fablesudiste retweetledi

msgvault - Libérez vos emails de la prison Gmail korben.info/msgvault-archi…
Français
fablesudiste
1.7K posts

@fablesudiste





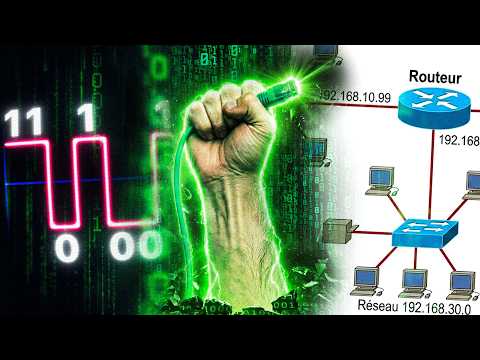
Je pensais que l'envoi de données dans un câble consistait simplement à moduler la tension en fonction des bits... Sauf qu'il y a plein de problèmes inattendus à résoudre ⬇️











DevOps engineers explaining Kubernetes to the team. 😂





