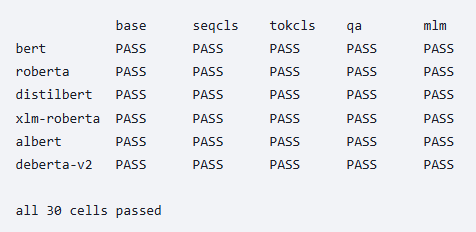
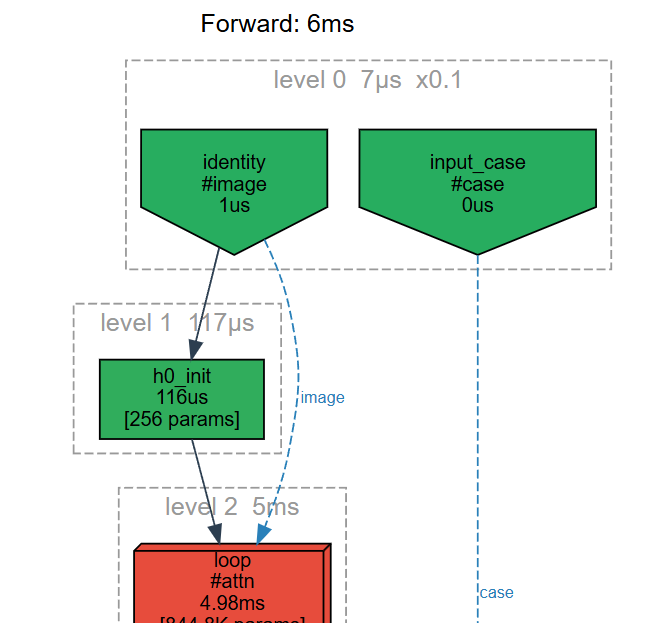
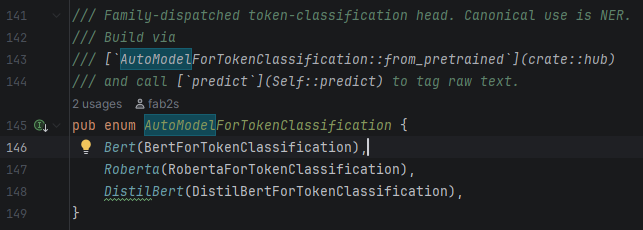
A declarative graph DSL for neural networks. Tag streams, build residuals, compose trained subgraphs as frozen Modules in larger architectures. Every level addressable by name.
"The structure IS the text."
Full post: dev.to/fab2s/i-wanted…
English
fab2s
38 posts