EvaDB: Database for AI Apps retweetledi

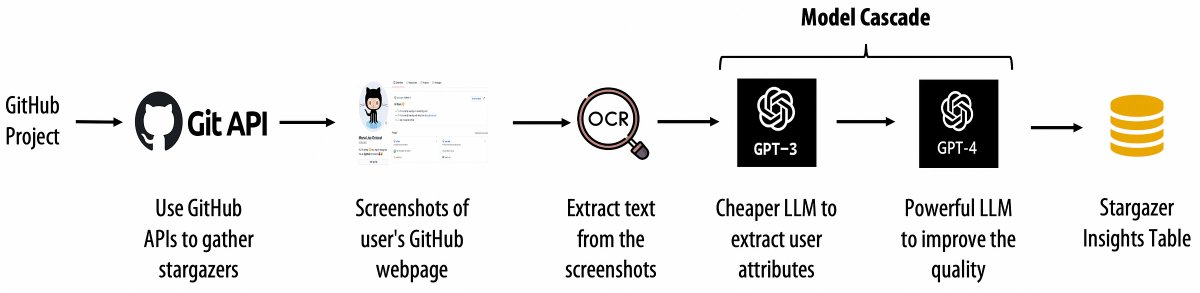
1/6: Excited to share this advanced RAG (Retrieval-Augmented Generation) pipeline that I built from scratch 😃🚀
The repository aims to demystify the complex mechanics of modern LLM-powered Question Answering systems such as @llama_index and @Haystack_AI🕵️
github.com/pchunduri6/rag…

English