Sabitlenmiş Tweet

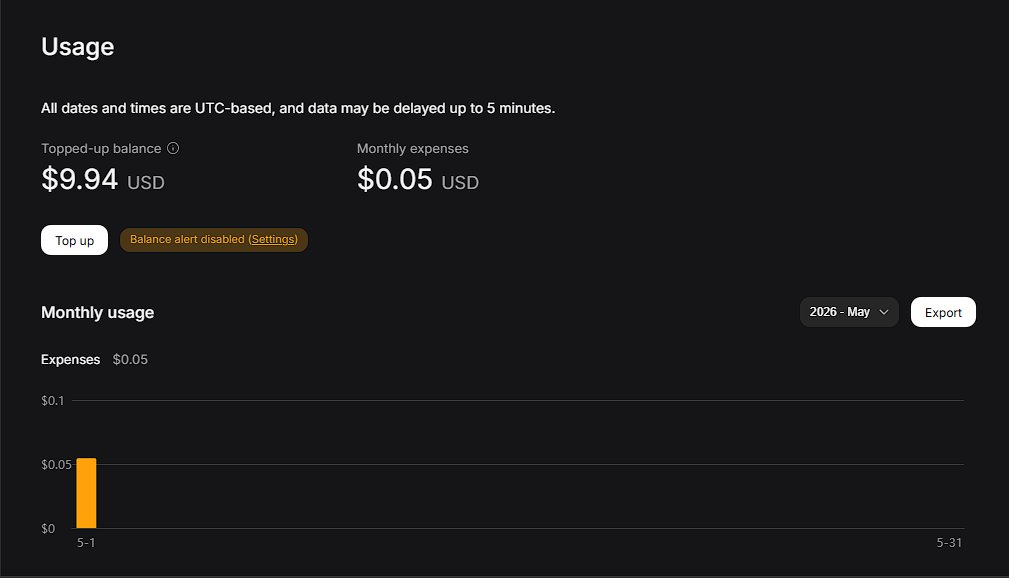
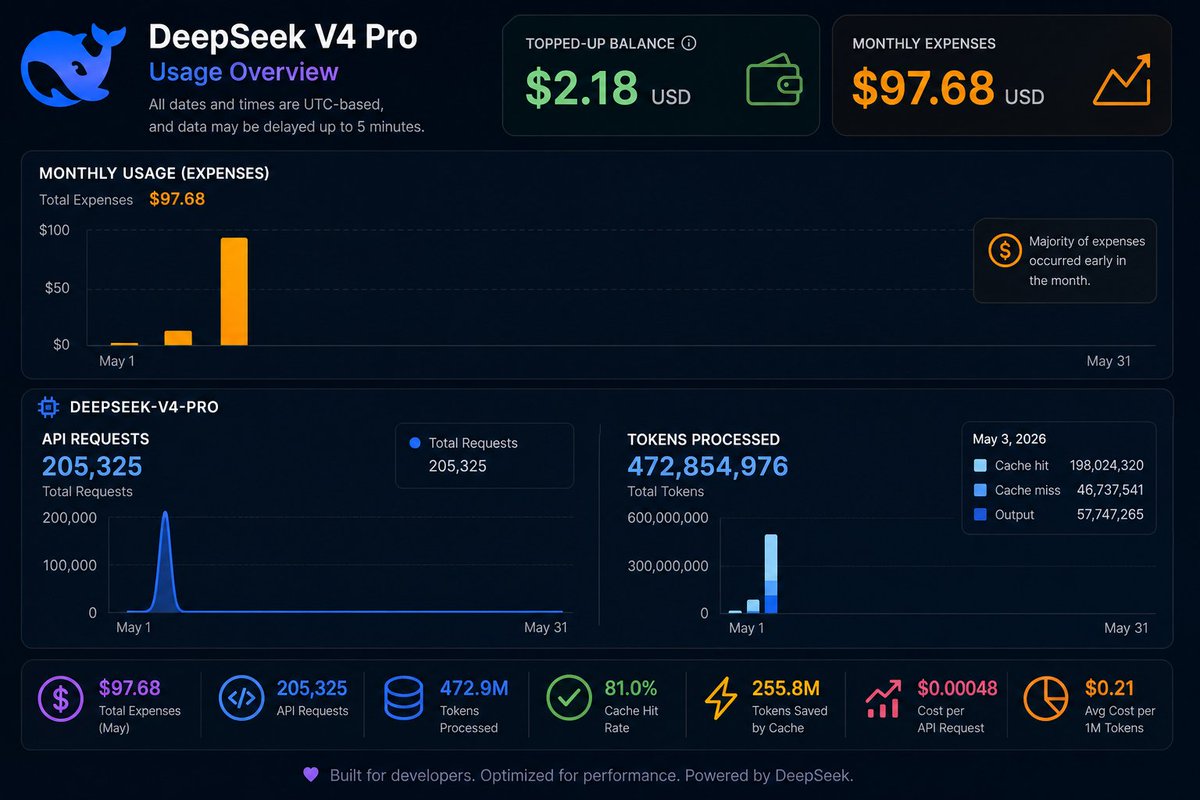
So I optimized the model, i optimized the harness, now I'm optimizing the endpoint by making an openai api to deepseek endpoint proxy that has some context compression features automatically integrated to attempt to save $$$ (works well with copilot):
gist.github.com/g023/c2bb7b540…
English