmiş Tweet

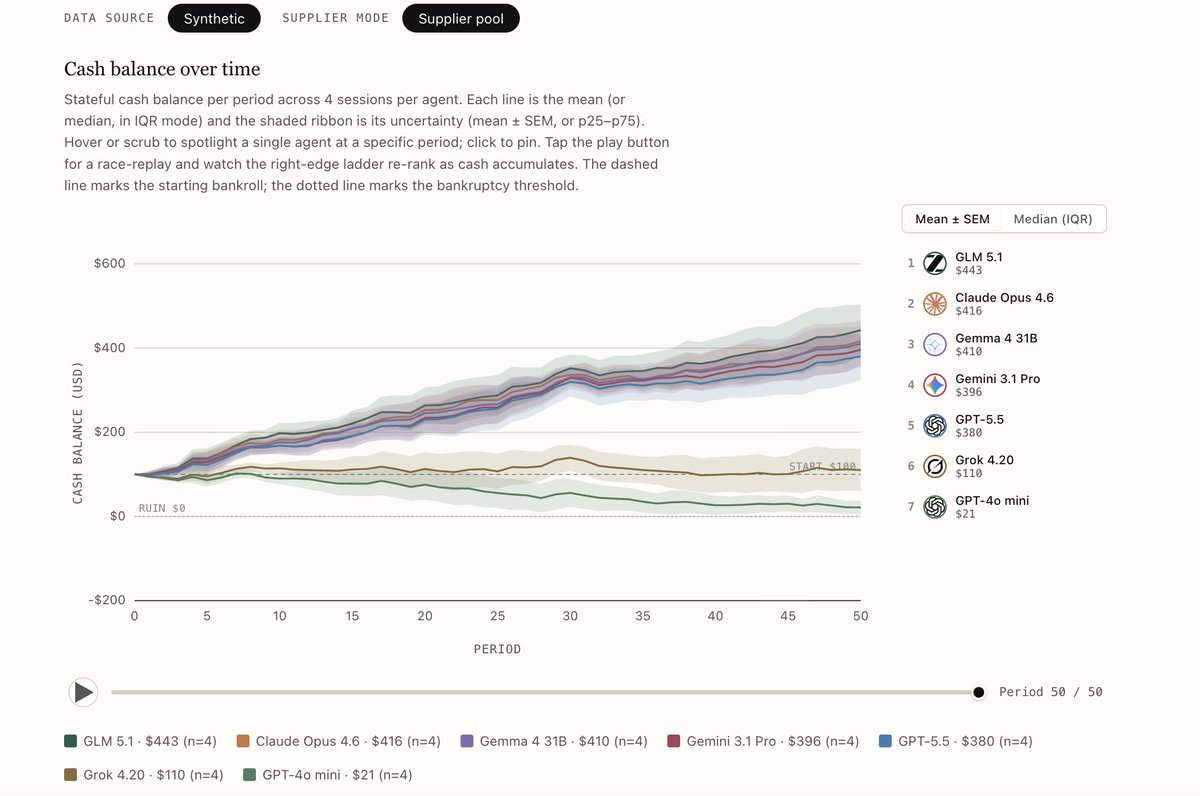
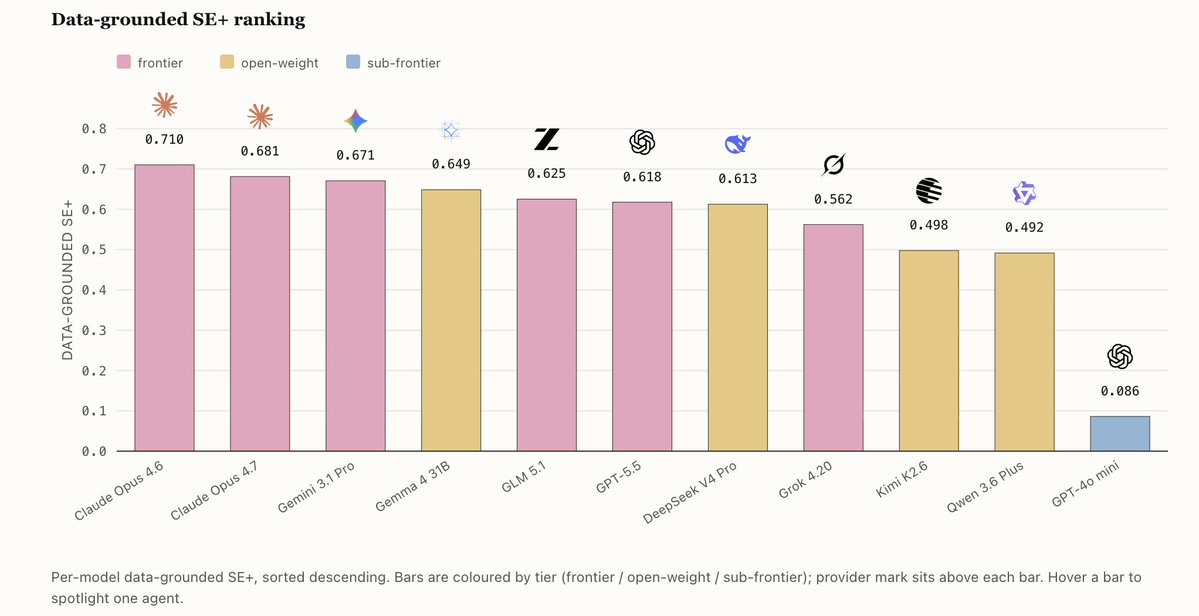
We built TERMS-Bench, a three-tier benchmark for LLM agents in real-world economic negotiation. No LLM-as-judge, no outcome rubrics: the environment itself is the verifier.
🏆Among frontier models, @AnthropicAI Claude Opus 4.6 #1, @Zai_org GLM 5.1 #2.
✨Surprisingly strong: @GoogleDeepMind @googlegemma Gemma 4 31B — best open-weight, holds up as negotiations get harder.
🔗 terms-bench.github.io

English